컴퓨터 밑바닥의 비밀 책을 읽고 정리한 내용입니다.
Chapter 1. 프로그래밍 언어부터 프로그램 실행까지, 이렇게 진행된다
Section 1.1 여러분이 프로그래밍 언어를 발명한다면?
- 스위치를 조작해 불 논리(boolean logic)를 표현할 수 있고, 이를 기반으로 CPU를 만들었다.
- 천공 카드(punched card)로 컴퓨터 작업 제어
- 어셈블리어(assembly language): 가산 명령어, 점프 명령어 등 몇 가지 명령어를 기계어와 대응
- 어셈블리어는 인간이 인식할 수 있는 단어가 있지만, 기계어와 마찬가지로 여전히 저수준 언어(low-level language)
- 저수준 계층의 세부 사항 vs 고수준 계층의 추상화
- 저수준 언어는 모든 세부 사향에 대해 신경을 써야 함
- 인간의 추상적인 표현을 CPU가 이해할 수 있는 구체적인 구현으로 자동 변환할 수 있다면 프로그래머가 생산성을 획기적으로 높일 수 있다.
- 가득한 규칙: 고급 프로그래밍 언어의 시작
- 세부 사항이 규칙 또는 패턴으로 가득하다는 것을 발견
- 명령어에는 문(statement)
- 조건에 따른 이동, if-else
- 순환, while
- 명령어의 세부 사항만 차이가 있는데, 이런 차이를 매개변수(parameter)
- 세부 사항이 규칙 또는 패턴으로 가득하다는 것을 발견
- 재귀: 단계별로 계속 중첩
- 컴퓨터가 재귀를 이해하도록 만들기: 재귀 구문에 따라 작성된 코드를 트리(tree) 구조로 표현할 수 있다.
- 컴파일러(compiler)
- 코드는 트리 형태로 표현될 수 있다. 그렇게 되면, 리프 노드(leap node)의 표현이 매우 간단하게 바뀌어서 간단하게 기계 명령어로 번역이 가능해진다. 이렇게 번역 결과를 차례대로 부모 노드에 적용하는 방식으로 올라가다 보면 결국 전체 트리를 구체적인 기계 명령어로 번역할 수 있다.
- 이 작업을 담당하는 프로그램의 이름이 컴파일러다.
- 이 시점부터 프로그래머는 인간이 인식할 수 있는 언어를 사용하여 코드를 작성할 수 있고, 컴파일러는 이를 CPU가 인식할 수 있는 기계 명령어로 번역하는 역할을 담당
- 해석형 언어의 탄생
- 다양한 CPU가 탄생하게 되는데, 다른 CPU는 자신만의 고유한 언어가 존재
- 각양각색의 CPU마다 상응하는 시뮬레이션 프로그램을 준비하면 우리 코드를 직접 서로 다른 플랫폼에서 실행할 수 있다. CPU 시뮬레이션 프로그램을 가상 머신(virtual machine)이라 한다. 이 가상 머신에는 인터프리터(interpreter)라는 별명도 있다.
- 컴파일러는 언어 구문에 따라 코드 구문을 분석하여 구문 트리로 만들고, 이 구문 트리를 C/C++ 언어처럼 기계어로 번역하여 CPU로 직접 넘기거나 자바처럼 바이트 코드(byte code)로 변환한 후 가상 머신으로 넘겨 실행한다.
- 고급 언어는 추상적 표현이 뛰어나서 사용하기 쉽지만 저수준 계층에 대한 제어 능력이 떨어진다. 따라서 직접 저수준 계층의 세부 사항을 제어할 수 있어야 하는 운영 체제 중 일부분은 어셈블리어로 작성된다.
Section 1.2 컴파일러는 어떻게 작동하는 것일까?
- 컴파일러: 고수준 언어를 저수준 언어로 번역하는 프로그램
- 소스파일(source file): 인간이 인식할 수 있는 테스트 파일 형식
- 소스코드 –> 컴파일러 –> 실행 파일
- 컴파일러가 하는 첫 번째 작업: 소스 코드를 돌아다니면서 모든 토큰을 찾아내는 것
-
토큰(token): 각 항목에 추가로 정보를 결합한 것
토큰 의미 토큰 값 keyword int identifier a assign = -
어휘 분석(lexical analysis): 소스 코드에서 토큰을 추출하는 과정
-
- 컴파일러는 구문에 따라 해석(parsing)해 낸 ‘구조’는 트리로 표현
- 구문 트리: 토큰을 해석한 후 생성된 트리
- 구문 분석: 트리를 생성하는 전체 과정
- 구문 트리가 생성되고 나면 이상이 없는지 확인해야 하는데 이 과정을 의미 분석(semantic analysis)이라고 한다.
- 의미 분석이 끝나면 컴파일러는 구문 트리를 탐색한 결과를 바탕으로 좀 더 다듬어진 형태인 중간 코드(Intermediate Representation Code, IR Code) 생성
- 중간 코드 –> 어셈블리어 코드 –> 기계 명령어
- 컴파일 과정을 거쳐 생성된 기계 명령어가 저장된 파일을 대상 파일(object file)이라 한다.
- 모든 소스 파일에는 각각의 대상 파일이 있다. 이 대상 파일들을 하나의 실행 파일로 합쳐 주는 작업을 링크(link)라고 한다. 링크를 담당하는 프로그램을 링커(linker)라고 한다.
Section 1.3 링커의 말할 수 없는 비밀
- 링커는 컴파일러와 마찬가지로 일반적인 프로그램이다.
- 링커는 컴파일러가 생성한 대상 파일(object file) 여러 개를 하나로 묶어 하나의 최종 실행 파일을 생성
- 링커가 하는 일
- 모듈 사이에 종속성(dependency) 확인
- 참조하고 있는 외부 심벌(external symbol)에 대한 실제 구현이 어느 모듈이든지 단 하나만 있어야 한다. 링커는 이를 찾아내 연결하는 작업을 하는데 이 과정을 심벌 해석(symbol resolution)이라 한다.
- 실행 파일 생성
- 재배치(relocation): 특정한 소스 파일에서 다른 모듈에 정의되어 있는 print() 함수를 참조할 때, 컴파일러가 이 소스 파일을 컴파일하는 시점에는 함수가 어느 메모리 주소(memory address)에 위치할지 정확히 알 수 없다. 따라서 컴파일러는 이 함수를 N으로 표시해 두고 일단 넘어간다. 이후 링크 과정에서 링커가 이런 표시들을 확인하고 한데 모아 실행 파일을 생성하는 과정에서 함수의 정확한 주소를 확인하고, N을 실제 메모리 주소로 대체한다.
- 모듈 사이에 종속성(dependency) 확인
- 심벌 해석
- 심벌: 전역 변수(global variable)과 함수(function)의 이름을 포함하는 모든 변수 이름
- 지역 변수(local variable)는 모듈 내에서만 사용되어 외부 모듈에서 참조할 수 없기 때문에 링커의 관심 대상이 아니다.
- 링커가 해야 할 일은 대상 파일에 참조하고 있는 각각의 모든 외부 심벌마다 대상 정의가 반드시 존재하는지, 단 하나만 존재하는지 확인하는 것
- 링커가 심벌에 대한 정보를 어떻게 알 수 있는가? 컴파일러가 알려준다.
- 컴파일러는 기계 명령어를 생성할 뿐만 아니라 이 명령어를 실행시키는 데이터도 생성하는데, 이 데이터는 대상 파일에 반드시 포함되어야 한다.
- 대상 파일에 포함된 영역
- 명령어 부분: 소스 파일에서 정의된 함수에서 변환된 기계 명령어가 저장되는 부분이다. 코드 영역(code section)이라고 부른다.
- 데이터 부분: 소스 파일의 전역 변수가 저장되는 부분이다. 이 부분을 데이터 영역(data section)이라고 부른다. 참고로 로컬 변수는 프로그램이 실행된 후 스택 영역에 생성되고 사용하면 제거되기 때문에 대상 파일에 별도로 저장하지 않는다.
- 심벌 테이블(symbol table): 외부 심벌 정보를 기록하는 표
- 내가 정의한 심벌, 즉 다른 모듈에서 사용할 수 있는 심벌
- 내가 사용하는 외부 심벌
- 정적 라이브러리, 동적 라이브러리, 실행 파일
- 정적 라이브러리(static library): 소스 파일 여러 개를 미리 개별적으로 컴파일하고 링크하여 정적 라이브러리로 생성할 수 있다. 이 때 소스 파일마다 단독으로 컴파일을 한다는 것이다.
- 정적 라이브러리를 가져와 사용한 코드에서 실행 파일을 생성할 때는 자신의 코드만 컴파일하며, 미리 컴파일이 완료된 정적 라이브러리는 다시 컴파일할 필요 없이 링크 과정에서 그대로 실행 파일에 복제된다. 코드가 의존하는 외부 코드를 매번 컴파일하지 않아도 되기 때문에 컴파일 속도가 빨라진다.
- 정적 링크: 대상 파일에서 데이터 영역과 코드 영역을 결합하는 것
- 정적 링크 단점
- 라이브러리를 실행 파일에 직접 복사하기 때문에 C 표준 라이브러리(C standard library)처럼 거의 모든 프로그램에 적용되는 표준 라이브러리를 사용한다면 정적 링크로 생성된 실행 파일은 모두 동일한 코드와 데이터의 복사본을 갖게 된다. 이 경우 디스크와 메모리를 엄청나게 낭비할 수 있다.
- 정적 라이브러리의 모든 내용에 종속성이 있다고 가정하면, 정적 라이브러리 코드가 변경될 때마다 해당 정적 라이브러리에 종속된 프로그램 역시 매번 다시 컴파일해야 한다.
- 동적 라이브러리(dynamic library): 공유 라이브러리(shared library) 또는 동적 링크 라이브러리(dynamic linked library)라고 한다.
- 정적 라이브러리를 사용하면 정적 라이브러리의 코드 영역과 데이터 영역을 모두 한데 묶어 실행 파일에 복사(copy)한다. 반면에 동적 라이브러리를 사용하면 참조된 동적 라이브러리 이름, 심벌 테이블, 재배치 정보 등 필수 정보만 실행 파일에 포함한다. 정적 라이브러리에 비해 실행 파일의 크기를 확실히 줄일 수 있다.
- 참조된 동적 라이브러리 필수 정보는 실행 파일 내 저장된다. 이 필수 정보는 동적 링크(dynamic linking)이 일어날 때 사용된다.
- 동적 라이브러리에 의존하는 실행 파일에는 컴파일 단계에서 필수 정보만 저장되기 때문에 동적 링크는 실제 프로그램의 실행 시점까지 미룬다.
- 동적 링크에는 두 가지 방식이 있다.
- 프로그램이 메모리에 적재(loading)될 때 동적 링크가 진행
- 적재: 실행 파일을 실행하기 위해 디스크에서 읽어 메모리의 특정 영역으로 이동시키는 과정으로 이 과정에서 적재 도구(loader)라는 전용 프로세스가 실행
- 실행 파일을 적재하고 나면 적재 도구는 실행 파일이 동적 라이브러리에 의존하는지 여부를 확인 후 필요하다면 동적 링커(dynamic linker)라는 별도의 프로세스를 실행해 참조하는 동적 라이브러리 존재 여부와 위치, 심벌의 메머로 위치 등을 확인하여 링크 과정을 마무리한다.
- 프로그램이 먼저 실행된 후, 프로그램의 실행 시간(runtime) 동안 코드가 직접 동적 링크를 실행할 수 있다. 실행 시간 동적 링크(runtime dynamic liking)는 실행 파일이 실행될 때까지 어떤 동적 라이브러리에 의존하는지 알 필요 없기 때문에 좀 더 동적인 링크 방식이다.
- 프로그램이 메모리에 적재(loading)될 때 동적 링크가 진행
- 장점
- 동적 라이브러리를 사용하면 의존하는 프로그램 개수가 얼마나 되었든 상관없이 디스크에 동적 라이브러리의 복사본 하나만 저장한다. 마찬가지로 메모리에 적재되는 동적 라이브러리의 코드 역시 모든 프로세스가 하나의 코드를 공유하기 때문에 하나면 충분하다. 메모리 적재와 디스크 저장에 필요한 리소스를 대폭 절약할 수 있다.
- 동적 라이브러리 코드가 수정된다고 할지라도 해당 동적 라이브러리만 다시 컴파일하면 된다.
- 여러 언어를 혼합하여 개발할 때도 유용하다.
- 단점
- 정적 링크를 사용할 때보다 성능이 약간 떨어진다.
- 특정 메모리 주소와 독립적으로 동작하기 때문이 위치 독립 코드(position-independent code)로 불린다. 동적 라이브러리는 메모리에 단 하나의 복사본만 존재하고 해당 코드는 여러 프로세스가 공유할 수 있기 때문에 동적 라이브러리의 코드는 임의의 메모리 절대 주소(absolute address)로 참조할 수 없다.
- 종속된 동적 라이브러리를 제공하지 않거나 그 버전이 호환되지 않을 경우 프로그램이 실행되지 않는다. 이런 동적 라이브러리 종속성 문제로 프로그램의 설치와 배포에 어려움을 겪을 수 있다.
- 동적 라이브러리를 사용할 때 얻는 이점이 이런 성능 손실보다 더 큰 가치가 있다.
- 정적 라이브러리(static library): 소스 파일 여러 개를 미리 개별적으로 컴파일하고 링크하여 정적 라이브러리로 생성할 수 있다. 이 때 소스 파일마다 단독으로 컴파일을 한다는 것이다.
- 재배치: 심벌의 실행 시 주소 결정하기
- 모든 변수나 함수에 메모리 주소가 있다. 어셈블리어로 작성된 코드를 살펴보면, 명령어에 변수 정보가 전혀 없는 대신 전부 메모리 주소를 사용한다.
- 컴파일러가 대상 파일(object file)에 메모리 주소를 확정할 수 없는 변수를 발견할 때마다
.relo.text에 해당 명령어를 저장하고,.relo.data에 해당 명령어와 관련된 데이터를 저장한다. - 대상 파일에 각 유형의 영역이 모두 결합되면 모든 기계 명령어와 전역 변수가 프로그램 실행 시간에 위치할 메모리 주소를 결정할 수 있다. 이어서 링커는 각 대상 파일의
.relo.text영역을 하나씩 읽어 기계 명령어를 수정해야 하는 심벌이 있으면 심벌의 메모리 주소를 수정한다. - 링커가 프로그램이 실행된 후의 변수나 기계 명령어의 메모리 주소를 확인할 수 있는 이유가 무엇일까? 변수나 명령어의 메모리 주소는 프로그램이 실행될 때마다 변경되기 때문에 실제로 그 시점이 되어야 알수 있다. 링커는 예언자이다.
- 가상 메모리(virtual memory)와 프로그램 메모리 구조
- 프로그램이 실행되면 해당 프로그램의 프로세스(process)가 메모리에 적재
- 프로세스의 형태: 커널 –> 스택 영역(함수 실행 시 정보 저장) <– 힙 영역(동적 메모리 할당) <– 데이터 영역 <– 코드 영역
- 메모리의 상위 주소(higher address)에 스택 영역이 존재한다. 그리고 그 아래에 비어 있는 큰 공간이 존재하고, 이어서 힙 영역이 존재한다. malloc 함수가 바로 이 힙 영역에서 메모리를 할당 받는다. 마지막으로 데이터 영역과 코드 영역은 실행 파일의 내용이 메모리에 적재되는 곳이다.
