실전 스프링 부트 책을 읽고 정리한 내용입니다.
Chapter1. 스프링 부트 시작하기
스프링 부트 핵심 기능
전통적인 스프링만으로 웹 애플리케이션을 개발한다면 다음과 같은 과정을 먼저 수행해야 한다.
- 스프링 MVC 의존 관계를 추가하고 메이븐이나 그레이들 프로젝트 생성
- 스프링 MVC Dispatcher Servlet 설정
- 애플리케이션 컴포넌트를 WAR 파일로 패키징
- WAR 파일을 아파치 톰캣같은 서블릿 컨테이너에 배포
스프링 부트를 사용하면 개발자는 애플리케이션에 필요한 의존 관계를 명시(1번 단계)하기만 하면 되고 나머지는 스프링 부트가 알아서 해준다.
롬북
롬북은 여러 가지 애너테이션을 사용해서 POJO(Plain Old Java Object) 객체의 생성자, getter, setter, toString 등을 자동으로 만들어 준다.
-
레코드: 자바 14에 도입된 개념이다. 레코드는 필드의 타입과 이름만 명시해서 정의하는 불변 데이터 클래스이다. 자바 컴파일러가 레코드의 equals, hashCode, toString 메서드를 자동으로 만들어준다. 또한 private final 필드를 생성하고 getter 메서드와 퍼블릭 생성자도 자동으로 만들어준다. 롬북 같은 서드파티 라이브러리를 사용하고 싶지 않다면 자바 레코드 사용을 검토해보는 것도 좋다.
- toString
- 기본 메소드는
클래스이름@16진수해시코드형태의 문자열 반환 - 재정의하여 간결하면서 사람이 읽기 쉬운 형태의 유익한 정보를 반환하는 것이 좋다.
- 기본 메소드는
- hashCode
- 기본 메소드는
객체의 고유한 정수 값반환 - String의 경우 char 원소의 주소값을 각각 해시값으로 만든 것을 반환하기 때문에 동일한 문자열의 해시코드는 동일하다.
- 기본 메소드는
- equals
- 기본 메소드는
객체의 주소 값이 같은지 비교하여 boolean 반환==연산도 주소 값 비교
- String의 경우 hashCode 메소드와 동일한 방식으로 검사 진행
- 기본 메소드는
스프링 부트 프로젝트 구조
서블릿 기반 웹 애플리케이션은 아파치 톰캣이나 제티 같은 서블릿 컨테이너 위에서만 실행할 수 있다. 스프링 부트는 이런 서블릿 컨테이너를 웹 애플리케이션 안에 내장해서 별도의 서블릿 컨테이너를 실행하지 않고도 스프링 부트 애플리케이션이 내장 서블릿 컨테이너 위에서 실행할 수 있게 만들었다. 그래서 main() 메서드를 통해 스프링 부트 애플리케이션을 실행하면 스프링 부트는 내장된 기본 서블릿 컨테이너인 톰캣 서버를 시작하고 그 위에서 웹 애플리케이션을 실행한다.
@SpringBootApplication:@EnableAutoConfiguration,@ComponentScan,@SpringBootConfiguration3개의 애너테이션을 포함@EnableAutoConfiguration: 애플리케이션 클래스패스에 있는 JAR 파일을 바탕으로 애플리케이션을 자동으로 구성해주는 스프링 부트 자동 구성 기능을 활성화한다.@ComponentScan: 애플리케이션에 있는 스프링 컴포넌트를 탐색해서 찾아낸다. 스프링 컴포넌트는@Component,@Bean등이 붙어 있는 자바 빈으로서 스프링으로 관리한다.@ComponentScan애너테이션이 붙어 있으면 스프링 부트 애플리케이션은 애너테이션에서 지정한 디렉터리와 그 하위 디렉터리 모두 탐색해서 스프링 컴포넌트를 찾아내고, 라이프사이클을 관리한다.@ComponentScan은 루트 패키지에서 시작해서 모든 하위 패키지까지 탐색한다는 점을 기억하자. 그래서 루트 패키지와 그 하위 패키지에 존재하지 않는 컴포넌트는 탐색 대상에서 포함되지 못하며 스프링 부트가 관리하지 못한다.@SpringBootConfiguration: 스프링 부트 애플리케이션 설정을 담당하는 클래스에 이 애너테이션을 붙인다. 내부적으로@Configuration을 포함하고 있어서 이 설정 클래스는 스프링 부트 컴포넌트 탐색으로 발견되며 이 클래스 안에서 정의된 빈도 스프링으로 발견해 로딩된다. 결과적으로 이러한 빈을 통해 애플리케이션 설정 과정에 참여한다.
ApplicationContext
대부분의 자바 어플리케이션은 다수의 객체로 구성된다. 이 객체들은 서로 협력하므로 의존 관계가 생겨난다. 객체 생성 및 상호 의존 관계를 효과적으로 관리하기 위해 스프링 의존 관계 주입(Dependency Injection)을 사용한다. 의존 관계 주입 또는 제어의 역전(Inversion Of Control)을 통해 빈 생성 시 필요한 의존 관계를 스프링이 주입해준다. 빈은 applicationContext.xml 같은 XML 파일로 정의할 수도 있고 @Configuration이 붙어 있는 클래스로 정의할 수도 있다. 스프링은 이렇게 정의된 내용을 바탕으로 빈을 생성해서 스프링 IoC 컨테이너에 담아두고 관리한다.
JAR 파일 구조
크게 보면 네 부분으로 나눌 수 있다.
- META-INF: 실행할 JAR 파일에 대한 핵심 정보를 담고 있는 MANIFEST.MF 파일이 들어 있다. 파일 안에는 두 가지 주요 파라미터인 Main-Class와 Start-Class가 들어 있다.
- 스프링 부트 로더 컴포넌트: 실행 가능한 파일을 로딩하는데 사용하는 여러 가지 로더 구현체가 들어 있다.
- BOOT-INF/classes: 컴파일된 모든 애플리케이션 클래스가 들어 있다.
- BOOT-INF/lib: 의존 관계로 지정한 라이브러리들이 들어 있다.
그 외에 다음과 같은 파일들이 있다.
- classpath.idx 파일: 클래스로더가 로딩해야 하는 순서대로 정렬된 의존 관게 목록이 들어 있다.
- layer.idx 파일: 도커나 OCI 이미지 생성 시 논리적 계층으로 JAR를 분할하는 데 사용된다.
스프링 부트 애플리케이션 종료
아무런 추가 설정 없이 기본 설정만으로 스프링 부트 애플리케이션을 종료하면 즉시 종료되며, 종료할 때 처리 중인 요청의 처리 완료가 보장되지 않는다. 이는 사용자 경험에 악영향을 미치므로, 애플리케이션에 종료 명령이 실행되면 더 이상의 요청은 받지 않되, 이미 처리 중인 요청은 완료를 보장하는 안전 종료(graceful shutdown) 설정이 필요하다.
# 안전 종료 설정
spring:
lifecycle:
timeout-per-shutdown-phase: 1m # 처리 중인 요청이 완료될 때까지 기다려주는 타임아웃 설정
server:
shutdown: graceful
스프링 부트 스타트업 이벤트
스프링 프레임워크의 이벤트 관리 체계는 이벤트 발행자(publisher)와 이벤트 구독자(subscriber) 분리를 강조한다. 프레임워크에 내장된 빌트인 이벤트를 사용하는 것뿐만 아니라 개발자가 직접 커스텀 이벤트를 만들어 사용할 수도 있다.
애플리케이션 시작 및 초기화 과정에서 사용할 수 있는 빌트인 이벤트는 다음과 같다.
- ApplicationStartingEvent: 애플리케이션이 시작되고 리스너(listener)가 등록되면 발행된다. 스프링 부트의 LoggingSystme은 이 이벤트를 사용해서 애플리케이션 초기화 단계에 들어가기 전에 필요한 작업을 수행한다.
- ApplicationEnvironmentPreparedEvent: 애플리케이션이 시작되고 Environment가 준비되어 검사하고 수정할 수 있게 되면 발행된다. 스프링 부트는 내부적으로 이 이벤트를 사용해서 MessageConverter, ConversionService, Jackson 초기화 등 여러 서비스의 사전 초기화를 진행한다.
- ApplicationContextInitializedEvent: ApplicationContext가 준비되고 ApplicationContextInitializers가 실행되면 발행된다. 하지만 아직 아무런 빈도 로딩되지 않는다. 빈이 스프링 컨테이너에 로딩되어 초기화되기 전에 어떤 작업을 수행해야 할 때 이 이벤트를 사용하면 된다.
- ApplicationPreparedEvent: ApplicationContext가 준비되고 빈이 로딩은 됐지만 아직 ApplicationContext가 리프레시되지 않은 시점에 발행된다. 이 이벤트가 발행된 후 Environment를 사용할 수 있다.
- ContextRefreshedEvent: ApplicationContext가 리프레시된 후에 발행된다. 이 이벤트는 스프링 부트가 아니라 스프링이 발행하는 이벤트라서 SpringApplicationEvent를 상속하지 않는다.
- WebServerInitializedEvent: 웹 서버가 준비되면 발행된다. 이 이벤트도 SpringApplicationEvent를 상속하지 않는다.
- ApplicationReadyEvent: 애플리케이션이 요청을 처리할 준비가 됐을 때 SpringApplication에 의해 발행된다. 이 이벤트가 발행되면 모든 애플리케이션 초기화가 완료된 것이므로 이 시점 이후로 애플리케이션 내부 상태를 변경하는 것은 권장하지 않는다.
- ApplicationFailedEvent: 애플리케이션 시작 과정에서 에외가 발생하면 발행한다. 예외 발생 시 스크립트를 실행하거나 실패를 알릴 때 사용된다.
스프링 부트 액추에이터
애플리케이션이 정상 실행 중인지 확인하기 위해 헬스 체크를 수행한다. 그리고 운영 중인 애플리케이션의 여러 부분에 대한 다양한 분석을 하기 위해 스레드 덤프나 힙 덤프를 수행하기도 한다. 스프링 부트 액추에이터의 기본 엔드포인트는 /actuator이며, 구체적인 지표를 뒤에 붙여서 사용한다.
Chapter2. 스프링 부트 공통 작업
애플리케이션 설정 관리
동일한 프로퍼티가 여러 곳에 존재할 때 지정된 우선순위는 다음과 같다.