- 코드 영역이 시작되는 위치는 예외 없이 0x400000에서 시작한다.
- 운영 체제의 가상메모리 기술때문에 가능하다.
- 가상 메모리는 말 그대로 물리적으로 존재하지 않는 가짜 메모리이다. 가상 메모리는 각각의 프로그램이 실행중일 때, 자기 자신이 모든 메모리를 모두 독점적으로 사용하고 있는 것처럼 착각하게 만든다. 예를 들어 32비트 시스템에서는 실제로 시스템에 설치된 물리적 메모리가 얼마가 되었든 자신이 4GB 메모리를 독점하고 있다고 생각한다.
- 모든 프로그램이 동일한 표준적인 메모리 구조를 가질 수 있는 이유다. 링커가 실행 파일을 생성하자마자 실행 시 심벌의 메모리 주소를 결정할 수 있는 것도 프로그램 실행 여부와 관계없이 프로세스 메모리 구조를 알고 있기 때문이다. 코드 영역은 언제나 메모리 주소 0x400000에서 시작하고, 스택 영역은 항상 메모리의 상위 주소에 위치한다.
- 실행 파일을 실행하려면 물리 메모리에 적재되어야 한다. 적재되면 시스템에
가상 메모리 - 물리 메모리매핑 관계가 추가된다. 이런 매핑 관게를 기록한 표를 페이지 테이블(page table)이라고 한다. 각각의 프로세스에는 자신만의 페이지 테이블이 있다.
Section 1.4 컴퓨터 과학에서 추상화가 중요한 이유
- 추상화는 표현력을 크게 향상시키고 의사소통의 효율을 올려 줄 뿐만 아니라 세부 사항을 노출할 필요가 없으므로 보호할 수도 있다.
- 시스템 설계와 추상화
- CPU의 하드웨어는 트랜지스터 여러 개로 구성되어 있지만, 명령어 집합(instruction set)이라는 개념으로 내부 구현 세부 사항을 보호한다. 따라서 프로그래머는 트랜지스터의 세부 사항은 전혀 고려할 필요 없이 명령어 집합에 포함된 기계 명령어를 사용하여 CPU에 작업을 지시하기만 하면 된다. 그리고 기계 명령어에 대한 추상화 계층(abstract layer)은 다시 고급 프로그래밍 언어로 이어진다. 따라서 고급 언어로 프로그래밍 하는 프로그래머는 기계 명령어의 세부 사항에 신경 쓸 필요가 없으며, 고급 언어를 이용하여 CPU를 ‘직접’ 제어할 수 있기 때문에 프로그래밍의 질적 효율성이 크게 높아진다.
- 입출력(input/output) 장치는 파일(file)로 추상화
- 실행 중인 프로그램은 프로세스로 추상화
- 물리 메모리와 파일은 가상 메모리로 추상화
- 네트워크 프로그래밍은 소켓(socket)으로 추상화
- 프로세스와 프로세스의 종속적인 실행 환경은 컨테이너(container)로 추상화
- 추상화는 프로그래머를 저수준 계층에서 점점 더 멀어지게 만들고, 점점 더 저수준 계층의 세부 사항도 신경 쓸 필요가 없도록 만든다. 또 프로그래밍의 문턱도 점점 더 낮추어 컴퓨터 기초가 전혀 없는 사람도 며칠 동안 간단한 학습만으로도 괜찮은 프로그램을 작성하게 해준다. 이것이 추상화의 위력이다.
Chapter 2. 프로그램이 실행되었지만, 뭐가 뭔지 하나도 모르겠다
Section 2.1 운영 체제, 프로세스, 스레드의 근본 이해하기
모든 것은 CPU에서 시작된다
- CPU는 스레드, 프로세스, 운영체제 같은 개념을 전혀 알지 못한다. 단지 다음 두 가지 사항만 알고 있다.
- 메모리에서 명령어(instruction)를 하나 가져온다(dispatch).
- 이 명령어를 실행(execute)한 후 다시 위로 돌아간다.
- CPU는 어떤 기준으로 메모리에서 명령어를 가져올까? PC
- 프로그램 카운터(program counter, PC)라고 불리는 레지스터(register)
- 레지스터: 용량은 매우 작지만 속도는 매우 빠른 일종의 메모리
- PC 레지스터에 메모리에 저장된 명령어 주소가 저장됨
- CPU가 실행하는 명령어는 어디서 오는가?
- 소스파일 –> 컴파일러 –> 실행파일 –> 디스크 –> 메모리 –> CPU
- 우리가 작성하는 프로그램에는 반드시 시작 지점이 있어야 하는데, main 함수가 바로 그것이다. 프로그램이 시작되면 먼저 main 함수에 대응하는 첫 번째 기계 명령어를 찾고, 이어서 그 메모리 주소를 PC 레지스터에 기록한다.
CPU에서 운영 체제까지
- CPU가 프로그램을 실행하게 하려면 실행 파일을 수동으로 메모리에 복사한 후 main 함수에 해당하는 첫 번째 기계 명령어를 메모리에서 찾아 그 주소를 PC 레지스터에 적재하면 된다는 것을 알았다.
- 운영 체제가 없어도 우리가 직접 CPU에 프로그램을 실행하도록 할 수 있다. 하지만 매우 복잡하고 번거롭다.
- 다음과 같은 모든 작업을 직접 해야 한다.
- 프로그램을 적재할 수 있는 적절한 크기의 메모리 영역을 찾는다.
- CPU 레지스터를 초기화하고 함수의 진입 포인트(entry point)를 찾아 PC 레지스터에 설정한다.
- 다음과 같은 단점도 있다.
- 한 번에 하나의 프로그램만 실행할 수 있다. 수동으로 관리해야 하는 시스템은 멀티태스킹(multi-tasking)을 지원할 방법이 없다.
- 모든 프로그램은 사용할 하드웨어를 직접 특정 드라이버와 연결해야 하며, 그렇지 않으면 프로그램이 외부 장치를 전혀 사용할 수 없다.
- print 함수를 사용하려면 직접 구현해야 한다. 최신 운영 체제는 유용한 라이브러리를 다양하게 제공한다.
- 아름다운 상호 작용 인터페이스(interactive interface)를 원한다면 직접 구현해야 한다.
- 다음과 같은 모든 작업을 직접 해야 한다.
- CPU는 한 번에 한 가지 일만 할 수 있다. 따라서 프로그램 A의 기계 명령어를 실행하거나 프로그램 B의 기계 명령어를 실행하는 것 중 하나만 할 수 있다.
- 프로그램 A와 B가 동시에 실행되는 것처럼 보이게 하는 방법: CPU는 먼저 프로그램 A를 실행했다가 이를 잠시 중지하고 프로그램 B의 실행으로 넘어간다. 그리고 프로그램 B를 실행했다가 이를 잠시 중지하고 다시 프로그램 A의 실행으로 돌아갈 수 있다. 이 때 CPU의 전환 빈도가 충분히 빠르다면 ‘동시에 실행’되는 것처럼 보인다.
- 일시 중지했다가 다시 재개할 때 중요한 점은 상태가 유지되고, 유지되었던 상태를 이용하여 다시 재개해야 한다. 이때 저장되는 상태를 상황 정보(context)라고 한다.
- 프로그램 실행 상태를 저장하고 복구할 때 사용할 구조체(structure)의 이름이 프로세스(process)다.
- 이제 모든 프로그램은 실행된 후 프로세스 형태로 관리된다.
- 프로그램을 자동으로 적재해 주는 적재 도구와 멀티태스킹을 실현해 주는 프로세스 관리 도구와 같이 여러 가지 기반 기능의 프로그램을 모아 둔 도구에 이름이 운영 체제(operating system)다.
- 운영 체제가 탄생하면서 프로그래머는 더 이상 실행 파일을 수동으로 적재하거나 프로그램을 수동으로 유지 관리할 필요가 없어졌다. 모든 것을 운영 체제에 맡기기만 하면 된다.
- 최신 운영 체제는 시스템에서 실제로 실행 중인 타 프로세스가 몇 개인지, CPU가 몇 개인지, 물리 메모리의 용량이 얼마인지 신경 쓰지 않고 간단하게 내가 지금 사용하는 프로그램이 CPU와 표준 크기의 메모리를 독점하고 있다고 생각할 수 있다.
- 고급 프로그래밍 언어, 컴파일러, 링커, 운영 체제는 철저하게 프로그래머의 생산성을 발휘할 수 있게 도와주는 초석에 해당하는 소프트웨어 제품군이다.
프로세스는 매우 훌륭하지만, 아직 불편하다
- 운영 체제의 가상 메모리는 각각의 프로세스가 표준적인 메모리 크기를 독점적으로 사용하는 것처럼 보이게 한다.
- 프로세스 주소 공간(process address space): 주소 공간이라고도 한다. 위에서 아래 방향으로 다음과 같다.
- 스택 영역(stack segment): 함수의 실행 시간 스택
- 힙 영역(heap segment): malloc 함수가 요청을 반환한 메모리가 여기에 할당
- 데이터 영역(data segment): 전역 변수 등이 저장됨
- 코드 영역(code segment): 코드를 컴파일하여 생성된 기계 명령어가 저장됨
- funcA와 funcB가 독립적일 때, 전체 실행 속도를 높이는 방법
- 프로세스 A, B를 생성하여 각각 funcA와 funcB의 결과를 얻은 후 프로세스 B의 결과를 프로세스 A로 전달(프로세스 간 통신, IPC)하여 값 두 개를 더하는 것이다.
- 이것이 바로 다중 프로세스 프로그래밍(multi-process programming)이다.
- 다중 프로세스 프로그래밍의 단점
- 프로세스를 생성할 때 비교적 큰 부담(overhead)이 걸린다.
- 프로세스마다 자체적인 주소 공간을 가지고 있기 때문에 프로세스 간 통신은 프로그래밍하기에 더 복잡하다.
- 다중 프로세스 프로그래밍의 단점
프로세스에서 스레드로 진화
- 프로세스의 주소 공간에는 CPU가 실행하는 기계 명령어와 함수가 실행될 때 스택 정보가 저장된다. 프로세스를 실행하려면 main 함수의 첫 번째 기계 명령어 주소를 PC 레지스터에 기록해야 한다. 이 과정을 거치면 명령어 실행 흐름이 형성된다.
- main 함수와 다른 함수 간에 차이점은 없다. main 함수는 프로그램이 시작할 때 CPU가 실행하는 첫 번째 함수라는 점에서 특별하지만, 그 외에 특별할 것이 전혀 없다. PC 레지스터가 main 함수를 가리키게 할 수 있듯이 다른 어떤 함수라도 가리키게 할 수 있으며, 이를 통해 새로운 실행 흐름을 형성할 수 있다.
- 중요한 점은 이런 실행 흐름이 동일한 프로세스 주소 공간을 공유하므로, 더 이상 프로세스 간 통신이 필요하지 않다는 것이다.
- 하나의 프로세스에 진입 함수가 두 개 이상 있을 수 있음을 알았고 하나의 프로세스에 속한 기계 명령어를 CPU 여러 개에서 동시에 실행할 수 있다.
- 공유 프로세스 주소 공간에서 동일한 프로세스에 속한 명령어를 동시에 실행할 수 있다. 다시 말해 하나의 프로세스 안에 여러 실행 흐름이 존재할 수 있다. 이것을 스레드(thread)라고 한다.
- 스레드 두 개를 생성하고, funcA와 funcB를 각각 구분해서 실행한 후 결과를 전역 변수에 저장하고, 마지막으로 이 값을 서로 더하는 방식으로 funcA와 funcB를 동시에 스레드 두 개에서 실행할 수 있다.
- 이상적인 상황에서 이 스레두 두 개가 CPU 코어 두 개에서 동시에 실행된다고 가정하면, 전체 프로그램의 실행 시간은 더 오래 실행되는 함수에 따라 달라진다.
- 여기에서 두 값을 더하는 과정에서 프로세스 간 통신이 일어나지 않는다. 심지어 스레드 사이에는 근본적으로 통신이라는 개념이 존재하지 않는데, 변수가 다중 프로세스 프로그래밍 때처럼 더 이상 서로 다른 주소 공간이 아닌 동일한 프로세스 주소 공간에 속해 있기 때문이다.
- 스레드가 자신이 속해 있는 프로세스의 주소 공간을 공유한다는 의미이며, 이는 스레드가 프로세스보다 훨씬 가볍고 생성 속도가 빠른 이유이기도 하다. 이런 이유로 스레드를 경량 프로세스(light weight process, LWP)라고 한다.
- 스레드라는 개념이 생겼으니, 이제 프로세스를 시작하고 스레드 여러 개를 생성하기만 하면 다중 코어를 충분히 이용하여 모든 CPU를 최대한 활용할 수 있다. 이것이 바로 고성능과 높은 동시성의 기초가 된다.
- 다중 코어가 있어야만 다중 스레드(multi-threading)를 사용할 수 있는 것은 아니며, 단일 코어인 상황에서도 스레드 여러 개를 생성할 수 있다. 이는 스레드가 운영 체제 계층에 구현되며 코어 개수와는 무관하기 때문이다.
- 활용 예: 특정 이벤트 처리하는데 많은 시간이 필요하여 응답이 없는 상황을 방지하고자 해당 이벤트를 처리하는 별도의 스레드를 생성할 수 있다.
- 스레드의 단점
- 다중 스레드가 공유 리소스에 접근할 때 오류가 발생할 수 있다.
- 따라서 프로그래머는 상호 배제(mutual exclusion)와 동기화(synchronization)를 이용하여 다중 스레드 공유 리소스 문제를 명시적으로 직접 해결해야 한다.
다중 스레드와 메모리 구조
- 함수가 실행될 때 필요한 정보에는 함수의 매개변수(parameter), 지역 변수, 반환 주소(return address) 등이 있다. 이런 정보는 대응하는 스택 프레임(stack frame)에 저장되며, 모든 함수는 실행 시에 자신만의 실행 시간 스택 프레임(runtime stack frame)을 가진다.
- 함수가 호출되고 반환될 때마다 이 스택 프레임은 후입선출(last in first out) 순서로 증가하거나 감소하며, 이런 스택 프레임의 증감이 프로세스 주소 공간에서 스택 영역을 형성한다.
- 스레드라는 개념이 존재하기 전에는 프로세스 내에 실행 흐름이 단 하나만 존재했었고, 스택 영역도 하나만 있었다.
- 스레드를 사용한 이래 하나의 프로세스에 실행 진입점(execution entry point)이 여럿 존재할 수 있게 되었고, 동시에 실행 흐름도 여러 개 존재할 수 있다. 각 흐름이 실행될 때 정보를 저장하기 위해 스택 영역이 여러개 필요해졌다. 또 프로세스의 주소 공간에 각 스레드를 위한 스택 영역이 별도로 있어야 한다.
- 즉, 모든 스레드는 각자 자신만의 스택 영역을 가지는데, 스레드가 이를 인지하는게 중요하다.
- 프로세스 주소 공간에 스레드를 생성하면, 프로세스의 메모리 공간이 소모된다.
스레드 활용 예
- 수명 주기(lifecycle) 관점에서 볼 때, 스레드가 처리해야 하는 작업에는 긴 작업(long task)과 짧은 작업(short task)이라는 두 가지 유형이 있다.
- 긴 작업에는 전용 스레드를 생성하는 것이 가장 적합하며, 사실 이런 상황은 비교적 간단하다.
- 짧은 작업이란 네트워크 요청, 데이터베이스 쿼리 처리 시간 등이 있다. 따라서 짧은 작업은 웹 서버, 데이터베이스 서버, 파일 서버, 메일 서버 등 각종 서버에서 많이 볼 수 있다.
- 이런 상황에는 두 가지 특징이 있는데, 하나는 작업 처리에 필요한 시간이 짧다는 것이다. 다른 하나는 작업 수가 엄청나게 많다는 것이다.
- 서버가 하나의 요청을 받으면 해당 작업을 처리하는 스레드를 생성하고 처리가 완료되면 스레드를 종료하면 된다고 간단하게 생각할 수 있다.
- 이 방법은 일반적으로 요청당 스레드(thread-per-request)라고 한다.
- 긴 작업을 대상으로는 매우 잘 동작하고 구현이 간단하다. 하지만 대량의 짧은 작업에서는 다음 몇 가지 단점이 있다.
- 스레드의 생성과 종료에 많은 시간을 허비한다.
- 스레드마다 각자 독립적인 스택 영역이 필요한데, 많은 수의 스레드를 생성하면 메모리와 기타 시스템 리소스를 너무 많이 소비한다.
- 스레드 수가 많으면 스레드 간 전환에 따른 부담이 증가한다.
- 예를 들어 공장의 사장이고, 주문이 매우 많은 상황에 비유할 수 있다. 주문 하나가 새로 추가될 때마다 새로운 근로자를 고용한다. 주문 처리가 완료되면 근로자를 해고하고, 새로운 주문이 들어오면 다른 근로자를 고용한다. 한 번 근로자를 고용한 후 써먹고 나면 바로 해고하는 대신 주문이 들어오면 주문을 처리하고 없을 때 휴식하는 것이 훨씬 더 나은 전략이다.
- 이것이 바로 스레드 풀(thread pool)이 탄생하게 된 이유이다.
스레드 풀의 동작 방식
- 스레드 풀의 개념은 매우 간단하다. 단지 스레드 여러 개를 미리 생성해 두고, 스레드가 처리할 작업이 생기면 해당 스레드에 처리를 요청하는 것이다.
- 스레드 여러 개가 미리 생성되어 있기 때문에 스레드 생성과 종료 작업이 빈번하게 발생하지 않으며, 이와 동시에 스레드 풀 내에 있는 스레드 수도 일반벅으로 일정하게 관리되기 때문에 불필요하게 많은 메모리를 소비하지 않는다. 이 개념에서 중요한 점은 스레드를 재사용하는 것이다.
- 이런 시나리오에 적합한 것은 자료 구조(data structure)의 대기열(queue)이다. 작업을 전달하는 것은 생산자(producer)이며, 작업을 처리하는 스레드는 소비자(consumer)이다. 고전적인 생산자-소비자 패턴(producer-consumer pattern)이다.
- 스레드 풀에 전달되는 작업은 ‘처리할 데이터’와 ‘데이터를 처리하는 함수’ 두 부분으로 구성된다.
- 스레드 풀의 스레드는 작업 대기열(jobs queue)에서 블로킹 상태로 대기한다. 생산자가 작업 대기열에 데이터를 기록하면 스레드 풀의 스레드가 깨어나고, 깨어난 스레드는 작업 대기열에서 처리 함수(handler function)를 실행한다.
- 작업 대기열은 여러 스레드 간에 공유되는 리소스이므로 동기화를 할 때 상호 배제(mutual exclusion in synchronization) 문제도 반드시 처리해야 한다.
스레드 풀의 스레드 수
- 스레드 풀의 수가 너무 적다면 CPU를 최대한 활용할 수 없으며, 너무 많은 스레드를 생성하면 반대로 시스템 성능 저하, 메모리의 과다한 점유, 스레드 전환으로 생기는 부담 등 문제가 발생한다.
- 긴 작업과 짧은 작업으로 분류한 것은 수명 주기 관점에서 작업을 구분한 것이다. 작업을 처리할 때 필요한 리소스 관점에서 구분하자면, CPU 집약적인 작업(CPU intensive task)와 입출력 집약적인 작업(input/output intensive task)으로 구분할 수 있다.
- CPU 집약적인 작업이란 과학 연산, 행렬 연산 등 작업을 처리할 때 외부 입출력에 의존할 필요 없이 처리할 수 있는 작업을 의미한다. 이 경우 스레드 수와 CPU 코어 수가 기본적으로 동일하다면 CPU의 리소스를 충분히 활용할 수 있다.
- 입출력 집약적인 작업이란 연산 부분이 차지하는 시간은 많지 않은 대신 대부분의 시간을 디스크 입출력이나 네트워크 입출력 등에 소비하는 작업을 의미한다. 이 경우 필요한 스레드 수의 계산은 성능 테스트 도구를 사용하여 입출력 대기 시간(WT, wait time)과 CPU 연산에 필요한 시간(CT, computing time)을 평가해야 한다. N개의 코어를 가진 시스템에서 적절한 스레드 수는 대략 N * (1 + WT / CT)이며, WT와 CT가 동일하다고 가정하면 대략 2N개의 스레드가 있어야 CPU 리소스를 최대한 활용할 수 있다. 하지만 이론적인 값에 불과하며, 실제 상황을 기반으로 테스트를 실시하여 필요한 스레드 수를 결정하길 추천한다.
Section 2.2 스레드 간 공유되는 프로세스 리소스
- 프로세스와 스레드의 차이는? 프로세스는 운영 체제가 리소스를 할당하는 기본 단위고, 스레드는 스케줄링(scheduling)의 기본 단위며, 프로세스 리소스는 스레드 간에 공유된다.
스레드 전용 리소스(thread-private resource)
- 상태 변화 관점에서 보면 스레드는 사실 함수 실행이다. CPU는 진입 함수에서 실행을 시작하여 하나의 실행 흐름을 생성하는데, 이 실행 흐름에 인위적으로 스레드라는 이름을 붙인 것에 불과하다.
- 함수의 실행 시간 정보는 스택 영역을 구성하는 스택 프레임에 저장된다. 이때 스택 프레임에 함수의 반환값, 다른 함수를 호출할 때 전달되는 매개변수, 함수 내에서 사용되는 지역 변수와 레지스터 정보가 저장된다.
- 각 스레드는 자신만 사용할 수 있는 스택 영역을 가지므로 스레드 여러 개가 있을 때는 여러 스택 영역이 존재한다.
- 이외에도 다음에 실행될 명령어 주소를 저장하는 PC 레지스터(register), 스레드 스택 영역에서 스택 상단(stack top) 위치를 저장하는 스택 포인터(stack pointer) 등 CPU가 기계 명령어를 실행할 때 내부 레지스터 값도 스레드의 현재 실행 상태에 속한다. 이런 레지스터 정보도 역시 스레드 전용으로, 다른 스레드에서는 이런 레지스터 정보에 접근할 수 없다.
- 이런 정보를 통틀어 스레드 상황 정보(thread context)라고 한다.
- 스레드는 프로세스 주소 공간에서 스택 영역을 제외한 나머지 영역을 모두 공유한다.
코드 영역: 모든 함수를 스레드에 배치하여 실행할 수 있다
- 프로세스 주소 공간의 코드 영역에는 프로그래머가 작성한 코드가 저장된다. 이 영역은 모든 스레드가 공유하는 역역이다.
- 코드 영역은 스레드 간에 공유되므로 어떤 함수든지 모두 스레드에 적재하여 실행할 수 있고, 특정 함수를 특정 스레드에서만 실행되도록 하는 것은 불가능하다.
- 코드 영역은 읽기 전용(read-only)이기 때문에 프로그램이 실행되는 동안에는 어떤 스레드도 코드 영역 내용을 변경할 수 없다.
- 따라서 프로세스 내 모든 스레드가 코드 영역을 공유하고 있지만, 코드 영역에 관해서는 스레드 안전 문제(thread safety issue)가 발생하지 않는다.
데이터 영역: 모든 스레드가 데이터 영역의 변수에 접근할 수 있다
- 데이터 영역은 전역 변수가 저장되는 곳이다.
- 프로그램이 실행되는 동안 데이터 영역 내에 전역 변수 인스턴스(instance, 특정 데이터 정의 따라 메모리상에 저장된 실체)는 하나만 있기 때문에 모든 스레드는 이 전역 변수에 접근할 수 있다.
힙 영역: 포인터가 핵심이다
- C/C++ 언어에서 malloc 함수와 new 예약어로 요청하는 메모리가 이 영역에 할당된다.
- 모든 스레드는 해당 변수 주소만 알고 있다면, 다시 말해 포인터(pointer)를 얻을 수 있다면 포인터가 가리키는 데이터에 접근할 수 있다.
- 따라서 힙 영역은 스레드 간 공유 리소스이다.
스택 영역: 공유 공간 내 전용 데이터
- 서로 다른 프로세스의 주소 공간은 서로 격리되어 있으며, 가상 메모리 시스템은 매우 특별한 경우를 제외하고 다른 프로세스의 주소 공간에 속한 데이터에 직접 접근하지 못하도록 보장한다.
- 하나의 스레드가 다른 스레드의 스택 프레임에서 포인터를 가져올 수 있다면 해당 스레드는 다른 스레드의 스택 영역을 직접 읽고 쓸수 있다. 즉, 다른 스레드의 스택 영역에 속한 변수를 임의로 수정할 수 있음을 의미한다.
- 어떤 면에서 프로그래머에게는 매우 편리하지만, 그와 동시에 해결이 매우 어려운 버그(bug)로 이어질 수 있다.
- 비록 스택 영역은 스레드 전용 데이터에 속하지만, 스택 영역에는 별도의 보호를 위한 작동 방식이 존재하지 않기 때문에 다른 스레드에서 특정 스레드의 스택 영역의 데이터를 읽고 쓸 수 있다.
동적 링크 라이브러리와 파일
- 정적 링크는 종속된 모든 라이브러리가 실행 파일에 포함되는 것을 의미한다. 이와 같은 프로그램의 실행 파일에는 모든 코드와 데이터가 포함되어 있기 때문에 프로그램을 시작할 때 추가적인 작업이 필요하지 않다.
- 동적 링크에는 실행 파일에 종속된 라이브러리의 코드와 데이터가 포함되어 있지 않기 때문에 프로그램을 시작할 때 또는 실행 중일 때 종속된 라이브럴의 코드와 데이터를 찾아서 프로세스 주소 공간에 넣는 링크 과정이 완료되어야 한다.
- 주소 공간에서 이 부분은 모든 스레드가 공유한다. 즉, 프로세스 내 모든 스레드가 동적 라이브러리 코드의 데이터를 사용할 수 있다.
- 프로그램이 동작 중에 특정 파일을 열면 프로세스 주소 공간에 열린 파일 정보도 저장된다. 프로세스가 연 파일 정보는 모든 스레드에서 사용할 수 있으며, 이것 역시 스레드 간 공유 리소스에 속한다.
스레드 전용 저장소(thread local storage)
- 스레드 전용 저장소에 저장되는 변수는 다음과 같은 두 가지 의미가 있다.
- 이 영역에 저장된 변수는 모든 스레드에서 접근할 수 있다.
- 모든 스레드가 동일한 변수에 접근하는 것처럼 보일 수 있지만, 사실 변수의 인스턴스는 각각의 스레드에 속한다. 따라서 하나의 스레드에서 변수 값을 변경해도 다른 스레드에는 반영되지 않는다.
- 스레드 전용 저장소를 사용하면 각각의 스레드에서 독점적으로 변수를 사용할 수 있다. 즉, 이 변수들은 모든 스레드에서 접근할 수 있지만 해당 변수는 초기화한 후 각각의 스레드가 복사본을 가지게 되며, 하나의 스레드에서 변수 값을 변경하더라도 다른 스레드에는 영향을 미치지 않는다.
Section 2.3 스레드 안전 코드는 도대체 어떻게 작성해야 할까?
자유와 제약
- 스레드가 자신만의 전용 데이터를 사용한다면 스레드는 안전하다. 이런 데이터에는 함수의 지역 변수와 스레드 전용 저장소 등이 있다.
- 스레드가 공유 리소스를 사용할 때는 반드시 그에 상응하는 제약이 필요하며, 특정 스레드가 다른 스레드의 공유 리소스 사용 순서를 방해하지 않는 한 스레드 안전을 달성할 수 있다.
- 정리하면,
- 전용 리소스를 사용하는 스레드는 스레드 안전을 달성할 수 있다.
- 공유 리소스를 사용하는 스레드는 다른 스레드에 영향을 주지 않도록 하는 대기 제약 조건에 맞게 공유 리소스를 사용하면 스레드 안전을 달성할 수 있다.
스레드 안전이란 무엇일까?
- 어떤 코드가 주어졌을 때, 그 코드가 스레드 몇 개에서 호출되든 이 스레드들이 어떤 순서로 호출되든 간에 상관없이 올바른 결과가 나온다면, 이 코드를 스레드 안전이라고 말한다.
- 공유 리소스: 정수처럼 단순한 변수일 수도 있고 구조체처럼 데이터일 수도 있다. 가장 중요한 점은 이런 리소스를 여러 리소스에서 읽고 쓸 수 있어야 한다는 것이며, 이 조건을 만족해야만 공유 리소스라고 할 수 있다.
스레드 전용 리소스와 공유 리소스
- 스레드 전용 리소스: 함수의 지역 변수, 스레드의 스택 영역, 스레드 전용 저장소
- 공유 리소스: 그 외의 영역, 주로 힙 영역과 데이터 영역으로 구성
- 공유 리소스를 사용하는 스레드는 반드시 순서를 따라야 하며, 이 순서 핵심은 공유 리소스를 사용하는 다른 작업이 다른 스레드를 방해할 수 없다는 것이다. 그리고 이를 위해 각종 잠금(lock)이나 세마포어(semaphore) 같은 장치를 사용할 수 있다. 이 규칙의 목적은 공유 리소스 순서를 유지하는 것이다.
스레드 전용 리소스만 사용하기
int func() {
int a = 1;
int b = 1;
return a + b;
}
- func 함수는 몇 개의 스레드에서 호출하든 어떻게 호츨하든 언제 호출하든 상관없이 언제나 정확하게 2를 반환한다.
- 이 함수는 어떤 전역 변수나 매개변수에 의존하지 않고 오로지 스레드 전용 리소스인 지역 변수만 사용하는데, 이런 변수는 스레드 스택 영역에서 관리한다.
- 이런 코드를 무상태 함수(stateless function)라고도 하며, 이런 코드가 스레드 안전이라는 것은 분명하다.
스레드 전용 리소스와 함수 매개변수
- 함수에 매개변수를 값으로 전달(call by value)하는 경우라면 문제없으며, 여전히 스레드 안전하다. 이유는 간단하다. 값으로 전달된 매개변수도 스레드 전용 리소스이며, 이 매개변수들도 스레드 자신만의 스택 영역에 저장되기 때문이다.