- SpringApplication
@PropertySource- 설정 정보 파일(application.properties)
- 운영 체제 환경 변수
- 명령행 인자
SpringApplication 클래스 사용
SpringApplication 클래스를 사용해서 애플리케이션 설정 정보를 정의할 수 있다. 이 클래스에서 java.util.Properties 또는 java.util.Map<String, Object>를 인자로 받는 setDefaultProperties() 메서드가 있는데, 설정 정보를 Properties나 Map<String, Object>에 넣어서 이 메서드를 호출하면 설정 정보가 애플리케이션에 적용된다. 이 방식은 소스 코드로 정의하는 방식이므로 한 번 정의하면 나중에 바뀌지 않는 경우에 적합하다.
SpringApplication 클래스를 사용해 설정 관리
환경 설정 파일
properties 파일이나 yml 파일에 명시된 설정 프로퍼티 정보는 스프링의 Environment 객체에 로딩되고, 애플리케이션 클래스에서 Environment 인스턴스에 접근해서 설정 정보를 읽을 수 있으며, @Value 애너테이션을 통해 접근할 수도 있다.
스프링 부트는 기본적으로 다음 위치에 있는 application.properties 파일이나 application.yml 파일을 읽는다.
- 클래스패스 루트
- 클래스패스 /config 패키지
- 현재 디렉터리
- 현재 디렉터리 /config 디렉터리
- /config 디렉터리 바로 하위 디렉터리
이 위치 말고도 spring.config.location 프로퍼티를 사용하면 다른 위치에 있는 설정 파일을 읽을 수 있다.
java -jar target/application-0.0.1-SNAPSHOT.jar --spring.config.location=data/a.yml
스프링 부트는 애플리케이션 스타트업 과정 중 매우 이른 단계에서 spring.config.name과 spring.config.location 값을 로딩한다. 그래서 이 두 프로퍼티를 application.properties 파일이나 application.yml 파일에 지정할 수 없다. SpringApplication.setDefaultProperties() 메서드나 OS 환경 변수, 명령행 인자로 지정해야만 정상적으로 동작한다. 위에는 명령행 인자로 지정했다.
특정 프로파일에만 적용되는 설정 정보는 application.properties(또는 .yml) 파일이 아닌 application-{profile}.properties 파일에 작성하면 된다.
설정 파일은 다음 순서로 로딩된다.
- 애플리케이션 JAR 파일 안에 패키징 되는 application.properties(또는 .yml) 파일
- 애플리케이션 JAR 파일 안에 패키징 되는 application-{profile}.properties(또는 .yml) 파일
- 애플리케이션 JAR 파일 밖에서 패키징 되는 application.properties(또는 .yml) 파일
- 애플리케이션 JAR 파일 밖에서 패키징 되는 application-{profile}.properties(또는 .yml) 파일
운영 체제 환경 변수
환경 변수는 해당 명령행 터미널 세션에서만 유효하므로, 실습할 때는 환경 변수를 지정한 명령행 터미널에서 애플리케이션을 실행해야 한다.
@ConfigurationProperties로 커스텀 프로퍼티 만들기
스프링 부트에서는 커스텀 프로퍼티를 필요한 만큼 얼마든지 만들어 사용할 수 있으며, 커스텀 프로퍼티가 런타임에 로딩되는 것을 스프링 부트가 보장한다.
몇 가지 단점이 있는데,
- 프로퍼티값의 타입 안전성이 보장되지 않으며 이로 인해 런타임 에러가 발생할 수 있다. 예를 들어 URL이나 이메일 주소르 프로퍼티로 사용할 때 유효성 검증을 수행할 수 없다.
- 프로퍼티값을 일정한 단위로 묶어서 읽을 수 없고,
@Value애너테이션이나 스프링의 Environment 인스턴스를 사용해서 하나하나 개별적으로만 읽을 수 있다.
@ConfigurationProperties를 사용한 커스텀 프로퍼티 정의
@Configuration 애너테이션을 사용해 프로퍼티 정보를 담는 클래스를 만들어서 타입 안전성을 보장하고 유효성을 검증한다. 이렇게 하면 @Value 애너테이션이나 스프링의 Environment 객첼르 사용하지 않고도 프로퍼티 값을 읽어서 사용할 수 있다.
@ConfigurationProperties로 커스텀 프로퍼티 만들기
스프링 부트 애플리케이션 시작 시 코드 실행
스프링 부트 애플리케이션을 시작할 때 특정 코드를 실행해야 할 때가 있다. 예를 들어 애플리케이션 초기화가 완료되기 전에 데이터베이스 초기화 스크립트를 실행해야 할 수도 있고, 외부 REST 서비스를 호출해서 데이터를 가져와야 할 수도 있다.
CommandLineRunner와 ApplicationRunner는 둘 다 run() 메서드 하나만 가지고 있는 인터페이스인데 이 인터페이스를 구현해서 빈으로 등록해두면 스프링 부트 애플리케이션 초기화 완료 직전에 run() 메서드가 실행된다.
스프링 부트 애플리케이션 시작 시 CommandLineRunner로 코드 실행
CommandLineRunner는 다음과 같이 여러 가지 방법으로 사용할 수 있다.
- 스프링 부트 메인 클래스가 CommandLineRunner 인터페이스를 구현하게 만든다.
@SpringBootApplication public class Application implements CommandLineRunner { public static void main(String[] args) { SpringApplication.run(Application.class, args); } @Override public void run(String... args) throws Exception { System.out.println("Application CommandLineRunner has executed"); } - CommandLineRunner 구현체에 @Bean을 붙여서 빈으로 정의한다.
@SpringBootApplication public class Application implements CommandLineRunner { public static void main(String[] args) { SpringApplication.run(Application.class, args); } @Bean public CommandLineRunner commandLineRunner() { return args -> { System.out.println("CommandLineRunner executed " + args.length); IntStream.range(0, args.length).forEach(i -> { System.out.println("Argument: " + args[i]); }); }; } }- CommandLineRunner 구현체에 @Component를 붙여서 스프링 컴포넌트로 정의한다.
- 위에 2가지 방법은 CommandLineRunner 구현체를 스프링 부트 메인 클래스에 작성했지만, 이 방법은 별도의 클래스에 작성할 수도 있다.
@Order(1) // CommandLineRunner 구현체가 여러 개 있을 때, 실행 순서 지정 @Component public class MyCommandLineRunner implements CommandLineRunner { protected final Logger logger = LoggerFactory.getLogger(getClass()); @Override public void run(String... args) throws Exception { logger.info("MyCommandLineRunner executed as a Spring Component"); } }
- 위에 2가지 방법은 CommandLineRunner 구현체를 스프링 부트 메인 클래스에 작성했지만, 이 방법은 별도의 클래스에 작성할 수도 있다.
- CommandLineRunner 구현체에 @Component를 붙여서 스프링 컴포넌트로 정의한다.
CommandLineRunner는 애플리케이션 초기화를 위해 여러 작업을 수행해야 할 때 편리하게 사용할 수 있는 유용한 기능이다. CommandLineRunner 안에서는 args 파라미터에도 접근할 수 있으므로 외부에서 파라미터값을 다르게 지정하면서 원하는 대로 CommandLineRunner 구현체를 제어할 수 있다.
@Bean과 @Component
@Bean과 @Component 두 애너테이션은 모두 스프링에 의해 빈으로 등록된다는 공통점이 있지만 사용법은 조금 다르다. 빈으로 등록하고자 하는 클래스의 소스 코드에 직접 접근할 수 없을 때는 해당 클래스의 인스턴스를 반환하는 메서드를 작성하고 이 메서드에 @Bean 애너테이션을 붙여서 빈으로 등록되게 한다. 반대로 빈으로 등록하고자 하는 클래스의 소스 코드에 직접 접근할 수 있을 때는 이 클래스에 직접 @Component 애너테이션을 붙이면 빈으로 등록된다.
스프링 부트 애플리케이션 로깅 커스터마이징
스프링 부트 애플리케이션의 기본 로깅 이해 및 커스터마이징
스프링 부트 애플리케이션에서 사용할 수 있는 콘솔 로그는 기본으로 제공된다. 스프링 부트는 내부적으로 아파치 커먼즈(Apache Commons) 로깅 프레임워크를 사용한다. 하지만 로그백(Logback), Log4j2 같은 인기 있는 다른 로깅 프레임워크와 자바에서 제공하는 java.util.logging도 지원한다.
로그는 다음과 같은 정보로 구성돼 있다.
- 일시: 로그가 출력되는 날짜와 시간
- 로그 레벨: 로그의 중요도에 따라 표시되는 로그 레벨(FATAL, ERROR, WARN, INFO, DEBUG, TRACE)
- 프로세스 ID
- 구분자:
--- - 스레드 이름: 스프링 부트 애플리케이션은 다수의 스레드를 사용한다. 일부는 애플리케이션 스레드이고, 개발자가 여러 이유로 스레드를 만들어 사용할 수 있다. TaskExecutor를 생성해서 스레드풀에서 사용되는 이름을 지정하면 스프링 부트가 제공하는 비동기 처리 기능을 사용할 수 있다. 이렇게 지정된 스레드 이름이 로그에 표시된다.
- 로거 이름: 축약된 클래스 이름
- 메시지: 실제 로그 메시지
스프링 부트는 기본적으로 INFO, WRAN, ERROR 로그를 사용한다. TRACE, DEBUG 같은 로그 레벨을 사용하려면 application.properteis 파일에 별도로 지정해야 한다.
스프링 부트 애플리케이션에서 로그를 파일에 출력하는 가장 쉬운 방법은 logging.file.name이나 logging.file.path 프로퍼티를 application.properties 파일에 추가하는 것이다. logging.file.name=application.log라고 지정하면 프로젝트 루트 디렉터리에 application.log 파일이 생성되고 이 파일에 로그가 출력된다.
스프링 부트는 기본적으로 날짜가 바뀌거나 로그 파일 크기가 10MB가 되면 새 로그 파일로 롤링한다. 롤링되는 파일 크기는 logging.logback.rollingpolicy.max-file-size로 설정할 수 있다. 또한 기본적으로 생성된지 7일이 초과된 로그 파일은 삭제되는데, 7일을 다른 기간으로 변경하려면 logging.logback.rollingpolicy.max-history로 설정할 수 있다.
어펜더와 로거
- 로거: 로거는 한 개 이상의 어펜더를 사용해서 로그 메시지 표시를 담당하는 로깅 프레임워크의 컴포넌트다. 필요에 따라 다양한 로그 수준을 가진 다수의 로거를 정의할 수 있다.
- 어펜더: 어펜더를 사용해서 로그가 출력되는 대상과 로깅 포맷을 지정할 수 있다. 로그 메시지가 출력되는 매체에 따라 다양한 어펜더가 있다. 콘솔 어펜더는 애플리케이션의 콘솔에 로그를 출력하고, 파일 어펜더는 로그 메시지를 파일에 출력한다. RollingFileAppender는 시간과 날짜 기반으로 별도의 파일에 로그를 출력한다.
빈 밸리데이션(Bean Validation)으로 사용자 입력 데이터 유효성 검증
빈 밸리데이션은 자바 세계에서 사용되는 사실상 표준 밸리데이션이다.
public class Course {
private long id;
private String name;
private String category;
@Min(value = 1, message = "A course should have a minimum of 1 rating")
@Max(value = 5, message = "A course should have a maximum of 5 rating")
private int rating;
private String description;
}
다음은 하이버네이트 밸리데이터 API에 정의되어 자주 사용되는 애너테이션이다.
- @NotBlank: CharSequence 타입 필드에 사용되어 문자열이 null이 아니고, 앞뒤 공백 문자를 제거한 후 문자열 길이가 0보다 크다는 것을 검사한다.
- @NotEmpty: CharSequence, Collection, Map 타입과 배열에 사용되어 null이 아니고 비어 있지 않음을 검사한다.
- @NotNull: 모든 타입에 사용할 수 있으며 null이 아님을 검사한다.
- @Min(value=): 최소값을 지정해서 이 값보다 크거나 같은지 검사한다.
- @Max(value=): 최대값을 지정해서 이 값보다 작거나 같은지 검사한다.
- @Pattern(regex=, flags): regex로 지정한 정규 표현식을 준수하는지 검사한다. 정규 표현식의 flag도 사용할 수 있다.
- @Size(min=, max=): 개수의 최소값, 최대값을 준수하는지 검사한다.
- @Email: 문자열이 유효한 이메일 주소를 나타내는지 검사한다.
커스텀 빈 밸리데이션 애너테이션을 사용한 POJO 빈 유효성 검증
앞에서 빈 밸리데이션 프레임워크에서 제공하는 빌트인 애너테이션 사용법을 알아봤는데, 커스텀 애너테이션도 만들어 사용할 수 있다.
커스텀 애너테이션을 정의하려면 제약 사항 준수를 강제하기 위해 호출되는 ConstraintValidator를 먼저 정의해야 한다.
import jakarta.validation.ConstraintValidator;
import jakarta.validation.ConstraintValidatorContext;
import java.util.ArrayList;
import java.util.List;
import org.passay.CharacterCharacteristicsRule;
import org.passay.CharacterRule;
import org.passay.EnglishCharacterData;
import org.passay.LengthRule;
import org.passay.PasswordData;
import org.passay.PasswordValidator;
import org.passay.RepeatCharacterRegexRule;
import org.passay.Rule;
import org.passay.RuleResult;
public class PasswordRuleValidator implements ConstraintValidator<Password, String> {
/**
* ConstraintValidator 인터페이스는 Password, String 두 개의 타입 인자를 갖고 있다.
* 첫 번째 타입 인자는 커스텀 밸리데이터 로직을 적용하게 해주는 애너테이션
* 두 번째 타입 인자는 커스텀 애너테이션을 적용해야 하는 데이터 타입
* */
private static final int MIN_COMPLEX_RULES = 2;
private static final int MAX_REPETITIVE_CHARS = 3;
private static final int MIN_SPECIAL_CASE_CHARS = 1;
private static final int MIN_UPPER_CASE_CHARS = 1;
private static final int MIN_LOWER_CASE_CHARS = 1;
private static final int MIN_DIGIT_CASE_CHARS = 1;
@Override
public boolean isValid(String password, ConstraintValidatorContext context) {
// 비밀번호 정책: 최소 8자, 최대 30자, 대소문자와 숫자 혼합, 동일한 문자는 3번까지 반복 허용
List<Rule> passwordRules = new ArrayList<>();
passwordRules.add(new LengthRule(8, 30));
CharacterCharacteristicsRule characterCharacteristicsRule = new CharacterCharacteristicsRule(
MIN_COMPLEX_RULES, new CharacterRule(EnglishCharacterData.Special, MIN_SPECIAL_CASE_CHARS),
new CharacterRule(EnglishCharacterData.UpperCase, MIN_UPPER_CASE_CHARS),
new CharacterRule(EnglishCharacterData.LowerCase, MIN_LOWER_CASE_CHARS),
new CharacterRule(EnglishCharacterData.Digit, MIN_DIGIT_CASE_CHARS));
passwordRules.add(characterCharacteristicsRule);
passwordRules.add(new RepeatCharacterRegexRule(MAX_REPETITIVE_CHARS));
PasswordValidator passwordValidator = new PasswordValidator(passwordRules);
PasswordData passwordData = new PasswordData(password);
RuleResult ruleResult = passwordValidator.validate(passwordData);
return ruleResult.isValid();
}
}
PasswordRuleValidator 클래스는 ConstraintValidator 인터페이스를 구현하므로 isValid() 메서드를 구현해야 하고, 이 메서드 안에 유효성 검증 로직을 추가한다.
이제 PasswordRuleValidator를 사용하는 @Password 애너테이션을 아래와 같이 정의한다.
import jakarta.validation.Constraint;
import jakarta.validation.Payload;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
// 애너테이션을 적용할 대상 타입 지정: 메서드, 필드
@Target({ElementType.METHOD, ElementType.FIELD})
// 애너테이션의 효력 유지 기간 지정: 런타임
// SOURCE: 소스 코드 수준에서만 효력을 발휘하고 컴파일된 바이너리 결과물에는 포함되지 않아 효력을 잃는다.
// CLASS: 컴파일된 바이너리 결과물에 포함되어 효력을 발휘하지만, 런타임에는 포함되지 않아 효력을 잃는다.
// RUNTIME: 런타임까지 살아남아 효력을 유지한다.
@Retention(RetentionPolicy.RUNTIME)
// 빈 밸리데이션 제약 사항을 포함하는 애너테이션임을 의미하며,
// validateBy 속성을 사용해서 제약 사항이 구현된 클래스를 지정할 수 있다.
@Constraint(validatedBy = PasswordRuleValidator.class)
public @interface Password {
// 유효성 검증에 실패할 때 표시해야 하는 문자열 지정
String message() default "Password do not adhere to the specified rule";
// 그룹을 지정하면 밸리데이션을 그룹별로 구분해서 적용 가능
Class<?>[] groups() default {};
// 밸리데이션 클라이언트가 사용하는 메타데이터를 전달하기 위해 사용
Class<? extends Payload>[] payload() default {};
}
@Password 애너테이션을 엔티티 필드에 적용하면 된다.
Chapter3. 스프링 데이터를 사용한 데이터베이스 접근
스프링 데이터 소개
관계형 데이터베이스, 비관계형 데이터베이스, MapReduce 데이터베이스, 클라우드 기반 데이터 서비스 등 다양한 데이터 소스에 접근해서 데이터를 활용할 수 있다.
스프링 데이터는 스프링 프레임워크에 속해 있으며, 특정 데이터베이스를 대상으로 하는 여러가지 하위 프로젝트를 포함하고 있는 상위 프로젝트다. 스프링 데이터 JPA 모듈은 H2, MySQL, PostgreSQL 같은 관계형 데이터베이스를 대상으로 하며, 스프링 데이터 몽고DB 모듈은 몽고DB 데이터베이스를 대상으로 한다.
Java Persistence API(JPA)
JDBC(Java DataBase Connectivity)를 활용해 데이터베이스를 연결하고, 쿼리를 만들기 위해 PreparedStatement를 정의한다. JPA를 사용하면 부수적인 코드 작성을 획기적으로 줄어주며, 자바 비지니스 객체 모델과 테이블 같은 관계형 데이터베이스 모델을 이어주는 역할을 한다. 자바 객체와 관계형 데이터베이스 모델을 매핑하는 기법을 ORM(Object-Relation Mapping)이라고 부른다.
JPA 명세는 애플리케이션 객체를 쉽고 간결하게 저장하고 조회할 수 있게 해주는 인터페이스, 클래스, 애너테이션의 모음이다. JPA는 명세이고, ORM 기법에 대한 표준을 제공한다. 하이버네트나 이클립스링크는 JPA 명세를 구현하는 구현체다.
왜 스프링 데이터인가?
스프링 데이터 모듈에서는 널리 사용되는 JdbcTEmplate과 JmsTemplate처럼 템플릿(template)을 사용하는 디자인 패턴과 유사한 템플릿 형태의 API가 제공된다. 템플릿 클래스에는 저장소별 특화된 자원을 관리하고 에외를 변환할 수 있또록 여러 헬퍼(helper) 메서드가 포함돼 있다.
- 스프링 템플릿: 스프링 템플릿을 사용하면 JDBC, JMS, JNDI 처럼 공통적으로 활용되는 API를 사용하기 위해 불필요한 보일러플레이트 코드를 작성하지 않아도 된다. 예를 들어 JDBC를 사용하면 데이터베이스 연결, PreparedStatement 생성, 쿼리 실행, 예외 처리, 데이터베이스 연결과 PreparedStatement 자원 해제 등이 필요하다. 스프링 템플릿을 사용하면 보일러플레이트 코드를 작성해서 수행해야 하는 작업을 프레임워크가 대신 처리해주므로 개발자는 실제 비지니스 로직에 더 집중할 수 있다. 예를 들어 실행해야 하는 쿼리를 JdbcTempate을 사용해서 스프링 데이터 모듈에 전달하면 데이터베이스 연결 등 나머지 작업은 템플릿이 알아서 처리한다.
스프링 데이터는 지원되는 개별 데이터베이스를 추상화해주는 리포지토리(repository)를 공통 프로그래밍 모델로 사용한다. 리포지토리 추상화는 스프렝 데이터 커먼즈 모듈에 포함돼 있으며, 표준 CRUD 연산과 쿼리 실행을 가능하게 해주는 다양한 인터페이스를 포함하고 있다.
스프링 데이터 모듈
스프링 데이터 모듈은 스프링 데이터 프로젝트에 속해 있는 하위 프로젝트라고 볼 수 있다.