- 하지만 포인터를 전달하면 더 이상 스레드 안전이 아니다.
- 스레드 안전인 코드를 작성하는 원칙 중 하나는 스레드 간에 공유 리소스를 사용하지 않도록 가능한 한 모든 조치를 취하는 것이다.
전역 변수 사용
- 만약 사용되는 전역 변수가 처음 프로그램이 실행될 때 한 번 초기화되고 나서 모든 코드가 이 변수를 읽기만 한다(마치 전역 변수가 상수처럼 사용)면 문제없다.
- 읽기 전용 전역 변수는 스레드 안전인 공유 리소스
- 읽고 쓰기 가능한 전역 변수는 스레드 안전이 아닌 공유 리소스
스레드 전용 저장소
- 스레드 전용 저장소에 배치된 변수는 스레드 안전이다.
함수 반환값
- 함수가 값을 반환하는 경우(return by value): 스레드 안전
- 함수가 포인터를 반환하는 경우(return by reference): 스레드 안전이 아님
스레드 안전이 아닌 코드 호출하기
- 스레드 안전이 아닌 func 함수가 있다. 이 함수를 호출하기 전에 잠금으로 보호하면 스레드 안전이다. 이유는 잠금으로 전역 변수를 간접적으로 보호하기 때문이다.
int funcA() {
mutex l;
l.lock();
func(); // 스레드 안전이 아닌 함수
l.unlock();
}
-
이 코드를 살펴보자. 매개변수로 전달된 포인터가 전역 변수를 가리키는지 아닌지 알 수 없기 때문에 일반적으로 func 함수가 스레드 안전이 아니라고 생각한다.
int func(int *num) { ++(*num); return *num; }- 하지만 다음과 같이 호출한다면, funcA 함수는 스레드 안전하다. 전달된 매개변수가 스레드 전용 리소스인 지역 변수이기 때문에 funcA 함수를 호출하는 스레드가 몇 개든 서로 간섭하지 않는다.
void funcA() { int a = 100; int b = func(&a); }
스레드 안전 코드는 어떻게 구현할까?
- 스레드 간에 어떤 공유 리소스도 읽거나 쓰지 않는다면 스레드 안전 문제는 있을 수 없다. 공유 리소스가 어느 영역에 저장되어 있든 관계없이 다중 스레드 프로그래밍 중에는 어떤 리소스라도 최대한 공유하지 않는 것이 원칙이다.
- 처리해야 할 작업이 스레드 사이에서 어떤 종류의 리소스를 공유해야 한다면 반드시 코드의 스레드 안전에 주의를 기울여야 한다.
- 스레드 안전을 달성하려면 어떤 것이 스레드 전용 리소스고 어떤 것이 스레드 공유 리소스인지 파악할 필요가 있다.
- 스레드 전용 저장소(thread local storage): 전역 리소스를 사용해야 하는 경우 스레드 전용 저장소로 선언할 수 있는지 확인해 본다. 모든 스레드에서 사용할 수 있지만 각 스레드마다 자체 복사본이 있으며, 이를 변경하더라도 다른 스레드에 영향을 미치지 않기 때문이다.
- 읽기 전용(read-only): 전역 리소스를 반드시 사용해야 한다면 해당 전역 리소스를 읽기 전용으로 사용해도 되는지 확인한다. 다중 스레드에서 읽기 전용 전역 리소스를 사용하더라도 스레드 안전 문제가 발생하지 않는다.
- 원자성 연산(atomic operation): 원자성 연산은 도중에 중단되지 않는다. 따라서 이런 변수에 대한 연산에는 전통적인 방식의 잠금으로 보호가 필요하지 않다.
- 동기화 시 상호 배제(mutual exclusion in synchronization): 이 단계까지 내려왔다면, 한 번에 하나의 스레드만 공유 리소스에 접근할 수 있도록 스레드가 접근하는 공유 리소스 순서를 프로그래머가 어쩔 수 없이 직접 유지해야 하는 상황까지 내몰린 것이다. 뮤텍스(mutex), 스핀 잠금(spin lock), 세마포어(semaphore) 외에 여러 가지 동기화 시 상호 배제를 위한 작동 방식 모두가 이 목적을 이루는 데 사용될 수 있다.
- 지금까지 말하는 스레드는 기본적으로 커널 스레드(kernel thread)를 의미한다. 커널 스레드의 생성, 스케줄링, 종료를 모두 운영 체제가 수행한다. 즉 프로그래머가 스레드가 어떻게 생성되고 스케줄링되는지 전혀 관여할 수 없다는 의미다.
- 운영 체제에 의존하지 않는 상황에서 직접 스레드를 구현할 수 있을까? 가능하다. 바로 스레드보다 더 가벼운 실행 흐름인 코루틴으로 구현할 수 있다.
Section 2.4 프로그래머는 코루틴(coroutine)을 어떻게 이해해야 할까?
일반 함수
def func():
print("a")
print("b")
print("c")
def foo():
func()
일반 함수에서 코루틴으로
- 코루틴에는 스레드와 유사한 기능인 일시 중지와 재개 기능이 있다.
- 코루틴은 자신의 실행 상태를 저장할 수 있기 때문에 코루틴이 반환된 후에도 계속 호출이 가능하며, 더군다나 마지막으로 일시 중지된 지점에서 다시 이어서 실행된다는 점이 놀랍다. 호출한 쪽에서 다시 코루틴을 호출할 때마다 해당 코루틴은 이전에 반환되었던 지점부터 다시 계속 실행되므로
print("b")가 실행된다.
def func():
print("a")
yield # 멈춰라
print("b")
yield # 멈춰라
print("c")
- 일반 함수는 반환된 후 프로세스 주소 공간의 스택 영역에 더 이상 어떤 함수 실행 시 정보도 저장하지 않는다.
- 하지만 코루틴이 반환될 때는 함수의 실행 시 정보를 저장할 필요가 있는데, 코루틴이 실행이 멈추었던 지점에서 다시 실행할 때 이 정보가 필요하기 때문이다.
- 위의 코루틴을 사용하는 방법
def A():
co = func() # 코루틴 획득
next(co) # 코루틴 호출
print("in function A") # 작업 실행
next(co) # 코루틴 재호출
""" 결과
a
in function A
b
"""
직관적인 코루틴 설명
- 일반 함수 호출의 실행 흐름: 먼저 funcA 함수에 도착하여 일정 시간을 실행하다가 도중에 또다른 함수 funcB의 실행 코드를 발견한다. 이 때 제어권은 funcB로 넘어가며 함수 실행이 완료되면 funcA 함수의 호출 지점으로 돌아가서 실행을 계속한다.
- 코루틴 호출의 실행 흐름: funcA 함수는 어느 정도 실행되다가 코루틴을 실행한다. 코루틴이 시작되면 첫 번째 연결 시작 지점까지 실행하다가 funcA 함수로 돌아간다. funcA 함수는 이어서 실행되다 다시 해당 코루틴을 실행한다. 코루틴은 이때부터 일반 함수와 달라지는데, 코루틴은 첫 번째 줄의 코드부터 실행되는 것이 아니라 앞의 연결 시작 지점부터 실행된다. 코루틴은 다시금 두 번째 연결 시작 지점을 만나고, funcA 함수로 돌아간다. 마지막으로 funcA 함수의 나머지 부분이 실행되고 전체 프로그램이 종료된다.
함수는 그저 코루틴의 특별한 예에 불과하다
- 코루틴은 자신이 일시 중지될 때 실행 중인 상태를 저장했다가 저장되었던 상태에서 다시 시작하여 계속 실행된다.
- 운영 체제가 스레드를 스케줄링하는 것과 똑같다. 스레드도 일시 중지될 수 있으며, 운영 체제가 먼저 스레드의 실행 상태를 저장했다가 다른 스레드의 스케줄링을 진행한다. 그리고 일시 중지된 스레드가 다시 CPU의 리소스를 할당받으면 스레드는 마치 일시 중지된 적이 없는 것처럼 이어서 실행한다.
- 컴퓨터 시스템은 주기적으로 타이머 인터럽트(timer interrupt)를 생성하고, 인터럽트가 처리될 때마다 운영체제는 현재 스레드의 일시 중지 여부를 결정할 기회를 가진다. 이것이 바로 프로그래머가 명시적으로 스레드를 언제 일시 중지시키고 CPU의 리소스를 내어 줄지 지정할 필요가 없는 이유다.
- 그러나 사용자 상태(user mode)에서는 타이머 인터럽트를 위한 작동 방식이 없기 때문에 코루틴에서 반드시 yield와 같은 예약어를 사용하여 어디에서 일시 중지하고 CPU의 리소스를 내어 줄 것인지 명시적으로 지정해야 한다.
- 반드시 유일한 점은 코루틴 몇 개를 생성하든 관계없이 운영 체제는 이를 알지 못한다. 코루틴은 온전히 사용자 상태 내에서 구현된 것이기 때문에 코루틴을 사용자 상태 스레드로 해석할 수 있다.
코루틴의 역사
- 코루틴 개념은 1958년에 이미 존재했다. 이는 스레드 개념이 나타나기도 전이다.
- 스레드가 없었기 때문에 동시성을 가지는 프로그램을 작성하려면 어쩔 수 없이 코루틴과 같은 기술을 사용할 수 밖에 없었다.
- 이후 스레드가 등장하고 운영 체제가 기본적으로 프로그램의 동시 실행을 지원하기 시작하면서 코루틴은 프로그래머 기억 속에서 조용히 사라졌다.
- 최근 인터넷이 발달하고, 특히 모바일 인터넷 시대가 되면서 서버에서 처리해야 하는 사용자 요청이 기하급수적으로 늘어나기 시작했다. 이런 상황에서 코루틴은 높은 성능과 동시성을 요구하는 분야에서 자신의 위치를 찾게 됐다.
- 많은 주류 프로그래밍 언어가 이미 코루틴을 지원하고 있거나 앞으로 지원할 계획이다.
코루틴은 어떻게 구현될까?
- 코루틴의 구현은 사실 스레드의 구현과 본질적으로 차이가 없다.
- 코루틴은 일시 중지되거나 다시 시작될 수 있으며, 일시 중지될 때의 상태 정보를 반드시 기록해야 한다. 이를 기반으로 코루틴을 다시 시작해야 한다.
- 상태 정보에는 ‘CPU의 레지스터 정보’, ‘함수 실행 시 상태 정보’가 포함된다. 이는 주로 함수의 스택 프레임에 저장된다.
- 프로세스 주소 공간의 스택 영역은 스레드를 위한 공간이다. 코루틴의 스택 프레임 정보는 어디에 저장해야 할까? 힙 영역에 코루틴의 실행 시간 스택 프레임 정보를 저장하는 메모리를 요청할 수 있다.
- 프로세스 주소 공간의 최상단에 있는 스택 영역의 역할은? 함수 스택 프레임을 보관하는데 사용된다. 단지 이 함수들이 코루틴이 아닌 일반 함수라는 차이가 있다.
- 이론적으로 메모리 공간이 충분하다면 코루틴 개수에 제한은 없으며 코루틴 간 전환이나 스케줄링은 전적으로 사용자 상태에서 일어나기 때문에 운영 체제가 개입할 필요가 없다.
- 또 코루틴 간에 전환할 때 저장 또는 복구되는 정보도 더 가볍기 때문에 효율성도 훨씬 높다.
- 코루틴의 중요한 역할 중 하나는 바로 프로그래머가 동기 방식으로 비동기 프로그래밍을 가능하게 한다는 것이다.
Section 2.5 콜백 함수(callback function)를 철저하게 이해한다
모든 것은 다음 요구에서 시작된다
- A팀과 B팀이 같이 앱을 개발한다고 가정한다. 이 중에서 핵심 모듈(core module)은 B팀이 개발하고 A팀에서는 이를 호출한다. 이 핵심 모듈은 make_donut이라는 함수에 담겨(encapsulation) 있다.
- make_donut 함수에서 비교적 중요한 부분은 도넛 모양을 형성하는 것으로 이는 formed 함수로 구현한다.
- 사업 규모가 확장되 C팀에서도 이 함수를 사용하고 싶어한다. 하지만 C팀에서는 기존 막대 형태의 도넛 대신 원형의 도넛을 이용한 사업을 모색하고 있기 때문에 formed 함수는 A팀과 C팀 양쪽에서 모두 사용할 수 있도록 수정되야 한다.
- if else 문 추가
- 사업이 큰 성공을 거두어, 전 세계적인 인기를 끌게 되었다. 자국 국민의 습관에 따라 현지화(localization)을 거쳐 다양한 도넛 모양을 만들어야 한다.
- if else 문이 수천 개 필요할 뿐만 아니라, 새로운 현지화 요청이 있을 때마다 make_donut 함수를 수정해야 한다.
void make_donut() {
// ...
if (teamA) { form_a(); }
else if (teamC) { form_b(); }
else if (teamD) { ... }
// ...
}
콜백이 필요한 이유
- 프로그래머는 코드를 작성할 때 변수를 자주 사용한다. 그렇지 않으면 코드 전체에서 모두 찾아서 전부 바꾸어야 한다.
- 사실은 함수를 변수처럼 사용할 수 있다.
void make_donut(func f) {
// ...
f();
// ...
}
- make_donut 함수를 사용하고 싶은 프로그래머는 자신이 정의한 현지화 함수를 전달만 하면 되므로, 함수 변수로 한 번에 문제를 해결 할 수 있다.
- 함수 변수를 콜백 함수라고 부른다.
void formed_c() {}
make_donut(formed_c);
- 일반적으로 콜백 함수 코드는 직접 구현한다. 그러나 그 함수를 호출하는 것은 보통 다른 모듈이나 스레드에서 해당 함수를 호출한다.
비동기 콜백
- 사업이 잘되고 주문량이 증가할수록 make_donut 함수의 실행 시간도 점점 더 길어졌다.
- 이 함수를 호출하는 D팀의 코드가 다음과 같이 작성되었다.
// ...
make_donut(formed_d);
something_important(); // 중요 코드
// ...
- something_important 함수가 너무 중요해서 오래 대기 할 수 없다면 어떻게 해야할까? make_donut 함수를 다음과 같이 수정하여 해당 함수 내부에서 스레드를 생성하고 해당 스레드가 실제로 도넛을 형성하게 할 수 있다.
void real_make_donut(func f) {
// ...
f();
// ...
}
void make_donut(func f) {
thread t(real_make_donut, f);
}
- make_donut 함수를 호출하면 해당 함수는 새로운 스레드 t를 생성하고 나서 즉시 반환되고, 이후 something_important() 줄을 실행한다.
- 여기에서 주의할 점은 something_important() 줄의 코드가 실행될 때 실제 도넛 생성 작업은 아직 시작되지 않았을 수도 있다는 것이다. 이것이 비동기(asynchronization)이다.
- make_donut 함수를 호출하고 나서 기다릴 필요가 없으며, 호출자와 피호출자가 각자의 스레드에서 병렬로 실행될 수 있다. 이와 같이 스레드가 콜백 함수 실행에 의존하지 않는 것을 비동기 콜백(asynchronization callback)이라고 한다.