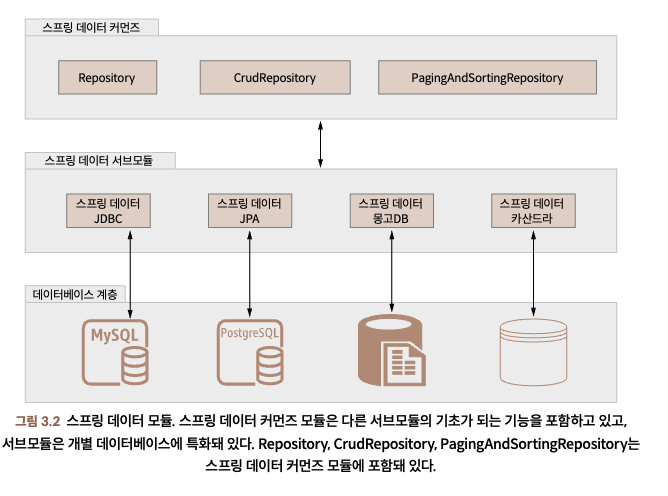
스프링 데이터 커먼즈는 스프링 데이터 모듈에서 사용하는 데이터 스토어의 독립적인 기초 컴포넌트로 구성돼 있다. 예를 들어 스프링 데이터 JPA 모듈은 스프링 데이터 커먼즈 모듈에서 정의한 인터페이스(Repository, CrudRepository, PagingAndSortingRepository)에 의존하고 있다.
스프링 부트 애플리케이션 데이터베이스 연동 설정
관계형 데이터베이스 연동 설정
- 의존 관계 추가: spring-boot-starter-data-jpa, 데이터베이스 드라이버
- application.properties 파일에 데이터베이스 연결 정보
스프링 부트는 자동 구성을 통해 히카리 커넥션 풀을 사용한다. 데이터베이스 커넥션 풀은 한 개 이상의 데이터베이스 연결을 포함하고 있으며, 일반적으로 애플리케이션이 시작될 때 커넥션 풀이 구성된다. 여러 개의 데이터베이스 연결을 애플리케이션이 시작될 때 미리 생성해서 풀에 넣고 필요할 때 꺼내어 사용하고, 사용 후 다시 풀에 반납하므로 쿼리를 실행할 때마다 데이터베이스 연결을 생성할 필요가 없고, 사용 후에도 삭제할 필요가 없다. 스프링 부트는 히카리 커넥션 풀을 기본 데이터베이스 커넥션 풀로 사용한다.
관계형 데이터베이스 초기화
스프링 부트는 src/main/resources 폴더 또는 직접 지정한 다른 폴더에 있는 SQL 스크립트 파일을 읽어서 사용할 수 있다. 기본적으로 schema.sql 파일을 읽어서 스키마를 정의하고, data.sql 파일을 읽어서 스크립트를 실행할 수 있다.
내장형 인메모리 데이터베이스가 아닌 다른 데이터베이스를 사용하는 상황에서 스크립트 파일을 사용해 데이터베이스를 초기화하려면, application.properties 파일에 spring.sql.init.mode=always로 설정해야 한다. embedded, always, never 이렇게 셋 중 하나의 값을 가질 수 있다. 기본값은 embedded라서 H2 같은 인메모리가 사용될 때만 데이터베이스 초기화가 실행된다.
이렇게 데이터베이스 스키마 초기화를 설정하면 스프링 부트는 애플리케이션을 재시작할 때마다 기존 스키마를 삭제하고 새로 재생성하며, 데이터베이스 스키마 버전 관리는 스프링 부트에서 지원되지 않는다.
CrudRepository 인터페이스 이해
스프링 데이터 리포지터리 모듈은 Repository 인터페이스를 사용해서 데이터 소스 접근을 추상화한다. Repository 인터페이스는 데이터비에스에 저장되어 관리되는 비즈니스 도메인 클래스(엔티티 클래스)와 그 식별자 타입을 필요로 한다.
Repository 인터페이스는 메서드나 상수를 포함하고 있지 않고, 오직 객체의 런타임 타입 정보만을 알려주는 마커(marker) 인터페이스로서 도메인 클래스와 도메인 클래스의 식별자 타입 정보를 포함하고 있다.
// spring-data-commons 모듈에 포함돼 있는 Repository 인터페이스
public interface Repository<T, ID> {}
CrudRepository는 Repository 인터페이스를 상속받은 하위 인터페이스이며 CRUD 연산을 포함하고 있다.
// spring-data-commons 모듈에 포함돼 있는 CrudRepository 일부
public interface CrudRepository<T, ID> extends Repository<T, ID> { // 제네릭 타입 T는 도메인 클래스를 나타내며 ID 타입은 도메인 클래스의 식별자 타입
<S extends T> S save(S entity); // 주어진 엔티티를 저장
Optional<T> findById(ID id); // ID로 엔티티를 조회
Iterable<T> findAll(); // 모든 엔티티를 조회
long count(); // 엔티티의 개수를 조회
void deleteById(ID id); // ID에 해당하는 엔티티를 삭제
// ...
}
스프링 데이터 모듈은 CrudRepository 인터페이스 외에도 CrudRepository를 상속받는 PagingAndSortingRepository 인터페이스도 제공하는데 이 인터페이스는 페이징과 정렬 기능이 포함돼 있다.
비지니스 도메인 클래스를 데이터베이스에 저장하고 관리하려면 CrudRepository나 PagingAndSortingRepository 인터페이스를 상속받고 엔티티 클래스와 식별자 타입 정보를 파라미터로 받는 커스텀 리포지터리 인터페이스가 필요하다. 예를 들어 Course 클래스를 저장하려면 커스텀 인터페이스인 CourseRepository<Course, Long>가 필요하고, 이 인터페이스는 CrudRepository 인터페이스에 있는 모든 메서드를 확장한다.
스프링 데이터를 사용한 데이터 조회
쿼리 메서드 정의
CrudRepository 인터페이스가 표준 CRUD 연산을 제공해주지만 이런 기본 메서드만으로 부족할 때도 있다. 기본 메서드는 주로 엔티티의 ID를 통해 데이터를 조회하지만, ID가 아닌 다른 프로퍼티로 조회해야 할 때도 있다. 또한 Like, StartsWith, Containing 등 엔티티의 프로퍼티에 조건을 걸어서 조회해야 할 때도 있고 하나 이상의 프로퍼티를 기준으로 오름차순이나 내림차순으로 정렬해야 할 때도 있다.
스프링 데이터 JPA는 이런 요구 사항을 충족할 수 있도록 커스텀 쿼리 메소드를 만들 수 있는 두 가지 방법을 지원한다.
- 리포지터리 인터페이스에 정의하는 메서드의 이름을 특정 패턴에 맞게 작성하면 스프링 데이터가 메서드 이름을 파싱해서 그에 맞는 쿼리를 만들어 실행한다.
- Query: 엔티티를 조회하는 데 사용되는 메서드는 find..By, read..By, get..By, query..By, stream..By, search..By 형태로 이름을 짓는다.
- Count: 엔티티의 개수를 세는 데 사용되는 메서드는 count..By 형태로 이름 짓는다.
- Exists: 엔티티의 존재 여부를 확인하는 데 사용되는 메서드는 exists..By 형태로 이름 짓는다.
- Delete: 엔티티를 삭제할 때 사용되는 메서드는 delete..By, remove..By 형태로 이름 짓는다.
- 이 외에도 더 세부적인 쿼리를 생성할 수 있는 패턴이 있다.
- 관계형 데이터베이스에서 스프링 데이터 JPA를 사용한 커스텀 쿼리 메서드 정의
- 엔티티 조회에 필요한 쿼리문을 직접 작성해서 전달해주면 스프링 데이터가 이 쿼리를 실행한다.
- 세밀하게 최적화된 쿼리가 이미 있고 특정 데이터베이스에 특화된 기능을 사용하는 경우
- 두 개 이상의 테이블을 조인해서 데이터를 조회해야 하는 경우
- 스프링 데이터의 NamedQuery, Query, QueryDSL을 사용해서 쿼리문을 직접 지정할 수 있다.
- NamedQuery: 자카르타 퍼시스턴스 쿼리 언어(JPQL)를 사용해 쿼리 정의
@NamedQuery애너테이션: name(필수), query(필수), lockMode(옵션), hints(옵션) 4개 속성을 가진다.- NamedQuery 쿼리 사용법
- Query
- NamedQuery를 사용하면 비지니스 도메인 클래스에 본질적으로 필요하지 않은 데이터 저장/조회 관련 정보를 추가한다는 단점이 있다. 따라서 쿼리 정보를 도메인 클래스가 아니라 리포지터리 인터페이스에 추가하는 방법을 생각해볼 수 있다.
@Query애너테이션을 사용하면 쿼리 메서드와 JPQL를 한곳에 둘 수 있다. 게다가 데이터베이스에 특화된 네이티브 쿼리도 사용할 수 있다. - Query 쿼리 사용법
- NamedQuery를 사용하면 비지니스 도메인 클래스에 본질적으로 필요하지 않은 데이터 저장/조회 관련 정보를 추가한다는 단점이 있다. 따라서 쿼리 정보를 도메인 클래스가 아니라 리포지터리 인터페이스에 추가하는 방법을 생각해볼 수 있다.
- QueryDSL
- NamedQuery, Query의 심각한 단점은 작성된 쿼리의 문법 정합성을 컴파일 타임에 검사할 수 없어서 쿼리문이 잘못 작성된 경우 런타임에서만 에러가 발생한다.
- Criteria API 사용
- JPA 2.0에 도입된 Criteria API를 사용하면 쿼리를 단순 문자열이 아니라 프로그램 코드로 작성할 수 있어서 타입 안전성을 보장할 수 있다.
- Criteria API를 사용해서 관계형 데이터베이스에 저장된 도메인 객체 관리
- 스프링 데이터 JPA와 QueryDSL
- Criteria API가 자바 표준인 JPA의 네이티브 명세이기는 하지만 코드양이 많아진다는 단점이 있다. QueryDSL은 Criteria API 처럼 타입 안전성을 보장하면서도 평문형 API를 사용해서 코드 작성량을 더 줄일 수 있게 해주는 서드파트 라이브러리다.
- 관계형 데이터베이스에 저장된 도메인 객체를 QueryDSL로 관리
- Criteria API와 QueryDSL
- Criteria API는 표준 JPA 명세서에 포함되는 라이브러리이므로 JPA를 사용하면 Criteria API도 사용할 수 있다. 반면에 QueryDSL은 오픈소스 서드파티 라이브러리다.