비동기 콜백은 새로운 프로그래밍 사고 방식으로 이어진다
- 함수를 호출할 때 프로그래머에게 가장 익숙한 사고 방식은 다음과 같다.
- 함수를 호출하고 결과를 획득한다.
- 획득한 결과를 처리한다.
- 이것이 바로 함수의 동기 호출(synchronous call)이다.
- 정보 관점에서 보면, 함수는 사실 호출자가 정보를 채워 넣기 전까지는 매개변수 정보가 무엇인지 알 수 없다. 컴퓨터 관점에서 보면, 정보에는 두 가지 유형이 있다.
- 첫 번째 유형은 정수, 포인터, 구조체, 객체 등 데이터
- 두 번째 유형은 함수 같은 코드
- 처리 흐름을 하나의 작업으로 생각할 때,
- 동기 호출 프로그래밍 방식에서는 함수를 호출한 스레드에서 전체 작업 처리
- 비동기 호출 프로그래밍 방식에서는 작업 처리가 두 부분으로 나뉜다.
- 첫 번째 부분은 함수를 호출하는 스레드에서 처리
- 두 번째 부분은 함수를 호출하는 스레드에서 처리되지 않고 다른 스레드, 프로세스 또는 다른 시스템에서 처리
- 두 번째 부분의 호출은 우리가 제어할 수 있는 범위를 벗어나며, 이와 동시에 호출자만 무엇을 해야 할지 알고 있다. 그렇기 때문에 콜백 함수는 꼭 필요한 작동 방식이다.
- 콜백 함수의 본질은 다음과 같다. ‘우리는 어떤 일을 해야 하는지 알지만, 이 일을 언제 하게 될지는 정확히 알 수 없다. 반면에 다른 모듈은 언제 해야 할지는 알지만 무엇을 해야 하는지는 모르게 때문에 우리가 알고 있는 정보를 콜백 함수에 잘 담아 다른 모듈에 전달해야 한다.’
콜백 함수의 정의
- 컴퓨터 과학에서 콜백 함수는 다른 코드에 매개변수로 전달되는 실행 가능한 코드이다.
- 일반적으로 함수 작성자가 나라면 함수를 호출하는 것도 나여야 하지만, 콜백 함수는 그렇지 않다. 함수 작성자가 나라도 함수를 호출하는 것은 내가 아니고 내가 참조하는 외부 모듈이다.
- 서드 파티 라이브러리(third party library)를 예로 들면, 내가 서드 파티 라이브러리의 함수를 호출할 때 콜백 함수를 함께 전달하면 서드 파트 라이브러리의 함수는 내가 작성한 콜백 함수를 호출한다. 서드 파티 라이브러리에 콜백 함수를 지정해야 하는 이유는 서드 파티 라이브러리의 작성자가 특정 시기에 어떤 작업을 수행해야 하는지 알 수 없기 때문이다. 서드 파티 라이브러리의 작성자는 특정한 구현 코드를 작성하는 대신 외부와 연결된 매개 변수를 제공한다. 따라서 서드 파티 라이브러리의 사용자가 콜백 함수를 구현해서 서드 파티 라이브러리에 전달하면, 서드 파티 라이브러리는 특정 시기에 해당 콜백 함수를 호출하기만 하면 된다.
두 가지 콜백 유형
- 동기 콜백은 블로킹 콜백(blocking callback)이라고도 한다.
- 비동기 콜백
- 주 프로그램과 콜백 함수의 실행이 동시에 진행될 수 있기에 보통 주 프로그램과 콜백 함수는 서로 다른 스레드 또는 프로세스에서 실행된다.
- 지연 콜백(deferred callback)이라고도 한다.
- 비동기 콜백은 동기 콜백에 비해 다중 코어 리소스를 더 잘 활용한다. 동기 콜백이 진행되는 동안에 주 프로그램은 아무 일도 못하지만, 비동기 콜백은 이런 문제없이 주 프로그램을 계속 실행한다.
- 비동기 콜백은 입출력 작업에서 자주 볼 수 있으며, 웹 서비스처럼 동시성이 높은 시나리오에 적합하다.
비동기 콜백의 문제: 콜백 지옥
-
비지니스 구성이 상대적으로 복잡한 경우 서비스 호출을 비동기 콜백으로 처리하면 콜백 지옥(callback hell)에 빠질 가능성이 높다.
-
동기 콜백 방식으로 구현하면 다음과 같다.
a = GetServiceA();
b = GetServiceB();
c = GetServiceC();
d = GetServiceD();
- 비동기 콜백 방식으로 구현하면 다음과 같다.
GetServiceA(function(a) {
GetServiceB(a, function(b) {
GetServiceC(b, function(c) {
GetServiceD(c, function(d)) {
// ...
}
})
})
});
- 이처럼 복잡한 비동기 콜백 코드는 주의를 기울이지 않으면 콜백 함정에 빠질 수 있다.
- 비동기 콜백의 효율성, 동기 콜백의 코드 단순성과 가독성을 함께 누릴 수 있는 방법은 바로 코루틴이다.
Section 2.6 동기와 비동기를 철저하게 이해한다
- 동기는 ‘종속적’, ‘연관된’, ‘기다림’ 등 단어들과 엮이는 반면에, 비동기는 ‘비종속적’, ‘무관한’, ‘기다릴필요 없는’, ‘동시 발생’ 등 단어들과 엮이는 경우가 많다.
동기 호출
funcA() {
// funcB 함수가 완료될 때까지 대기
funcB();
// funcB 함수는 프로세스를 반환하고 계속 진행
// ...
}
- 일반적으로 이와 같은 동기 호출에서는 funcA 함수와 funcB 함수가 동일한 스레드에서 실행되는데, 가장 자주 볼 수 있는 상황이다.
- 하지만 비교적 특수한 상황이 하나 있는데 바로 입출력 작업이다.
- 최하단 계층은 실제로 시스템 호출(system call)로 운영 체제에 요청을 보낸다.
- 이때 운영 체제는 파일 읽기 작업을 위해 호출 스레드를 일시 중지 시키며, 커널이 디스크 내용을 읽어 오면 일시 중지되었던 스레드가 다시 깨어난다.
- 이것이 바로 블로킹 입출력(blocking input/output)이다.
- 물론 이것도 동기 호출이다. 단지 호출자와 파일을 읽는 코드가 다른 스레드에서 실행되고 있을 뿐이다.
- 따라서 동기 호출은 호출자와 수신자가 같은 스레드에서 실행 중인지 여부와는 관련이 없다.
비동기 호출
- 일반적으로 비동기 호출은 디스크의 파일 읽고 쓰기, 네트워크 데이터 송수진, 데이터베이스 작업처럼 시간이 많이 걸리는 입출력 작업을 백그라운드 형태로 실행한다.
- 예를 들어 디스크 파일을 읽는 작업이 있다.
- read 함수를 비동기 호출하면 파일 읽기 작업이 완료되지 않은 상태에서도 read 함수는 즉시 반환될 수 있다.
- 이것이 바로 비동기 입출력이다.
- 이 경우 호출자가 블로킹되지 않고 read 함수가 즉시 반환되기 때문에 호출자는 즉시 다음 작업을 실행할 수 있다.
- 그러나 비동기 호출은 프로그래머가 이해하는데 큰 부담이 될 수 있으며, 코드를 작성하는 것은 말할 필요도 없다.
- 비동기 호출 방식에서 작업이 실제로 완료되는 시점은 어떻게 파악할까. 이에 대한 처리는 두 가지 상황이 있을 수 있다.
- 호출자가 실행 결과를 전혀 신경 쓰지 않을 때: 콜백 함수 사용
- 호출자가 실행 결과를 반드시 알아야 할 때: 알림(notification) 작동 방식을 사용
- 즉, 작업 실행이 완료되면 호출자에게 작업 완료를 알리는 신호나 메시지를 보내는 것이다.
- 이 경우 결과 처리는 이전과 마찬가지로 호출 스레드에서 한다.
- 일반적으로 함수의 비동기 호출에는 흔히 스레드 두 개가 사용되는데, 호출자가 하나의 스레드를 사용하고 실제 작업은 다른 스레드에서 실행된다.
웹 서버에서 동기와 비동기 작업
- 일반적으로 웹 서버는 사용자의 요청을 수신하면 전형적인 과정에 따라 그것을 처리하는데, 그중 가장 자주 볼 수 있는 것은 데이터베이스 요청(database query)이다.
- 데이터베이스 요청을 디스크 읽고 쓰기나 네트워크 통신처럼 다른 입출력 작업이라 가정해도 무방하다.
// 사용자 요청을 처리하는데 필요한 단계
A;
B;
C;
데이터베이스 요청;
D;
E;
F;
- 이 중에서 A, B, C, D, E, F 단계에는 입출력 작업이 포함되어 있지 않다. 즉, 파일 읽기나 네트워크 통신 등 작업이 필요없다.
-
동기 방식을 살펴보자. 가장 자연스러우면서 이해하기도 쉽다.
// 메인 스레드 main_thread() { while(1) { 요청 수신; A; B; C; 데이터베이스 요청을 전송하고 결과가 반환될 때까지 대기; D; E; F; 결과 반환; } } // 데이터베이스 스레드 database_thread() { while(1) { 요청 수신; 데이터베이스 처리; 결과 반환; } }- 데이터베이스 요청 후 주 스레드가 블로킹되어 일시 중지되며, 데이터베이스 처리가 완료된 시점에서 이후 단계인 D, E, F가 계속 실행된다.
- 주 스레드에 대기 시간이 존재하며, 이것을 유후 시간(idle time)이라 한다.
- 동기 방식의 첫 번째 상황: 주 스레드가 데이터베이스 처리 결과를 전혀 신경 쓰지 않을 때
- 데이터 베이스 처리가 완료된 후 주 스레드가 아닌 데이터베이스 스레드가 다음 D, E, F 세 단계를 자체적으로 직접 처리한다.
- 위의 처리를 위해 콜백함수를 사용한다.
void handle_DEF_after_DB_query() { D; E; F; } // 주 스레드가 데이터베이스 처리 요청을 보낼 때 이 함수를 매개변수로 전달 DB_query(request, handle_DEF_after_DB_query);- 데이터베이스 스레드는 데이터베이스 요청을 처리한 후 handle_DEF_after_DB_query 함수를 호출하기만 하면 된다.
- 이 함수를 데이터베이스 스레드에 정의하고 직접 호출하는 대신 콜백 함수를 통해 전달받아 실행하는 이유: 소프트웨어 조직 구조 관점에서 볼때, 이 작업은 데이터베이스 스레드에서 해야 할 작업이 아니기 때문이다.
- 주 스레드의 ‘유휴 시간’이 없어진 대신 그 자리를 끊임없는 작업들이 차지하고 있다. 또 데이터베이스 스레드에도 빈 자리가 거의 없이 작업들이 차지하고 있다.
- 이런 설계는 시스템 리소스를 더 많이 최대한 활용할 수 있어 요청 처리 속도가 훨씬 더 빨라진다. 사용자 입장에서 볼 때도 시스템 응답 속도가 더 빨라진다.
- 동기 방식의 두 번째 상황: 주 스레드가 데이터베이스 작업 결과에 관심을 가질 때
- 데이터베이스 스레드는 알림 작동 방식을 이용하여 작업 결과를 주 스레드로 전송해야 한다. 주 스레드는 메시지를 수신하면 이전 사용자 요청의 후반부를 계속 처리한다.
- 데이터베이스 스레드가 유휴 상태라는 점을 제외하면 주 스레드에는 ‘유휴 시간’이 없다.
- 동기 방식의 첫 번째 상황만큼 극단적으로 효율적이지는 않지만, 동기 호출에 비하면 여전히 효율적이다.
- 모든 비동기 호출이 반드시 동기 호출보다 효율적인 것은 아니기 때문에 구체적인 상황에 따라 분석해야 한다.
Section 2.7 아 맞다! 블로킹과 논블로킹도 있다
- 동기 또는 비동기를 이야기할 때 항상 두 가지 대상을 언급한다.
- 동기는 A와 B라는 두 대상이 강하게 결합된 것을 의미한다. 작업 A가 작업 B에 의존하는 경우이며, 이런 의존 관계가 존재할 때 A와 B는 동기이다.
- A와 B가 강한 결합과 같은 제약이 없어 각자 자신의 작업을 실행할 수 있을 때 A와 B는 비동기이다.
블로킹과 논블로킹
- 블로킹(blocking)과 논블로킹(non-blocking)은 프로그래밍에서 함수를 호출할 때 주로 사용된다.
- 함수 A가 함수 B를 호출할 때, 함수 B를 호출함과 동시에 운영 체제가 함수 A가 실행 중인 스레드나 프로세스를 일시 중지시킨다면 함수 B에 대한 호출 방식은 블로킹 방식이며, 그렇지 않다면 논블로킹 방식이다.
- 블로킹 호출 핵심은 스레드 또는 프로세스가 일시 중지되는 것이다.
블로킹의 핵심 문제: 입출력
- 일반적으로 블로킹은 대부분 입출력과 관련이 있다.
- 프로그램, 스레드 또는 프로세스가 입출력 작업을 할 때는 우리 스레드에서 입출력 과정이 실행되는 동안 CPU 제어권을 다른 스레드에 넘겨 다른 작업을 할 수 있도록 해야 한다. 이후 입출력 작업이 완료되면 다시 CPU 제어권을 우리 스레드 또는 프로세스에서 넘겨받아 계속 다음 작업을 실행할 수 있도록 한다.
- 이때 CPU 제어권을 상실했다가 되찾는 시간 동안 스레드나 프로세스는 블로킹되어 일시중지된다.
논블로킹과 비동기 입출력
- 네트워크 데이터 수신을 예로 들어 논블로킹 호출을 살펴본다.
- 데이터를 수신하는 함수인 recv가 논블로킹이면 이 함수를 호출할 때 운영 체제는 스레드를 일시 중지시키는 대신 recv 함수를 즉시 반환한다.
- 이후 호출 스레드는 자신의 작업을 계속 진행하며, 데이터 수신 작업은 커널이 처리한다.
- 두 가지 작업은 병행 처리된다.
- 데이터를 수신했는지는 어떻게 알 수 있을까? 세 가지 방법이 있다.
- 논블로킹 방식의 recv 함수 외에 결과를 확인하는 함수를 함께 제공하고, 해당 함수를 호출하여 수신된 데이터가 있는지 확인
- 데이터가 수신되면 스레드에 메시지나 신호 등을 전송하는 알림 작동 방식 사용
- recv 함수를 호출할 때, 데이터 수신 처리를 담당하는 함수를 콜백 함수에 담아 매개변수로 전달한다. 이때 recv 함수는 콜백 함수를 지원해야 한다.
- 이것이 바로 논블로킹 호출이며, 이런 유형의 입출력 작업을 비동기 입출력(asynchronous input/output)이라고 부른다.
- 블로킹 호출 방식과 비교해 본다면, 비동기 입출력 방식의 코드 작성이 그다지 직관적이지는 않다.
피자 주문에 비유하기
- 블로킹 호출: 피자 가게에 직접 가서 피자를 주문하는 것
- 논블로킹 호출: 전화로 피자를 주문하는 것
- 논블로킹 상황에서 피자가 완성되었는지 어떻게 알 수 있는가?