- Criteria API는 API가 장황하고 복잡해서 아주 단순한 쿼리를 작성하는 데도 상당히 많은 코드를 작성해야 한다는 단점이 있다. QueryDSL을 사용하면 일반적으로 더 간결하게 쿼리를 작성할 수 있다.
- Criteria API는 JPA가 사용되는 환경에서만 사용할 수 있다. 반면에 QueryDSL은 JPA 외에도 몽고 DB나 루신, JDO을 사용하는 환경에서도 사용할 수 있다.
- NamedQuery: 자카르타 퍼시스턴스 쿼리 언어(JPQL)를 사용해 쿼리 정의
PagingAndSortingRepository를 활용한 페이징
PagingAndSortingRepository 인터페이스도 CrudRepository 인터페이스를 상속받으므로 CRUD 연산을 수행할 수 있다.
PagingAndSortingRepository 인터페이스로 데이터 페이징 및 정렬
기법: 프로젝션
하나 또는 그 이상의 엔티티에 속하는 필드 중에서 필요한 일부 부분 집합만을 추려내서 조회하는 것을 프로젝션(projection)이라고 한다. 스프링 데이터는 인터페이스 기반 프로젝션과 클래스 기반 프로젝션을 지원한다.
인터페이스 기반 프로젝션은 필요한 필드에 대한 getter 메서드를 정의한 인터페이스를 통해 프로젝션을 수행한다.
클래스 기반 프로젝션은 인터페이스 대신에 데이터 전송 객체라고 불리는 DTO(Data Transfer Object)를 사용한다. DTO는 쿼리에 의해 반환되는 필드를 포함하고 있는 자바 POJO 객체다. DAO 계층과 서비스 계층 사이에서 데이터를 전송하는 것이 DTO의 주요 목적이다.
도메인 객체 관계 관리
엔티티 사이의 관계는 다음과 같이 분류할 수 있다.
- 일대일 관계: Course와 CourseDetail
- 일대다 관계: Person과 Address
- 다대일 관계: Book과 Publisher
- 다대다 관계: Course와 Author, 조인 테이블 필요
스프링 데이터 JPA를 사용해서 관계형 데이터베이스에서 다대다 관계 도메인 객체 관리
- @ManyToMany: 관계에는 소유자와 비소유자가 존재한다. 소유자는 관계를 소유하는 입장이고, 비소유자는 관계를 소유하지 않고 참조되는 입장이다. 일대다 관계에서는 다 쪽이 소유자다. 왜냐하면 다 쪽에서 일 쪽을 가리키는 참조 하나만 가지면 일대다 관계를 쉽게 관리할 수 있기 때문에 다 쪽이 관계를 소유하게 된다. 만약 일 쪽이 소유자라면 다 쪽을 가리키는 참조 여러 개를 관리해야 하므로 훨씬 복잡해진다. 다대다 관계에서는 양쪽 모두 다이므로 어느 쪽을 관게의 소유자로 정할지는 선택의 문제다. 예제에서는 강사가 강의를 소유한다는 관점에서 Author 엔티티를 관계의 소유자로 정했다.
Chapter4. 스프링 자동 구성과 액추에이터
스프링 부트 자동 구성을 뒷받침하는 다양한 빌딩 블록(building block)을 살펴보고 애플리케이션에서 어떻게 동작하는지 알아본다.
스프링 부트 자동 구성을 가능하게 해주는 다양한 조건부 애너테이션을 살펴보고, 애플리케이션의 상태를 모니터링하고 제어할 수 있게 해주는 스프링 부트 액추에이터를 사용해본다.
스프링 부트 자동 구성 이해
자동 구성은 이름 그대로 스프링 애플리케이션 개발에 필요한 컴포넌트를 자동으로 구성해준다. 자동 구성은 사용할 애플리케이션 컴포넌트를 적절히 추론하고 기본 설정 값을 자동으로 구성해서 애플리케이션을 초기화한다. 예를 들어 빌드 설정 파일에 spring-boot-starter-web 의존 관계를 추가하면 스프링 부트는 웹 애플리케이션 구동에 필요한 웹 서버가 필요할 것이라고 추론하고 아파치 톰캣 웹 서버를 기본 웹 서버로 추가해준다.
이번에는 조금 다른 시나리오를 생각해보자. 다수의 개발팀에서 스프링 프레임워크를 사용해서 여러 가지 프로젝트를 진행하고 있는데, 몇 가지 설정 bean은 모든 팀에서 복사해서 사용하고 있다는 사실을 어떤 개발자가 발견했다. 그래서 공통으로 사용되는 bean을 추출해서 공통 애플리케이션 컨텍스트 설정에 모아서 사용하려고 한다.
/**
* 분리된 프로젝트에 존재하는 설정 클래스이다.
* 이 설정 클래스를 사용하는 개발팀에서 이 프로젝트를 의존 관계로 추가해서 사용할 수 있다.
* */
@Configuration // 스프링 설정을 담당하는 어노테이션
public class CommonApplicationContextConfiguration {
// 여러 팀에서 공통으로 사용되는 스프링 빈 생성
@Bean
public RelationalDataSourceConfiguration dataSourceConfiguration() {
return new RelationalDataSourceConfiguration();
}
// 그 외 공통으로 사용되는 스프링 빈 정의 생략
}
개발팀에서 다음과 같이 CommonApplicationContextConfiguration을 가져와서 사용할 수 있다.
@Configuration
@Import(CommonApplicationContextConfiguration.class)
public class CommonPaymentContextConfiguration {
// Payment 개발팀의 다른 빈 정의 내용 생량
}
이렇게 하면 중복적으로 사용되던 빈을 추출해서 한곳에 모으고 중복 없이 사용할 수 있지만 한 가지 문제가 있다. 관계형 데이터베이스를 사용하지 않는 어떤 팀에서 CommonApplicationContextConfiguration 안에 있는 빈을 사용하되, RelationalDataSourceConfiguration 빈은 사용하지 않고 싶다면 어떻게 해야 할까? 이를 가능하게 해주는 것이 바로 스프링의 @Conditional 애너테이션이다.
@Conditional 애너테이션 이해
스프링 프레임워크에서는 스프링이 관리하는 컴포넌트의 생성을 제어할 수 있도록 @Bean, @Component, @Configuration 애너테이션과 함께 사용할 수 있는 @Conditional 애너테이션을 제공한다. @Conditional 애너테이션은 Condition 클래스를 인자로 받는다. Condition 인터페이스는 Boolean 값을 반환하는 mathces() 메서드 하나만 포함하고 있는 함수형 인터페이스다. mathces() 메서드가 true를 반환하면 @Conditional 함께 붙어 있는 @Bean이나 @Component, @Configuration이 붙어 있는 메서드나 클래스로부터 빈이 생성된다.
public class RelationDatabaseCondition implements Condition {
@Override
public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
return isMySqlDatabase();
}
private boolean isMySqlDatabase() {
try {
// 클래스패스에 MySQL 드라이버가 포함돼 있으면 true
Class.forName("com.mysql.jdbc.Driver");
return true;
} catch (ClassNotFoundException e) {
return false;
}
}
}
@Configuration
public class CommonApplicationContextConfiguration {
@Bean
@Conditional(RelationDatabaseCondition.class) // mathces() 메서드가 true를 반활할 때만 RelationalDataSourceConfiguration 빈을 생성
public RelationalDataSourceConfiguration dataSourceConfiguration() {
return new RelationalDataSourceConfiguration();
}
}
@Conditional 애너테이션을 쉽게 이해할 수 있도록 단순한게 만들기 위해 단지 클래스패스만 검사하도록 예제를 만들었지만, 실무적으로 얼마든지 복잡한 로직을 사용할 수도 있다. 일반적으로 Condition 구현체는 다음 두 가지 방식으로 구현한다.
- 특정 라이브러리가 클래스패스에 존재하는지 확인한다.
- application.properties 파일에 특정 프로퍼티가 정의돼 있는지 확인한다.
연습 삼아서 H2ConsoleAutoConfiguration, JpaRepositoriesAutoConfiguration 클래스를 살펴보는 것도 좋다.
스프링 부트 개발자 도구
<!-- 스프링 부트 개발자 도구 추가 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<optional>true</optional> 설정을 하면 개발자 도구가 프로젝트에 의존하는 다른 모듈에 영향을 미치는 것을 막을 수 있다. 이제 개발자 도구에 포함된 다양한 기능을 알아보자.
- 프로퍼티 기본값: spring-boot-devtools JAR 파일의 org.springframework.boot.devtools.env 패키지에 있는 DevToolsPropertyDefaultsPostProcessor 클래스를 사용해서 기본적으로 캐시 기능을 모두 비활성화
- 자동 재시작: 클래스패스에 변경 사항이 있을 때마다 자동으로 애플리케이션을 재시작해준다. 스프링 부트는 두 개의 클래스로더를 사용해서 자동 재시작 기능을 구현한다. 하나는 기본 클래스로더라고 부르며, 서드파티 라이브러리처럼 변경되는 일이 별로 없는 클래스를 로딩한다. 다른 하나는 리스타트 클래스로더라고 부르며, 개발자가 작성하는 변경이 잦은 클래스를 로딩한다.
- 라이브 리로드: 웹 페이지를 구성하는 리소스가 변경됐을 때 브라우저 새로고침을 유발하는 내장된 라이브 리로드 서버가 포함
커스텀 실패 분석기 생성
애플리케이션에서 발생한 실패/예외를 감지하고 해당 이슈를 이해하는 데 도움이 되는 정보를 제공해준다. 실패 분석기는 크게 두 가지 관점에서 유용하다.
- 실제 발생한 에러에 대한 상세한 메시지를 제공해서 문제의 근본 원인과 해결책을 결정할 수 있도록 도와준다.
- 애플리케이션 시작 시점에 검증을 수행해서 발생할 수 있는 에러를 가능한 한 일찍 파악할 수 있다. 예를 들어 외부 서비스가 정상 동작하지 않는다면 핵심 데이터를 가져올 수 없고 애플리케이션도 예상대로 동작하지 못할것이므로, 아예 애플리케이션을 시작하지 않는 쪽을 선택할 수 있다.
스프링 부트 액추에이터
스프링 부트 애플리케이션 모니터링과 관리에 필요한 기능을 제공한다. spring-boot-starter-actuator에는 spring-boot-actuator-autoconfigure와 micrometer-core 의존 관계가 포함돼 있다. spring-boot-actuator-autoconfigure는 스프링 부트 액추에이터의 핵심 기능과 자동 구성 설정이 포함돼 있고, micrometer-core에는 다양한 측정지표를 수집할 수 있는 마이크로미터 지원 기능이 포함돼 있다.