- 인내심이 강한 경우: 배달이 도착하면 알림이 올 것이기 때문에 할 일을 할 수 있다. 주문자와 피자를 굽는 작업은 비동기이다.
- 인내심이 부족한 경우: 5분마다 전화를 걸어 피자가 완성되었는지 물어본다. 5분 마다 전화는 해야 하지만, 여전히 주문자는 할 일을 할 수 있다. 이때 주문자와 피자를 굽는 작업은 여전히 비동기이다.
- 인내심이 없는 경우: 5분마다 전화를 걸어 피자가 완성되었는지 물어보고, 5분마다 전화하는 일을 제외하고는 아무것도 하지 않는다. 이제 주문자와 피자를 굽는 작업은 더 이상 비동기가 아니라 동기가 된다.
- 논블로킹이 반드시 비동기를 의미하지 않는다.
동기와 블로킹
- 동기는 블로킹과 다소 유사하다.
- 프로그래밍 관점에서 보면, 동기 호출은 반드시 블로킹이 아닌 반면에 블로킹 호출은 모두 확실한 동기 호출이다.
int sum(int a, int b) {
return a + b;
}
void funcA() {
sum(1, 1);
}
- sum 함수에 대한 호출은 동기이지만, funcA 함수가 sum 함수를 호출했다고 해서 블로킹되거나 스레드가 일시 중지되지 않는다.
비동기와 논블로킹
- 예: 네트워크 데이터 수신
-
비동기이자 논블로킹 코드
void handler(void *buf) { // 수신된 네트워크 데이터 처리 } while(true) { fd = accept(); // 데이터를 수신하는 recv 함수 recv(fd, buf, NON_BLOCKING_FLAG, handler); // 호출 후 바로 반환, 논블로킹 }- recv 함수는 논블로킹 호출이므로, 네트워크 데이터를 처리해 주는 handler 함수를 recv 함수에 콜백으로 전달해야 한다.
-
동기이자 논블로킹 코드
void handler(void *buf) { // 수신된 네트워크 데이터 처리 } while(true) { fd = accept(); recv(fd, buf, NON_BLOCKING_FLAG); // 호출 후 바로 반환, 논블로킹 // check 함수: 네트워크 데이터 도착을 감지하는 전용 함수 while(!check(fd)) { // 순환 감지 } handler(buf); }- 여기에서도 recv 함수는 논블로킹으로 호출되지만, while 반복문에서 끊임없이 감지를 시도하여 데이터가 도착하기 전까지는 handler 함수를 사용할 수 없게 된다.
- 이 코드는 반복문에서 CPU 리소스가 쓸데없이 소모되어 매우 비효율적이므로 이런 코드는 작성해서는 안된다.
- 논블로킹이더라도 전체적으로 반드시 비동기라는 의미는 아니며, 이는 코드 구현 방식에 따라 달라진다.
Section 2.8 높은 동시성과 고성능을 갖춘 서버 구현
다중 프로세스
- 가장 먼저 출현한 기술은 가장 간단한 형태의 병행 처리 방식의 일종인 다중 프로세스를 사용하는 것이다.
- 리눅스 세계에서는 fork 방식을 이용하여 여러 자식 프로세스를 생성할 수 있다. 부모 프로세스가 사용자 요청을 먼저 수신하고, 자식 프로세스를 생성해서 해당 사용자의 요청을 처리하도록 한다.
- 이 같은 방식은 모든 요청에 각각 대응하는 프로세스(process-per-connection)가 있다. 장점은 다음과 같다.
- 프로그래밍이 간단하며 매우 이해하기 쉽다.
- 개별 프로세스의 주소 공간은 서로 격리되어 있기 때문에 하나의 프로세스에 문제가 발생하여 강제 종료되더라도 다른 프로세스에는 영향을 미치지 않는다.
- 다중 코어 리소스를 최대한 활용할 수 있다.
- 단점
- 각 프로세스의 주소 공간이 서로 격리되어 있어, 프로세스 간에 서로 통신이 필요할 때 난이도가 더 올라가며, 프로세스의 통신 작동 방식을 사용해야 한다.
- 프로세스를 생성할 때 부담이 상대적으로 크고, 프로세스의 빈번한 생성과 종료는 의심의 여지없이 시스템 부담을 증가시킨다.
다중 스레드
- 스레드는 프로세스 주소 공간을 공유하기 때문에 스레드 간 통신을 위해 별도의 통신 작동 방식을 사용할 필요가 없다.
- 스레드는 집을 등에 지고 다니는 소라게와 비슷하다. 집에 해당하는 주소 공간은 프로세스가 소유하고 있으며, 스레드 자신은 집을 빌린 임차인에 불과하다. 따라서 매우 가벼울 뿐만 아니라 생성과 종료에 드는 부담이 적다.
- 각 요청에 대응하는 스레드(thread-per-connection)를 생성할 수 있으며, 설령 파일 읽기와 같은 입출력 작업으로 스레드 중 일부가 블로킹되어 일시 중지되더라도 다른 스레드에 영향을 미치지 않는다.
- 스레드는 프로세스 주소 공간을 공유하기 때문에 스레드 간 ‘통신’에 있어 편리함을 제공하지만 그와 동시에 수많은 문제를 일으키기도 한다.
- 스레드는 서로 같은 주소 공간을 공유하기 때문에 하나의 스레드에 문제가 발생하여 강제 종료되면 같은 프로세스를 공유하는 모든 스레드와 프로세스가 한꺼번에 강제 종료된다.
- 또한 여러 스레드가 동시에 공유 리소스의 데이터를 읽고 쓸 수 없다는 부작용이 있습니다. 공유 데이터의 주소를 동시에 쓰려고 하면 스레드 안전 문제가 발생하므로 반드시 동기화 시 상호 배제와 같은 작동 방식을 사용해야 한다. 더군다나 교착 상태처럼 일련의 문제를 일으킬 수 있어 다중 스레드가 일으키는 이런 문제를 해결하는 데 프로그래머의 귀중한 시간 중 상당 부분을 할애해야 한다.
- 이렇듯 스레드에도 단점이 있기는 하지만 다중 프로세스와 비교할 때 스레드가 훨씬 더 유리한 고지를 점령하고 있다. 사용자 규모가 크지 않은 경우 다중 스레드로도 충분히 처리 가능하다. 하지만 동시 요청 수가 매우 많을 때는 다중 스레드만으로 감당하기가 어렵다.
이벤트 순환과 이벤트 구동
- 지금까지는 ‘병행’이라는 단어를 언급할 때 프로세스와 스레드를 떠올렸다.
- 병행 프로그래밍을 위한 또 하나의 기술은 GUI 프로그래밍과 서버 프로그래밍에서 널리 사용되는 이벤트 기반 동시성(event-based concurrency)을 이용한 이벤트 기반 프로그래밍(event-driven programming)이다.
- 이벤트 기반 프로그래밍 기술의 두 가지 요소
- 이벤트(event): 서버에서 말하는 이벤트는 대부분 입출력에 관계된 것이다. 예를 들어 네트워크 데이터의 수신 여부, 파일의 읽기 및 쓰기 가능 여부 등이 관심 대상인 이벤트에 해당한다.
- 이벤트를 처리하는 함수: 이 함수를 일반적으로 이벤트 핸들러(event handler)라고 한다.
- 이벤트가 도착하면 이벤트 유형을 확인한 후 해당 유형에 대응하는 이벤트 처리 함수인 이벤트 핸들러를 찾은 후 직접 이벤트 핸들러를 호출하면 된다.
-
기본적으로 이벤트는 계속 발생할 수 있다. 서버에서 이벤트는 바로 사용자 요청이며, 이 이벤트를 계속 수신하고 처리해야 한다. 따라서 while 또는 for 반복문을 사용하여 반복적으로 처리할 필요가 있다. 이 반복을 이벤트 순환(event loop)이라고 한다.
- 의사 코드를 이용하여 이벤트 순환을 표현
while(true) {
event = getEvent(); // 이벤트 수신 대기
handler(event); // 이벤트 처리
}
- 이벤트 순환에서 수행해야 하는 작업은 매우 간단하다. 이벤트가 도착할 때까지 기다렸다가 대응하는 이벤트 핸들러를 호출하면 된다.
- 하지만, 해결해야 할 두 가지 문제가 있다.
- 이벤트 소스에 관한 문제이다. 앞의 의사 코드에 있는 getEvent 같은 함수 하나로 어떻게 여러 이벤트를 가져올 수 있을까? 서버 프로그래밍 분야의 해결책은 입출력 다중화(input/output multiplexing) 기술
- 이벤트를 처리하는 handler 함수가 반드시 이벤트 순환과 동일한 스레드에서 실행되어야 할까?
첫 번째 문제: 이벤트 소스와 입출력 다중화
- 리눅스와 유닉스 세계에서는 모든 것이 파일로 취급된다.
- 프로그램은 모두 파일 서술자(file descriptor)를 사용하여 입출력 작업을 실행하며, 소켓(socket)도 예외는 아니다.
- 사용자 연결이 열 개고 이에 대응하는 소켓 서술자가 열 개 있는 서버가 데이터를 수신하려고 대기 중이라고 가정한다. 이를 처리하는 가장 간단한 방법은 다음과 같다.
recv(fd1, buf1);
recv(fd2, buf2);
recv(fd3, buf3);
recv(fd4, buf4);
// ...
- 이와 같이 지나치게 단순한 코드는 분명 문제가 있다. 첫 번째 사용자가 데이터를 보내지 않는 한 recv(fd1, buf1) 코드는 반환되지 않으므로 서버가 두 번째 사용자의 데이터를 수신하고 처리할 기회가 사라진다.
- 더 나은 접근 방식은 운영 체제에 다음 내요을 전달하는 작동 방식을 사용하는 것이다. ‘저 대신 소켓 서술자 열 개를 감시하고 있다가, 데이터가 들어오면 저에게 알려 주세요.’ 이런 작동 방식을 입출력 다중화라고 하며, 이와 같은 작동 방식 중 리눅스 세계에서 제일 유명한 것이 바로 epoll이다.
// epoll 생성
epoll_fd = epoll_create();
// 서술자를 epoll이 처리하도록 지정
Epoll_ctl(epoll_fd, fd1, fd2, fd3, fd4, ...);
while(1) {
int n = epoll_wait(epoll_fd);
for(i = 0; i < n; i++) {
// 특정 이벤트 처리
}
}
- epoll은 이벤트 순환을 위해 탄생했다.
두 번째 문제: 이벤트 순환과 다중 스레드
- 이벤트 핸들러에 다음 두 가지 특징이 있다고 가정해보자.
- 입출력 작업이 전혀 없다.
- 처리 함수가 간단해서 소요 시간이 매우 짧다.
- 이벤트 핸들러와 이벤트 순환을 동일한 스레드에서 실행할 수 있다.
- 이 경우 요청은 순차적으로 처리되는데, 모든 요청이 단일 스레드에서 순차적으로 처리된다.
- 요청을 처리하는 데 시간이 걸리지 않는다는 것을 전제로 하기에 서버는 짧은 시간에도 많은 요청을 처리할 수 있다. 또 요청이 순차적으로 처리되더라도 사용자 입장에서는 응답이 눈에 띄게 지연된다고 느낄 일은 없다.
- 그런데 사용자 요청을 처리하는 데 CPU 시간을 많이 소모한다면 어떻게 해야 할까?
- 이때도 여전히 단일 스레드를 사용하고 있다면 사용자는 시스템 응답이 너무 느리다고 불평할 것이다.
- 따라서 요청의 처리 속도를 높이고 최신 컴퓨터 시스템의 다중 코어를 최대한 활용하려면 다중 스레드의 도움이 필요하다.
- 이제 이벤트 핸들러는 더 이상 이벤트 순환과 동일한 스레드에서 실행되지 않고 독립적인 스레드에 배치된다.
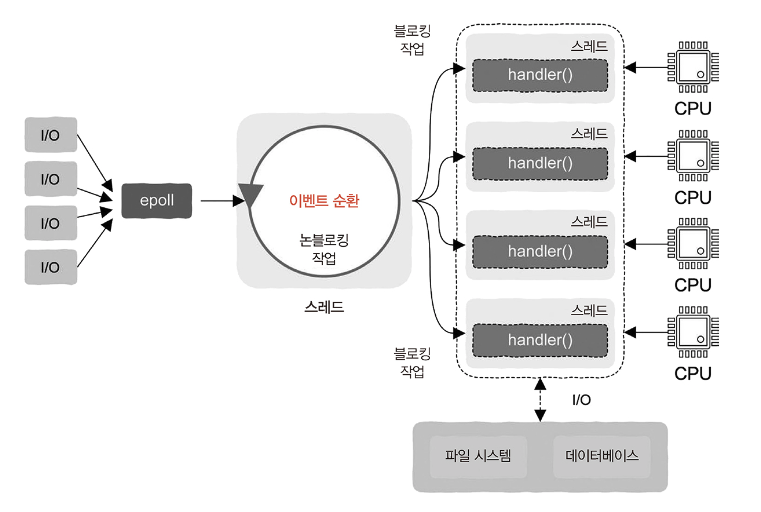
- 작업자 스레드(worker thread) n 개와 이벤트 순환 스레드(event loop thread) 한 개가 생성되는데, 이벤트 순환은 요청을 수신하면 간단한 처리 후 바로 각각의 작업자 스레드에 분배할 수 있다.
- 다중 스레드를 이용한 병행 실행은 시스템의 다중 코어를 최대한 활용하여 요청 처리를 가속화한다. 물론 이 작업자 스레드를 스레드 풀(thread pool)로 구현하는 것도 가능하다.
- 이런 설계 방법을 반응자 패턴(reactor pattern)이라고 한다.
이벤트 순환과 입출력
- 상황을 업그레이드하여 좀 더 복잡하게 바꾸어 보자. 요청 처리 과정에 입출력 작업도 포함된다고 가정해 보자.
- 이때 입출력 작업도 두 가지 상황으로 나누어 이야기해야 한다.
- 입출력 작업에 대응하는 논블로킹 인터페이스가 있는 경우: 이때는 직접 논블로킹 인터페이스를 호출해도 스레드가 일시 중지되지 않으며, 인터페이스가 즉시 반환되므로 이벤트 순환에서 직접 호출하는 것이 가능하다.
- 입출력 작업에 블로킹 인터페이스만 있는 경우: 이때는 이벤트 순환 내에서 절대로 어떤 블로킹 인터페이스도 호출하면 안된다. 절대로! 그렇지 않으면 이벤트 순환 스레드가 일시 중지될 수 있으며, 이는 이벤트 순환이라는 엔진이 멈추는 것에 해당하기 때문에 전체 시스템이 모두 앞으로 나아갈 수 없게 된다. 따라서 블로킹 입출력 호출이 포함된 작업은 작업자 스레드에 전달해야 한다. 그래야만 이 작업으로 해당 작업자 스레드가 일시 중지되더라도 다른 작업자 스레드에 문제를 일으키지 않는다.
- 사실 전체적인 프레임워크만 확정되어 있다면 개발자는 handler 함수에 대한 프로그래밍만 하면 된다.
비동기와 콜백 함수
- 프로젝트 초기에는 handler 함수 기능이 데이터베이스를 처리하여 반환하는 것처럼 매우 간단할 수 있지만, 비지니스가 발전하면서 서버 기능은 점점 더 복잡해졌다.
- 보통 서버 기능은 용도에 따라 여러 부분으로 나뉠 수 있으며, 각 부분은 별도의 서버에 배치된다.
- 예를 들어 사용자가 전자 상거래 앱에서 상품을 검색할 때, 하나의 검색 요청에 네 가지 백엔드(backend) 서비스가 관여한다고 가정해보자.
- 먼저 검색 서버로 요청이 전송되면 간단한 처리를 진행한 후 서버 A에 사용자 프로필과 같은 상세 정보를 요청한다. 다음으로 사용자의 검색어와 서버 A에서 얻은 사용자 프로필을 결합하여 서버 B에 상품 검색을 요청한 후 다시 서버 C에 재고 여부를 조회하여 일치하는 상품 정보를 가져온다. 마지막으로 검색 서비스는 최종 결과에서 재고가 없는 상품을 필터링한 최종 결과를 사용자에게 반환한다.
- 서버는 일반적으로 원격 프로시저 호출(remote procedure call, RPC)을 통해 통신한다.
- RPC는 네트워크 설정, 데이터 전송, 데이터 분석 등 지루한 작업을 담아 프로그래머가 일반 함수를 호출하는 것 처럼 네트워크로 통신할 수 있도록 한다.
GetUserInfo(request, response);
- 외부에서 보면 일반적인 함수이지만, 이 함수의 최하위 계층에서는 네트워크 통신을 수행할 수 있다. 대상 서버에 요청을 보내고 그 응답을 받아 매개변수 response에 저장한다.
- 해당 서버에 대응하는 handler 함수는 다음과 같이 작성할 수 있다.
void handler(request) {
A;
B;
GetUserInfo(request, response); // 서버 A에 요청
C;
D;
GetQueryInfo(request, response); // 서버 B에 요청
E;
F;
GetStockInfo(request, response); // 서버 C에 요청
G;
H;
}
- 이 중에서 Get으로 시작하는 것은 RPC 호출이다. 주의할 점은 이 RPC 호출들은 모두 블로킹 호출이 때문에 사용자가 응답하기 전에는 함수가 반환되지 않는다.
- 위의 handler 함수 구현 방법의 장점은 코드가 명확하고 이해하기 쉽다는 것이다. 반면에 유일한 문제는 불로킹 호출로 스레드가 일시 중지될 수 있고 블로킹 호출이 여러 번 발생하면 스레드가 빈번하게 중단될 수 있다는 것이다.
- 따라서 동기 방식의 RPC 호출을 비동기 호출로 수정해야 한다.
- 비동기 호출은 호출 스레드를 블로킹하지 않기 때문에 함수가 즉시 반환된다. 단, 함수가 반환될 때 사용자 응답에 대한 결과가 없을 수 있다. 이때는 반드시 Get* 함수를 호출한 후 처리할 내용을 콜백 함수에 담아 RPC 호출에 포함한다.
void handler_after_GetStockInfo(response) {
G;
H;
}
void handler_after_GetQueryInfo(response) {
E;
F;
GetStockInfo(request, handler_after_GetStockInfo); // 서버 C에 요청
}
void handler_after_GetUserInfo(response) {
C;
D;
GetQueryInfo(request, handler_after_GetQueryInfo); // 서버 B에 요청
}
void handler(request) {
A;
B;
GetUserInfo(request, handler_after_GetUserInfo) // 서버 A에 요청
}
- 이제 주 프로세스는 네 개로 분할되고, 콜백 안에 콜백이 포함되었다. 하지만 사용자 서비스가 더 많아지면 이런 형태의 코드는 거의 관리가 불가능하다. 설녕 비동기 프로그래밍이 시스템 리소스를 더 잘활용한다고 해도 말이다.
- 비동기 프로그래밍의 효율성과 동기 프로그래밍의 단순성을 결합한 기술인 코루틴으로 이 문제를 해결할 수 있다.
코루틴: 동기 방식의 비동기 프로그래밍
- handler 함수를 코루틴에서 실행한다.
void handler(request) {
A;
B;
GetUserInfo(request, response); // 서버 A에 요청
C;
D;
GetQueryInfo(request, response); // 서버 B에 요청
E;
F;
GetStockInfo(request, response); // 서버 C에 요청
G;
H;
}
- handler 함수의 코드 구현은 동기로 작성한다. 하지만 yield로 CPU 제어권을 반환하는 등 RPC 통신이 시작된 후 적극적으로 바로 호출된다는 점은 다르다.
- 코루틴이 일시 중지되더라도 작업자 스레드가 블로킹되지 않는다. 이것이 코루틴과 스레드를 사용하는 블로킹 호출의 가장 큰 차이점이다.
- 코루틴이 일시 중지되면 작업자 스레드는 준비 완료된 다른 코루틴을 실행하기 위해 전환되며, 일시 중지된 코루틴에 할당된 사용자 서비스가 응답한 후 그 처리 결과를 반환하면 다시 준비 상태가 되어 스케줄링 차례가 돌아오길 기다린다. 이후 코루틴은 마지막으로 중지되었던 곳에서 이어서 계속 실행된다.
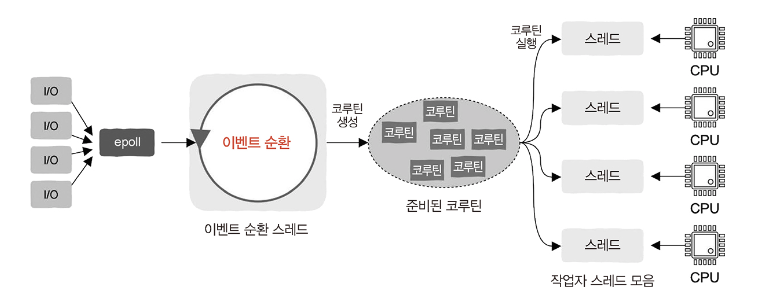
- 이벤트 순환은 요청을 받은 후 handler 함수를 코루틴에 담아 스케줄링과 실행을 위해 각 작업자 스레드에 배포
- 작업자 스레드는 코루틴을 획득한 후 진입 함수인 handler를 실행
- 어떤 코루틴이 RPC 요청으로 능동적으로 CPU의 제어권을 반환하면 작업자 스레드는 준비 상태인 다른 코루틴 실행
- 코루틴이 블로킹 방식으로 RPC 호출을 하더라도 작업자 스레드는 블로킹 되지 않기 때문에 시스템 리소스를 효율적으로 사용할 수 있다.
CPU, 스레드, 코루틴
- CPU, 스레드, 코루틴은 서로 다른 계층 구조에 위치한다.
- 하드웨어: CPU
- 기계 명령어를 실행하여 컴퓨터를 움직이게 한다.
- 커널 상태: 스레드
- 커널 상태 스레드라고 하며, 커널로 생성되고 스케줄링 한다.
- 커널은 스레드 우선순위에 따라 CPU 연산 리소스를 할당한다.
- 사용자 상태: 코루틴
- 커널 입장에서 알 수 없는 요소로, 코루틴이 얼마나 많이 생성되었든 커널은 이와 관계없이 스레드에 따라 CPU 시간을 할당한다.
- 스레드에 할당된 CPU 시간을 사용자 상태에서 재차 할당하는 것이다. 이 할당은 사용자 상태에서 발생하므로 코루틴을 사용자 상태 스레드라고도 한다.
- 하드웨어: CPU
Section 2.9 컴퓨터 시스템 여행: 데이터, 코드, 콜백, 클로저에서 컨테이너 가상 머신까지
코드, 데이터, 변수, 포인터
- 메모리가 코드로 구성된 명령어 외에 명령어가 작동하는데 필요한 데이터도 저장할 수 있다.
- 메모리에 저장된 데이터는 구조체인 인스턴스일 수도 있고, 객체일 수도 있으며, 배열일 수도 있다. 이러한 데이터를 변수라고 한다.
- 여러 변수를 사용하여 동일한 데이터를 참조할 수 있다.
- C 언어에서는 포인터(pointer)라고 한다.
- 포인터 개념을 사용하지 않는 언어에서는 참조(reference)라고 한다.
콜백 함수와 클로저
- 동일한 데이터를 참조하는 변수가 여러 개 있을 수 있듯이, 변수 여러 개가 동일한 코드를 참조할 수 있다.
- 특정 언어에서는 코드를 할당, 사용, 매개변수로 전달, 반환값으로 사용 등 일반 변수를 다루듯이 처리할 수 있을 때 일급 객체 함수(first-class function)라고 한다.
- C 언어에서는 함수가 일급 객체가 아니기 때문에 함수에서 다른 함수를 반환할 수 없다.
- 파이썬에서는 함수가 일급 객체이므로 함수를 일반 변수처럼 반환할 수 있다.
- 함수가 다른 함수에 매개변수로 전달될 때 해당 함수를 콜백 함수(callback function)라고 한다.
- 콜백 함수는 실제로 코드 정의는 A에서 하지만 호출은 B에서 하는 것처럼 정의와 호출을 서로 다른 곳에서 한다.
- 하지만 때로는 코드가 A에서 정의될 뿐만 아니라, A에서 생성된 데이터를 사용할 수 있어야 할 때가 있다.
- 콜백 함수를 일부 데이터와 한데 묶어 변수로 취급할 때 클로저(closure)가 탄생한다.
def add():
b = 10
def add_inner(x):
return b + x
return add_inner
f = add()
print(f(2))
- add_inner 함수는 두 가지 데이터를 사용한다. 하나는 add 함수 내에서 정의된 b 변수고, 다른 하나는 사용자가 전달하는 매개변수로 여기서는 2가 그 값에 해당한다.
- f 함수가 호출되어야 add_inner 함수에 필요한 모든 데이터를 얻을 수 있다.
- add_inner 함수는 단순한 코드일 뿐만 아니라 실행 시간 환경인 b 변수를 묶어서 전달하는 클로저이기도 하다.
컨테이너와 가상 머신 기술
- 어떤 함수가 CPU를 능동적으로 일시 중지하고 다음에 함수가 다시 호출될 때 앞에서 중단된 지점에서 계속 실행하는 것이 가능할 때, 이 함수가 바로 코루틴에 해당한다.
- 함수의 일시 중지와 재개가 커널 상태에서 구현되는 경우에는 스레드라고 한다.
- 스레드에 주소 공간처럼 종속된 실행 시 리소스를 결합한 것이 프로세스다.
- 프로그램이 구성, 라이브러리처럼 프로그램이 의존하는 실행 환경과 묶인 것을 컨테이너(container)라고 한다.
- 컨테이너는 일종의 가상화 기술로서 운영 체제를 가상화한다.
- 컨테이너는 운영체제에서 제공하는 기능을 이용하여 프로세스를 격리하고 CPU, 메모리, 디스크에 대한 접근을 제어하는 방식으로 컨테이너에 포함된 프로세스가 전체 운영 체제 안에서 자기 자신의 프로세스만 존재하고 있다고 간주하게 한다.
- 컨테이너를 넘어 좀 더 넓은 범위의 가상화 기술을 사용하면 소프트웨어뿐만 아니라 하드웨어도 가상화할 수 있다.
- 가상화 기술은 소프트웨어를 이용하여 컴퓨터의 하드웨어를 추상화하고, 하드웨어 리소스를 가상 컴퓨터 여러 개로 나눈다. 그리고 그 위에 운영 체제를 실행하면 이 운영 체제는 하드웨어의 리소스를 가져와 사용할 수 있게 된다.
- 바로 가상 머신 감시자(virtual machine monitor)가 이런 작업을 하는 소프트웨어로 흔히 이를 하이퍼바이저(hypervisor)라고 한다.
- 가상 머신 감시자에서 실행되는 운영 체제를 가상 머신이라고 한다.
- 소프트웨어를 사용하면 하나의 추상화 계층 위에 또 다른 추상화 계층을 상대적으로 쉽게 올릴 수 있다.
Chapter 3. 저수준 계층? 메모리라는 사물함에서부터 시작해보자
CPU는 메모리 도움 없이는 동작이 불가능하다. 컴퓨터 시스템에서 연산과 저장을 담당하는 것은 각각 CPU와 메모리이다.
Section 3.1 메모리의 본질, 포인터와 참조
메모리의 본질은 무엇일까? 사물함, 비트, 바이트, 객체
- 가장 작은 단위를 기준으로 본다면 메모리도 사물함 형태의 구성을 하고 있지만, 메모리에서는 사물함 대신 메모리 셀(memory cell)이라는 표현을 사용한다.
- 메모리 셀에는 0과 1만 보관할 수 있다. 0과 1을 가르켜 1비트(bit)라고 한다.
- 더 많은 정보를 표현하려면 더 많은 비트가 필요하므로 비트 여덟 개를 묶어 정보를 나타내는 하나의 단위인 1바이트(byte)를 사용한다.
- 각 바이트마다 번호를 붙인다. 모든 바이트는 메모리 내 자신의 주소를 가지고 있으며 이 주소를 메모리 주소(memory address)라고 한다.
- 메모리 주소 한 개를 사용하여 특정한 사물함 여러 개를 찾을 수 있으며, 이를 주소 지정(addressing)이라고 한다.
- 하지만 1바이트 역시 8비트이기 때문에 정보를 표현하는 능력에 한계가 있다.
- 8비트로 만들 수 있는 조합은 $2^8$인 256개에 불과하므로 이를 부호 없는 정수(unsigned integer)로 표현하면 0부터 255까지 숫자만 표현 가능하다.
- 따라서 일반적으로 4바이트를 묶어 하나의 정수로 표현하는 단위로 사용
- 4바이트는 32비트로 $2^32$개, 즉 4,294,967,296개의 조합이 가능하기 때문이다.
- 서로 다른 정보 세 개를 표현하려면 12바이트가 필요하다. 12바이트를 사용해서 정보를 조합하여 표시하는 것을 프로그래밍 언어에서 구조체(structure) 또는 객체(object)라고 표현한다.
메모리에서 변수로: 변수의 의미
- 1 + 2 값을 계산하고 싶다고 가정해보자.
- 먼저 숫자 1과 숫자 2를 메모리에 저장해야 한다. CPU는 메모리에서 값을 읽어 레지스터에 저장해야 연산을 수행할 수 있다.
- 먼저 숫자 1을 6번 사물함에 넣는다. 메모리에 정보를 저장할 때 store 명령어를 사용한다.
store 1 6
- 읽기는 load 명령어를 사용한다.
load r1 6- 6번 사물함에 저장된 숫자를 r1 레지스터에 읽어 오기
- 숫자들이 값과 메모리 주소를 모두 나타낼 수 있기 때문에 해석이 모호해진다. $ 기호가 있으면 값이고, 없다면 메모리 주소를 의미한다.
store $1 6load r1 6
- 하지만 ‘주소 6’이라는 표현은 인간에게 익숙하지 않다. 부르기 쉬운 별칭을 붙여보자.
- ‘주소 6’에 a라는 이름을 붙인다.
- a에 저장된 값이 바로 1이다.
a = 1
- 이렇게 변수라는 단어가 탄생했다.
- 변수 a의 뒤에는 다음과 같은 두 의미가 있다.