애플리케이션을 시작하고 브라우저에서 http://localhost:8081/actuator/health 접속하면 {"status":"UP"} 을 확인할 수 있다.
스프링 부트 액추에이터 엔드포인트 이해
액추에이터 엔드포인트는 웹(HTTP) 또는 JMX(Java Management Extensions)를 통해 호출할 수 있다. 기본적으로 health와 info 엔드포인트만 HTTP를 통해 접근할 수 있도록 노출되어 있고, 나머지 엔드포인트는 HTTP에 노출되지 않는다. 하지만 JMX는 HTTP보다 보안성이 높으므로 스프링 부트가 제공하는 모든 액추에이터 엔드포인트가 기본적으로 노출되도록 설정돼 있다.
스프링 부트 액추에이터 엔드포인트 관리
필요한 엔드포인트만을 쉼표로 연결해서 지정할 수도 있다.
management:
endpoints:
web:
exposure:
include: bean, threaddump
액추에이터 컨텍스트 루트인 /actuator는 다른 이름으로 변경할 수 있다.
management:
endpoints:
web:
base-path: sbip
액추에이터 컨텍스트 루트 이름뿐만 아니라 포트 번호도 변경할 수 있다.
management:
server:
port: 8081
Health 엔드포인트 탐구
health 엔드포인트에 접근하면 애플리케이션과 애플리케이션에서 사용하는 여러 컴포넌트의 상태를 전반적으로 파악할 수 있다.
스프링 부트는 애플리케이션 컴포넌트별로 다양한 HealthIndicator 구현체를 제공한다. 이 중 DiskSpaceHealthIndicator와 PingHealthIndicator, DataSourceHealthIndicator 같은 일부 구현체는 항상 기본으로 포함된다.
디스크 사용 현황과 핑(ping) 상태도 추가해서 확인하는 방법을 알아보자.
management:
endpoint:
health:
show-details: always
health 엔드포인트에서 더 다양한 애플리케이션 상태 상세 정보를 보여주도록 변경할 수 있다.
- always: 상태 상세 정보를 항상 표시
- never: 기본값이며 상태 상세 정보를 표시하지 않음
- when-authorized: 애플리케이션에서 인증되고 application.properties 파일의 management.endpoint.health.roles로 지정한 역할을 가지고 있는 사용자가 접근할 때만 상태 상세 정보를 표시한다.
{
"status": "UP",
"components": {
"db": {
"status": "UP",
"details": {
"database": "H2",
"validationQuery": "isValid()"
}
},
"diskSpace": {
"status": "UP",
"details": {
"total": 294384795648,
"free": 218491789312,
"threshold": 1048570,
"path": "~/project/maven.project/.",
"exists": true
}
},
"ping": {
"status": "UP"
}
}
}
커스텀 스프링 부트 HealthIndicator 작성
스프링 부트에 내장된 HealthIndicator는 애플리케이션에 특화된 컴포넌트에 대한 상태 정보를 보여주지는 않는다. 하지만 스프링 부트는 HealthIndicator 인터페이스를 통해 health 엔드포인트 기능을 확장할 수 있도록 열어 두었다. 스프링 부트는 개발자가 구현한 HealthIndicator 구현체도 스프링 컴포넌트로 간주하여 스프링 부트 컴포넌트 스캐닝 시 감지할 수 있고 자동으로 health 엔드포인트에 연동해준다.
커스텀 스프링 부트 액추에이터 HealthIndicator 정의
커스텀 스프링 부트 액추에이터 엔드포인트 생성
스프링 부트 액추에이터 매트릭
스프링 부트는 내부적으로 마이크로미터 프레임워크를 사용해서 측정지표를 설정한다. 또한 카운터, 타이머, 게이지, 분포 요약 정보 같은 커스텀 측정지표도 정의할 수 있다.
마이크로미터는 다양한 유형의 측정지표를 벤더 중립적인 방법으로 수집할 수 있는 파사드(facade)다. 그래서 프로메테우스, 그라파이트, 뉴 렐릭 등 다양한 모니터링 시스템 구현체 중에서 원하는 구현체를 선택해 플로그인 방식으로 사용할 수 있다.
마이크로미터는 벤더 중립적인 측정지표 수집 API와 프로메테우스 같은 모니터링 프레임워크 구현체를 포함하고 있다. 프로메테우스 말고 다른 모니터링 시스템을 사용하려면 micrometer-registry-{monitoring_system} 의존 관계를 추가하면 스프링 부트가 자동 구성으로 해당 모니터링 시스템을 사용할 수 있게 해준다.
스프링 부트는 MeterRegistry를 사용해서 자동 구성으로 여러 개의 레지스트리 구현체를 추가할 수 있다. 그래서 한 개 이상의 모니터링 시스템에 측정지표를 내보내서 사용할 수 있다. 또한 MeterRegistryCustomizer를 사용해서 레지스트리 커스터마이징도 가능하다. 예를 들어 측정지표를 프로메테우스와 뉴 렐릭으로 보내고 두 개의 레지스트리에 공통으로 태그 셋을 설정해서 사용할 수 있다. 여기에서 말하는 태그는 식별자로 사용된다. 예를 들어 다수의 애플리케이션이 측정 지표를 내보낼 때 애플리케이션 이름을 식별하기 위해 태그를 사용할 수 있다.
@Bean
MeterRegistryCustomizer<MeterRegistry> metricsCommonTags() {
return registry -> registry.config().commonTags("application", "course-tracker");
}
위에서 추가한 애플리케이션 태그 정보가 포함(http://localhost:8081/actuator/metrics/jvm.buffer.memory.used?tag=application:course-tracker)돼 있는 것을 확인할 수 있다. 이 태그를 이용해서 측정지표를 필터링하면 특정 애플리케이션에 대한 측정지표를 얻을 수 있다.
커스텀 측정지표 생성
개발자가 어플리케이션을 모니터링하는 데 필요한 애플리케이션 특화된 데이터를 보여주는 커스텀 측정지표를 정의하고 수집해서 확인할 수 있는 기능을 제공한다.
프로메테우스와 그라파나를 사용한 측정지표 대시보드
프로메테우스는 사운드클라우드에서 처음 만들어진 오픈소스화된 모니터링 시스템이자 경고 알림 도구다. 그라파나는 수집한 여러 가지 측정지표를 다양한 그래프, 시계열 차트, 게이지 테이블 등을 이용해서 대시보드에 그려주는 시각화 도구다.
Chapter5. 스프링 부트 애플리케이션 보안
스프링 시큐리티 소개
스프링 부트는 spring-boot-starter-security 의존 관계를 추가해서 손쉽게 스프링 시큐리티를 적용할 수 있다. 스프링 시큐리티가 제공해주는 기본적인 보안 기능이 무엇인지 대략적으로 살펴보자.
- 애플리케이션 사용자 인증
- 별도의 로그인 페이지가 없을 때 사용할 수 있는 기본적은 로그인 페이지
- 폼(form) 기반 로그인에 사용할 수 있는 기본 계정
- 패스워드 암호화에 사용할 수 있는 여러 가지 인코더
- 사용자 인증 성공 후 세션 ID를 교체해서 세션 고정 공격 방식
- HTTP 응답 코드에 랜덤 문자열 토큰을 포함해서 사이트 간 요청 위조(CSRF) 공격 방지
- 세션 인증 정보와 CSRF 토큰을 사용해서 접근해야 함
- 공통적으로 자주 발생하는 보안 공격을 방어할 수 있는 여러 가지 HTTP 응답 헤더 제공
- Cache-Control: 브라우저 캐시를 완전하게 비활성화
- X-Content-Type-Options: 브라우저의 콘텐트 타입 추측을 비활성화하고 Content-Type 헤더로 지정된 콘텐트 타입으로만 사용하도록 강제
- Strict-Transport-Security: 응답 헤더에 포함되면 이후 해당 도메인에 대해서는 브라우저가 자동으로 HTTPS를 통해 연결하도록 강제하는 HSTS 활성화
- X-Frame-Options: 값을 DENY로 설정하면 웹 페이지 콘텐트가 frame, iframe, embed에서 표시되지 않도록 강제해서 클릭재킹 공격 방지
- X-XSS-Protection: 값을
1; mode=block으로 설정하면 브라우저 XSS 필터링을 활성화하고 XSS 공격이 감지되면 해당 웹페이지를 로딩하지 않도록 강제
스프링 부트와 스프링 시큐리티
스프링 부트 애플리케이션에서 스프링 시큐리티 활성화
spring-boot-starter-security 의존 관계를 추가한 후 애플리케이션을 실행하고 /index에 접근하면 놀랍게도 만들지도 않은 로그인 화면이 표시되는 것을 확인할 수 있다.
로그인에 필요한 계정 이름은 user이고 비밀번호는 스프링 부트 애플리케이션 시작 시 로그에 표시되며 애플리케이션이 시작될 때마다 다른 값이 표시된다. 또한, /logout 엔드 포인트를 기본으로 제공해준다.
spring-boot-starter-security 의존 관계를 자세히 들여다보면 spring-security-config, spring-security-web 같은 라이브러리에 의존하고 있는 것을 알 수 있는데, 이 두 개의 라이브러리에 스프링 시큐리티 기능이 포함돼 있다.
일반적인 웹 어플리케이션에서 사용되는 인증 과정을 살펴보자.
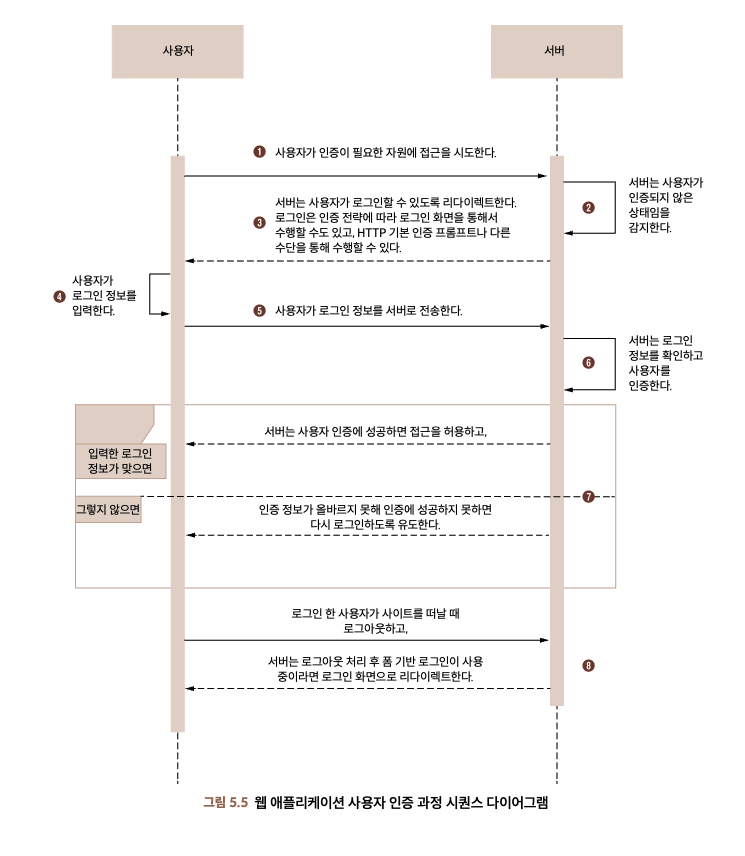
필터, 필터체인과 스프링 시큐리티
일반적인 자바 웹 애플리케이션에서 클라이언트는 HTTP나 HTTPS 프로토콜을 사용해서 서버의 자원에 접근한다. 클라이언트의 요청은 서버의 서블릿에서 처리된다. 서블릿은 HTTP 요청을 받아 처리한 후 HTTP 응답을 클라이언트에게 반환한다. 스프링 웹 애플리케이션에서는 DispatcherServlet이 서블릿의 역할을 담당하고 애플리케이션으로 들어오는 모든 요청을 처리한다.
서블릿 명세에 있는 요청-응답 처리 과정에서 중심축을 담당하는 중요한 역할을 하는 주요 컴포넌트는 필터(fitler)다. 필터는 서블릿의 앞 단에 위치해서 요청-응답을 가로채서 변경할 수 있다. 한 개 이상의 필터는 필터체인으로 구성할 수 있다. 필터와 필터체인은 모두 javax.servlet 패키지에 포함돼 있는 인터페이스다.
스프링 웹 애플리케이션으로 들어오는 모든 요청을 하나의 특별한 서블릿인 DispatcherServlet 혼자서 처리하는 것과 마찬가지로 스프링 시큐리티는 하나의 특별한 필터인 DelegatingFilterProxy에 의해 활성화된다.
// Filter 인터페이스
public interface Filter {
public default void init(FilterConfig filterConfig) throws ServletException {}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException;
public default void destory() {}
}
Filter 인터페이스에는 3개의 메서드가 있으므로 구현체는 3개의 메서드를 구현해야 한다. 필터가 수행하는 실질적인 로직은 doFilter 메서드에 구현해야 하며 Filter의 라이프 사이클은 다음과 같다.
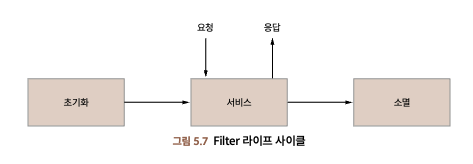
- init(): 서블릿 컨테이너가 필터를 등록하는 초기화 과정에서 호출된다.
- doFilter(): 필터의 실질적인 작업을 수행하는 메서드로서 요청, 응답, FilterChain 객체에 접근할 수 있다.
- destory(): 서블릿 컨테이너가 필터를 제거할 때 호출된다.
FilterChain도 서블릿 컨테이너에 의해 제공되는 컴포넌트인데 여러 필터를 연쇄적으로 거쳐 흘러가게 만드는 역할을 한다.필터는 자신의 작업이 완료되면 FilterChain을 호출해서 요청이 다음 필터를 통과하게 만든다. 요청이 체인상에 있는 마지막 필터를 통과하면 서블릿 같은 실제 리소스에 접근하게 된다.
스프링 시큐리티는 다양한 보안 관련 기능을 구현하기 위해 필터를 굉장히 많이 사용하며 스프링 시큐리티의 핵심은 필터에 기반을 두고 있다.
이제 스프링 시큐리티의 두 가지 주요 필터인 DelegatingFilterProxy와 FilterChainProxy에 대해 알아보자. 이 두 필터는 HTTP 요청이 스프링 시큐리티 인프라스트럭처를 통과하게 만드는 진입점 역할을 한다.
스프링 시큐리티 아키텍처
Filter는 서블릿 명세에서 아주 쓸모가 많은 컴포넌트다. Filter 인스턴스는 서블릿 컨테이너 컴포넌트다. 생성, 초기화, 소멸에 이르는 필터의 라이프 사이클은 서블릿 컨테이너가 관리한다. 서블릿 명세에는 당연하게도 Filter와 스프링의 연동에 대한 어떤 요건도 포함되어 있지 않다.
스프링 시큐리티는 DelegatingFilterProxy를 사용해서 서블릿 필터와 스프링 사이의 간극을 채운다. DelegatingFilterProxy는 서블릿 필터이며 서블릿 컨테이너에 등록되고 라이프 사이클 역시 서블릿 컨테이너가 관리한다. 서블릿 컨테이너로 관리하는 Filter 구현체 혼자서는 스프링 프레임워크의 기능을 활용할 수 없다. 그래서 별도의 Filter 구현체를 하나 더 정의해서 스프링으로 관리하는 스프링 빈으로 만든다. 이 스프링 빈은 DelegatingFilterProxy 안에서 대리인 역할을 하는 delegate로 설정된다. DelegatingFilterProxy는 서블릿 필터로서 런타임에 가로챈 요청을 delegate로 설정된 스프링 빈에 위임해서 처리한다.
FilterChainProxy가 앞서 말한 대로 스프링 빈에 등록되고 DelegatingFilterProxy의 대리인 역할을 하는 Filter 인터페이스 구현체다. FilterChainProxy는 하나 이상의 SecurityFilterChain을 가질 수 있다. DelegatingFilterProxy가 필터로서 가로챈 요청을 FilterChainProxy에 위임하면 FilterChainProxy는 자신이 가지고 있는 SecurityFilterChain에 요청을 흘려보내서 SecurityFilterChain에 있는 필터를 통과하게 만든다.
지금까지 설명한 DelegatingFilterProxy, FilterChainProxy, SecurityFilterChain 내용을 그림으로 정리하면 아래와 같다.
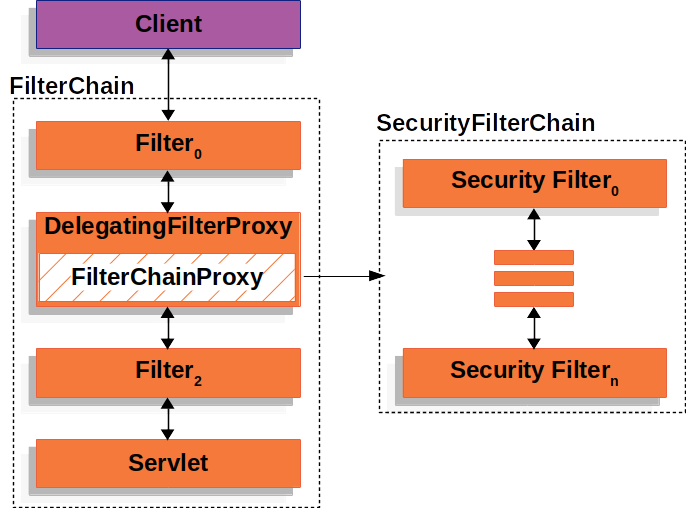
클라이언트 요청 > 서버의 (필터 > )서블릿에서 처리 > 클라이언트에게 응답 반환
- 필터는 서블릿 앞단에서 요청-응답을 가로채 변경 가능
- init, doFilter, destory 메서드
- DelegatingFilterProxy: 스프링 시큐리티 활성화
- 서블릿 필터, 서블릿 컨테이너가 관리
- 서블릿 필터로서 런타임에 가로챈 delegate로 설정된 빈에 위임해서 처리
- FilterChainProxy: Filter 구현체를 정의, 스프링으로 관리하는 스프링 빈
- DelegatingFilterProxy 대리인 역할을 하는 Filter 구현체
- 하나 이상의 SecurityFilterChain을 가짐
SecurityFilterChain 인터페이스는 matches()와 getFilters() 메서드를 가지고 있다. matches() 메서드는 SecurityFilterChain 구현체가 요청을 처리하는 데 적합한지를 판별한다. 스프링 시큐리티는 matches() 메서드에 활용할 수 있는 RequestMatcher 인터페이스와 여러 구현체를 제공한다. 예를 들어 AnyReqestMatcher를 사용하면 모든 HTTP 요청이 해당 SecurityFilterChain 구현체를 통과한다. 스프링 시큐리티는 URL 기반으로 판별할 수 있도록 AntPathRequestMatcher도 제공한다.
SecurityFilterChain의 matches() 메서드가 true를 반환하면 요청은 해당 SecurityFilterChain을 거치게 되는데, 이때 getFilters() 메서드가 호출되면서 요청이 SecurityFilterChain 구현체의 필터 목록에 있는 모든 필터를 거친다.
여러 개의 SecurityFilterChain 구성
애플리케이션에 여러 개의 SecurityFilterChain을 구성하려면 체인의 순서가 보장돼야 한다. 스프링의 @Order 애너테이션을 사용해서 여러 SecurityFilterChain 사이의 순서를 지정할 수 있다. 더 구체적인 URL로 들어오는 요청을 처리한 SecurityFilterChain이 더 높은 우선순위를 가져야 한다. 예를 들어 /admin으로 들어오는 요청을 처리하는 필터체인 A와 /*로 들어오는 요청을 처리하는 필터체인 B가 있을 때, A의 우선순위가 B보다 높아야 /admin으로 들어오는 요청이 A 필터체인을 통과할 수 있다.
사용자 인증
인증에 사용되는 주요 개념과 클래스를 먼저 살펴보자.

-
SecurityContextHolder: SecurityContext 인스턴스를 현재 실행 중인 스레드에 연동한다. SecurityContext 인스턴스에는 사용자 이름이나 권한 등 사용자 식별에 필요한 상세 정보가 담겨 있다. SecurityContextPersistenceFilter가 SecurityContext 인스턴스를 관리한다. SecurityContextPersistenceFilter는 SecurityContextRepository를 통해 SecurityContext 인스턴스를 획득한다. 웹 어플리케이션에서는 HttpSessionSecurityContextRepository 구현체가 HTTP 세션에 담긴 정보를 SecurityContext에 로딩한다. 인증 전에는 비어 있는 SecurityContext가 SecurityContextHolder에 추가된다. 정리하면 SecurityContextHolder에 SecurityContext가 포함되고, SecurityContext에 Authentication이 포함된다.
-
AuthenticationFilters: 사용자 정보를 인증하는 데 사용되는 인증 필터로 스프링 시큐리티는 여러 가지 인증 필터를 제공한다. 인증 필터가 사용자 정보를 인증하면 SecurityContext에 인증 토큰을 저장하며, 인증 토큰은 필터 체인상에 있는 다른 필터에서 사용할 수 있다.
-
ExceptionTranslationFilter: 인증 처리 과정에서 발생한 예외를 처리하는 데 핵심적인 역할을 담당한다. 인증에 실패해서 AuthenticationException이 발생하면 ExceptionTranslationFilter는 AuthenticationEntryPoint로 리다이렉트해서 다시 인증 과정이 진행되게 한다. 스프링 시큐리티는 인증 방식에 따라 여러 가지 AuthenticationEntryPoint를 제공한다. 인증에는 성공했지만 요청한 자원에 접근할 수 있는 권한이 없어서 AccessDeniedException이 발생하면, ExceptionTranslationFilter는 AccessDeniedHandler로 요청을 보내서 예외를 처리한다.
-
UserDetailsService: 사용자별 데이터를 스프링 시큐리티의 UserDetails 객체로 매핑해주는 역할을 담당한다. 스프링 시큐리티에서 제공해주는 구현체를 사용할 수도 있고, 직접 구현할 수도 있다.
-
AuthenticationProvider: 실제 인증 처리를 담당하며 인증 요청 객체를 받아서 인증 과정을 수행하고 인증 정보가 담긴 Authentication 객체를 반환한다. 인증에 실패하면 AuthenticationException을 던진다.
스프링 시큐리티로 구현된 인증 과정을 자세히 살펴보자.
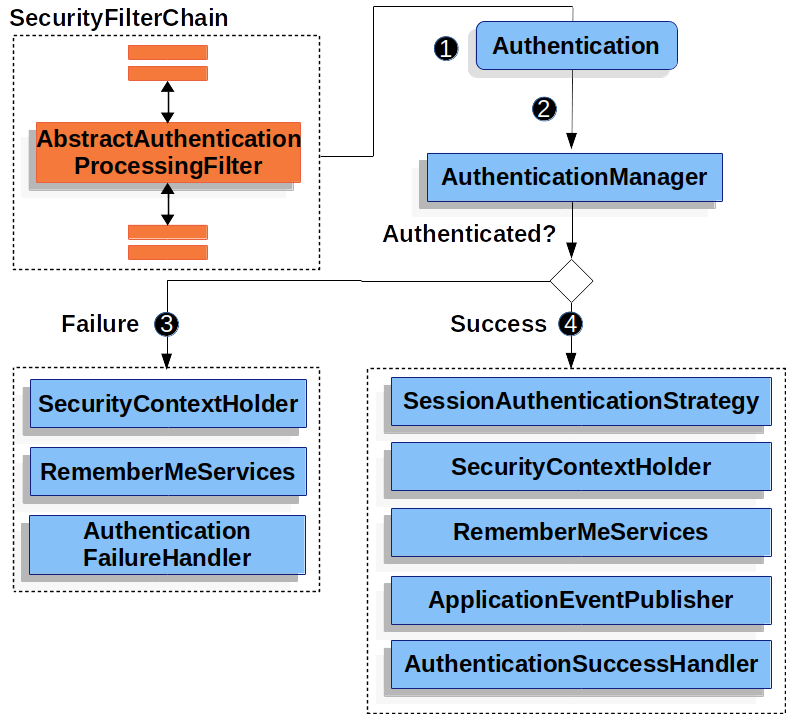
- 요청이 처음 들어오면 인증 필터를 거친다. 서버에 설정된 보안 전략에 따라 적절한 인증 필터가 요청을 처리한다. 예를 들어 HTTP 기본 인증을 사용하도록 설정돼 있다면 BasicAuthenticationFilter가 요청을 처리한다.
- Authentication: 인증 필터는 요청에 포함된 정보를 토대로 인증 토큰을 생성한다. 인증 토큰을 인자로 전달하면서 AuthenticationManager의 authenticate() 메서드를 호출한다.
- AuthenticationManager: 실제 인증 처리 서비스를 제공하는 AuthenticationProvider 인스턴스 목록을 가지고 있다. AuthenticationProvider 인터페이스에는 supports(), authenticate() 이렇게 두 개의 메서드가 있는데, supports() 메서드는 인증 토큰을 인자로 받아서 AuthenticationProvider 인스턴스가 이 인증을 처리할지를 판별해서 boolean 값을 반환한다. supports() 메서드가 true를 반환하면 authenticate() 메서드가 호출되면서 인자로 받은 인증 토큰으로 인증 작업을 수행한다.
- AuthenticationProvider: authenticate() 메서드는 인자로 받은 인증 토큰에서 username 값을 추출해서 UserDetailsService 구현체의 loadUserByUsername() 메서드에 인자로 전달하면서 호출한다.
- UserDetailsService: loadUserByUsername()은 인자로 받은 username으로 사용자 정보 저장소를 조회해서 사용자 권한, 비밀번호 등 계정 관련된 정보를 UserDetails에 담아 AuthenticationProvider에게 반환한다.
- AuthenticationProvider: 반환받은 UserDetails에 담겨 있는 정보를 토대로 인증 작업을 수행하고 인증이 성공하면 Authentication을 AuthenticationManager에게 반환한다.
- AuthenticationManager는 반환받은 Authentication에서 비밀번호 등 비밀 정보를 삭제하고 Authentication을 인증 필터에 반환한다.
- 인증 필터는 반환받은 Authentication을 SecurityContextHolder에 저장하고 응답을 반환한다.
UserDetailsService
UserDetailsService 인터페이스는 애플리케이션에서 따라 다르게 저장되는 사용자 상세 정보를 스프링의 UserDetails 구현체로 변환하는 핵심적인 역할을 담당한다. UserDetails 인터페이스는 스프링 애플리케이션에서 애플리케이션 사용자를 나타내며 사용자 계정 관련 다양한 정보를 저장한다. UserDetailsService에는 유일한 메서드인 loadUserByUsername(String username) 메스드가 있는데 이 메서드는 인자로 받은 username을 기준으로 애플리케이션이 사용하는 정보 저장소에서 사용자 정보를 저장한다. 스프링 시큐리티는 InMemoryUserDetailsManager, JdbcUserDetailsManager 같은 여러 가지 UserDetailsService 구현체를 제공한다. 물론 loadUserByUsername() 메서드를 재정의하기만 하면 커스텀 UserDetailsService 구현체를 사용할 수도 있다.
스프링 시큐리티 자동 구성
스프링 시큐리티를 이해하기 위해 마지막으로 남은 부분은 이런 여러 컴포넌트가 스프링 부트 애플리케이션에서 어떻게 설정되고 협업하게 되는지를 이해하는 것이다. 이번에도 스프링 부트 자동구성이 등장한다.
스프링 부트는 SecurityAutoConfiguration, UserDetailsServiceAutoConfiguration, SecurityFilterAutoConfiguration 이렇게 세 개의 설정 클래스를 사용해서 스프링 시큐리티 자동 구성을 수행한다.
- SecurityAutoConfiguration
- 스프링 시큐리티 자동 구성에서 중심점 같은 역할 담당
- 스프링 시큐리티 라이브러리가 클래스패스에 있지만 개발자가 커스텀 시큐리티 설정을 추가하지 않을 때, 사용되며, 폼 로그인 기능과 HTTP 기본 인증 기능을 포함하는 SecurityFilterChain 빈을 생성
- @Import를 사용해서 아래의 클래스들을 사용
- SpringBootWebSecurityConfiguration
- WebSecurityEnablerConfiguration
- 클래스에 별다른 내용 없이 여러 가지 애너테이션만 붙어 있는데, 이 중에서 중요한 것은 @EnableWebSecurity 애너테이션
- @EnableWebSecurity 애너테이션은 WebSecurityConfiguration, HttpSecurityConfiguration 클래스를 import 하고 @EnableGlobalAuthentication 애너테이션을 포함
- WebSecurityConfiguration: 이미지, CSS, JS 파일 같은 웹 리소스에 대한 보안 설정을 담당하는 WebSecurity 빈을 생성
- HttpSecurityConfiguration: HTTP 요청에 대한 보안 설정을 담당하는 WebSecurity 빈을 생성
- @EnableWebSecurity: 모든 SecurityFilterChain에 전역적으로 적용되는 AuthenticationManager를 AuthenticationManagerBuiler 인스턴스를 사용해서 설정, 따라서 스프링 시큐리티 설정을 할 때 설정 클래스에 해당 애너태이션을 붙여야 스프링 시큐리티 기능이 활성화
- 개발자가 웹 애플리케이션 환경에 맞게 스프링 시큐리티 설정 파일을 작성하고 해당 어노테이션을 붙이면, WebSecurityEnablerConfiguration 클래스는 개발자가 작성한 커스텀 설정 파일에 의해 무시
- 기본 스프링 시큐리티 대신 직접 스프링 시큐리티 설정을 정의하려면 WebSecurityConfigurerAdapter를 상속받는 클래스를 정의하거나 WebSecurityConfiguere 인터페이스를 직접 구현하면 된다.
- SecurityDataConfiguration: 스프링 시큐리티와 스프링 데이터를 연동하는데 사용
- UserDetailsServiceAutoConfiguration: 애플리케이션에 UserDetailsService 구현체가 빈으로 등록돼 있지 않으면 InMemoryUserDetailsManager를 빈으로 등록해준다. InMemoryUserDetailsManager에는 사용자 이름이 user이고 비밀번호가 랜덤 UUID인 기본 계정이 포함된다. 이 기능도 개발자가 직접 UserDetailsService의 구현체를 만들어 빈으로 등록하면 비활성화된다.
- SecurityFilterAutoConfiguration: DelegatingFilterProxyRegistrationBean 빈 생성. DelegatingFilterProxyRegistrationBean은 DelegatingFilterProxy 필터를 생성하고 서블릿 컨테이너에 등록하는 역할 담당