- 값 1을 나타낸다.
- 이 값은 메모리 주소 6에 저장된다.
- 변수 a의 뒤에는 다음과 같은 두 의미가 있다.
- 다음과 같은 표현을 추가해보자.
b = a- b 변수를 위해 2번 사물함에 b 변수를 저장한다.
- a 변수의 숫자 데이터를 완전히 복제했다.
- a 변수가 1 바이트의 데이터뿐만 아니라 구조체나 객체처럼 여러 바이트를 차지한다고 가정한다.
- 이제 a 변수는 5바이트를 차지하며, 이제는 전체 메모리의 절반 이상에 해당한다.
- 이런 상황에서 b = a를 표현해야 한다면, 메모리 공간이 부족하다.
- 전체 메모리 크기가 8바이트에 불과한데, 복사 방법을 사용하면 두 변수가 나타내는 데이터만으로도 이미 10바이트를 차지하기 때문이다.
변수에서 포인터로: 포인터 이해하기
- 메모리 주소만 알고 있으면 해당 데이터를 찾을 수 있다.
- 메모리 주소 역시 하나의 숫자로 이 역시 해당 데이터가 차지하고 있는 메모리 공간 크기와는 무관하다.
- 만약 b 변수도 a 변수를 가리키고 있다면 굳이 불필요한 데이터의 복사본을 만들 필요가 없다. 그 주소를 저장하면 된다.
- a 변수는 메모리 주소 3에 위치하고 있으므로 b 변수에는 숫자 3을 저장할 수 있다.
- b 변수가 저장하고 있는 숫자는 더 이상 값으로 해석되지 않고 메모리 주소로 해석된다.
- 변수가 값뿐만 아니라 메모리 주소까지 저장할 수 있게 되면서 포인터가 탄생했다.
- 포인터를 주소 자체라고 언급할 때가 많이 있는데, 사실 이는 어셈블리어 수준에서만 적용되는 이야기이다.
- 어셈블리어에서 b 변수가 가르키는 값을 적재하려면
load r1 1: 메모리 주소 1에 있는 숫자 3을 r1 레지스터에 적재한다.- 하지만 메모리 주소 1에 있는 값은 메모리 주소로 해석되야 하므로 식별자를 추가한다.
load r1 @1: 메모리 주소 1에 저장된 값인 3을 읽어 이 값을 메모리 주소로 간주하여 해석한 후 메모리 주소 3이 가리키는 데이터 값을 진짜 데이터로 간주한다.- 이를 간접 주소 지정(indirect addressing)이라고 하며, 어셈블리어에는 변수라는 개념이 없기 때문에 어셈블리어를 사용한다면 반드시 이 간접 주소 지정 계층을 알고 있어야 한다.
- 고급 언어에서 포인터는 하나의 변수에 불과하다. 단지 이 변수가 저장하기에 적합한 것이 메모리 주소일 뿐이다. 포인터는 메모리 주소를 더 높은 수준으로 추상화한 것이다.
- 포인터를 더 높은 수준의 추상화라고 하며, 이 추상화 목적은 간접 주소 지정을 감싸기 위한 것이다.
- 어셈블리어 수준: 주소 1 –> 주소 3 –> 데이터
- 고급 언어 수준: b –> 데이터
포인터의 힘과 파괴력: 능력과 책임
- 자바와 파이썬 같은 언어에는 포인터가 존재하지 않는다. 이런 프로그래밍 언어에서는 메모리 주소를 직접 노출하지 않아 메모리 주소를 확인할 수 없기에 특정 메모리 위치에 있는 데이터를 조작하는 것이 불가능하다.
- 반면에 C 언어는 메모리 주소를 추상화하지 않으며 훨씬 더 유연하므로 메모리 주소를 프로그래머가 직접 알 수 있다.
- 포인터 개념이 있으면 프로그래머는 메모리 같은 하드웨어를 직접 조작할 수 있지만, 포인터 개념이 없는 프로그래밍 언어에서는 이런 작업이 불가능하다. 이것이 C 언어가 저수준 계층을 제어하는 강력한 힘을 가진 이유이자 C 언어가 시스템 프로그래밍에 가장 먼저 선택되는 중요 원인이기도 하다.
- 직접 메모리를 읽고 쓰는 기능이 모든 상황에 다 필요한 것은 아니며, 이는 자바와 파이썬 같은 언어로 증명됐다. 비록 이 언어에 포인터는 없지만, 포인터 대신 사용할 수 있도록 포인터를 한 번 더 추상화한 참조가 있기 때문이다.
포인터에서 참조(reference)로: 메모리 주소 감추기
- 포인터를 지원하는 대신 참조라는 개념을 제공하는 프로그래밍 언어에서 참조를 사용할 때는 변수의 구체적인 메모리 주소를 얻을 수 없으며, 참조는 포인터와 유사한 구조의 산술 연산을 할 수 없다.
- 참조를 사용하면 데이터를 복사할 필요가 없기 때문에 포인터를 사용할 때와 동일한 효과를 얻을 수 있다.
- 요약하면, 포인터는 메모리 주소를 추상화한 것이고 참조는 포인터를 한 번 더 추상화한 것이라 할 수 있다.
Section 3.2 프로세스는 메모리 안에서 어떤 모습을 하고 있을까?
- 64비트 시스템에서 메모리 내 프로세스 구조
- 커널
- 2^48 - 1
- 스택 영역(함수 실행 시 정보 저장)
- 스택 상단
- 유휴 영역
- 힙 영역(동적 메모리 할당)
- 데이터 영역
- 코드 영역
- 0x4000000
- 모든 프로세스 주소 공간에는 코드 영역, 데이터 영역, 힙 영역, 스택 영역이 있다.
- 코드 영역(code segment)과 데이터 영역(data segment)은 실행 파일을 초기화할 때 생성되는 영역이다.
- 힙 영역(heap segment)은 동적 메모리 할당에 사용되는데, 구체적으로 C/C++ 언어의 malloc 함수에서 요청한 메모리가 이 영역에 할당된다.
- 스택 영역(stack segment)은 함수 호출에 사용되는 매개변수, 반환 주소, 레지스터 정보 등을 포함한 함수 실행 시 정보를 저장하는데 사용
가상 메모리: 눈에 보이는 것이 항상 실제와 같지는 않다
- 가상 메모리에서 사용되는 주소는 가상 메모리 주소 또는 가상 주소에 해당한다.
- 위의 ‘메모리 내 프로세스 구조’는 사실 가상적인 구조에 불과하다. 실제 메모리에는 애초에 이런 형태의 구조가 존재할 수 없다.
- 프로세스는 동일한 크기의 ‘조각(chunk)’으로 나뉘어 물리 메모리에 저장된다.
- 모든 조각은 물리 메모리 전체에 무작위로 흩어져 있다.
페이지와 페이지 테이블: 가상에서 현실로
- 가상 메모리 주소 공간은 물리 메모리에 사상(mapping)되어 있다.
- 가상 메모리 주소와 물리 메모리 주소의 사상 관계가 유지되는 한 프로세스 주소 공간의 데이터가 실제 물리 메모리의 어디에 저장되는지 전혀 신경 쓸 필요가 없다.
- 이런 사상 관계를 유지하는 것을 페이지 테이블이라고 하며, 각각의 프로세스에는 단 하나의 페이지 테이블만 있어야 한다.
- 모든 가상 주소를 물리 주소에 사상하는 대신 프로세스의 주소 공간을 동일한 크기의 ‘조각’으로 나누고, 이 ‘조각’을 페이지(page)라고 부른다.
Section 3.3 스택 영역: 함수 호츨은 어떻게 구현될까?
함수 호출 활동 추적하기: 스택
- 함수 호출 활동을 추적하면 후입선출(last in first out) 순서로, 본질적으로 스택과 같은 데이터 구조가 처리하기에 적합하다.
- 사실상 이진 트리(binary tree)의 탐색(search)과 같다. 이런 트리 구조의 순회가 재귀 구현뿐만 아니라 스택 구현에도 사용될 수 있는 이유다.
스택 프레임 및 스택 영역: 거시적 관점
- 모든 함수는 실행 시에 자신만의 ‘작은 상자’가 필요하다. 이 상자 안에는 해당 함수가 실행될 때 사용되는 여러 가지 정보가 저장되어 있으며, 이 상자들은 스택 구조를 통해 구성된다.
- 여기서 각각의 작은 상자를 스택 프레임(stack frame) 또는 호출 스택(call stack)이라고 한다. 이 구조는 우리가 일반적으로 말하는 프로세스의 스택 영역에 생성된다.
- 이때 프로세스 스택 영역의 높은 주소(highest address)가 맨 위에 있고 낮은 주소 방향으로 커진다.
함수 점프와 반환은 어떻게 구현될까?
- 함수 A가 함수 B를 호출하면, 제어권이 함수 A에서 함수 B로 옮겨진다.
- CPU가 함수 A의 명령어를 실행하다가 함수 B의 명령어로 점프하는 것을 제어권이 함수 A에서 함수 B로 이전되었다고 한다.
- 제어권이 이전될 때는 다음 두 가지 정보가 필요하다.
- 반환(return): 어디에서 왔는지에 대한 정보
- 점프(jump): 어디로 가는지에 대한 정보
- 함수 A의 스택 프레임에 call 명령어 다음에 위치한 주소를 넣는다.
- 함수 A의 스택 프레임 영역이 차지하는 메모리 크기도 증가된다.
- 함수 B가 호출되면 함수 B의 스택 프레임이 생긴다.
매개변수 전달과 반환값은 어떻게 구현될까?
- x86-64에서는 대부분의 경우 매개변수의 전달과 반환값을 가져오는 작업을 레지스터로 한다.
- CPU 내부의 레지스터 수는 제한되어 있다. 만약 전달된 매개변수 수가 사용 가능한 레지스터 수보다 많다면 어떻게 될까?
- 원래 매개변수 수가 레지스터 수보다 많으면 나머지 매개변수는 스택 프레임에 직접 넣을 수 있기 때문에 새로 호출된 함수(함수 B)가 이전의 함수(함수 A)의 스택 프레임에서 매개변수를 가져오면 된다.
- 스택 프레임 내용이 더 많아졌다.
지역 변수는 어디에 있을까?
- 매개변수와 마찬가지로 레지스터에 저장할 수 있지만, 로컬 변수 수가 레지스터 수보다 많으면 이 변수들도 스택 프레임에 저장되어야 한다. 스택 프레임 내용이 더 늘었다.
레지스터 저장과 복원
- 레지스터에 지역 변수를 저장하기 전에 반드시 먼저 레지스터에 원래 저장되었던 초기값을 꺼냈다 레지스터를 사용하고 나면 다시 그 초기값을 저장해야한다.
- 이것 역시 함수의 스택 프레임에 저장된다.
- 함수 실행이 완료된 후에는 스택 프레임에 저장되어 있는 초기값을 상응하는 레지스터에 내용으로 복원하기만 하면 된다.
큰 그림을 그려 보자, 우리는 지금 어디에 있을까?
- 앞서 설명했던 스택 프레임은 우리가 흔히 스택 영역이라고 하는 곳에 위치한다.
- 스택 영역은 프로세스 주소 공간의 일부이며, 스택 영역을 확대하면 다음과 같다.
- 함수 A의 스택 프레임
- 레지스터 초기값
- 지역 변수
- 매개변수 1
- …
- 매개변수 n
- 반환 주소
- 함수 B의 스택 프레임
- …
- 함수 A의 스택 프레임
- 재귀 함수를 반복해서 호출 하면, 함수가 매번 호출될 때마다 상응하는 스택 프레임은 함수 실행 시 정보를 저장하기 위해 생성되며, 함수 호출 단계가 증가함에 따라 스택 영역이 점점 더 많은 메모리를 차지하게 된다.
- 하지만 스택 영역의 크기에는 제한이 있으며, 이 제한을 초과하면 바로 그 유명한 스택 넘침(stack overflow) 오류가 발생한다.
- 따라서 프로그래머는 다음 것들을 주의해야 한다.
- 너무 큰 지역 변수를 만들면 안 된다.
- 함수 호출 단계가 너무 많으면 안된다.
- 스택 영역의 아래는 유휴 영역(free segment)이다. 스택 영역이 계속 증가하면 유휴 영역을 점유하기 시작하는데, 이 영역에도 역할이 존재한다. 프로그램이 동적 라이브러리에 의존하는 경우에는 프로그램이 사용하는 동적 라이브러리가 이 영역에 적재된다.
Section 3.4 힙 영역: 메모리의 동적 할당은 어떻게 구현될까?
- 스택 프레임은 스택 영역 내에 구성되기 때문에 함수의 호출 단계가 증가할 때마다 스택 영역이 차지하는 메모리가 늘어난다. 반면에 함수 호출이 완료되면 기존 스택 프레임 정보는 더 이상 사용되지 않으므로 스택 영역이 차지하는 메모리는 그만큼 줄어든다.
- 프로그래머는 앞의 내용을 기반으로 두 가지 내용에 주의해야 한다.
-
함수 A가 함수 B를 호출할 때, 함수 B에 대한 호출 과정이 완료되면 스택 프레임에 저장되어 있던 내용은 더 이상 사용되지 않고 무효화(invalidation)된다.
int* B() { int a = 10; return &a; }- 함수 B가 스택 프레임에 저장되어 있던 지역 변수 데이터에 대한 포인터를 반환하는 것처럼 이미 사용이 끝난 스택 프레임 정보를 사용해서는 안 된다.
-
지역 변수 생명주기(lifecycle)는 함수 호출과 동일하다. 이것의 장점은 프로그래머가 지역 변수가 차지하는 메모리의 할당과 반환 문제에 신경 쓸 필요가 없으며 함수를 호출할 때 지역 변수가 바로 스택 프레임에 저장된다는 것이다. 반면에 지역 변수의 단점은 함수를 뛰어넘어 사용하는 것이 불가능하다는 것이다.
-
힙 영역이 필요한 이유
- 특정 데이터를 여러 함수에 걸쳐 사용해야 한다면 어떻게 해야 할까?
- 전역 변수는 모든 모듈에 노출되어 있으며, 때로는 데이터를 모든 모듈에 노출하고 싶지 않을 때도 있을 것이다.
- 이런 종류의 데이터는 프로그래머가 직접 관리하는 특정 메모리 영역에 저장해야 한다.
- 이와 같은 이유로 메모리 수명 주기에는 프로그래머가 완전히 직접 제어할 수 있는 매우 큰 메모리 영역이 필요하며, 이 영역을 바로 힙 영역(heap segment)이라고 한다.
- C/C++ 언어에서는 malloc 함수 또는 new 예약어를 사용하여 힙 영역에 메모리를 요청하며, free 함수나 delete 예약어를 이용하여 해당 메모리를 반환한다.
malloc 메모리 할당자 직접 구현하기
- 메모리 할당자 입장에서는 적절한 크기의 메모리 영역을 제공하기만 하면 되고, 할당자는 그 메모리 영역에 무엇을 저장할지까지는 신경 쓰지 않는다. 정수, 연결 리스트, 이진 트리 등 어떤 구조의 데이터도 모두 저장할 수 있으며, 메모리 할당자가 보기에 이런 데이터는 단순한 바이트의 연속에 지나지 않다.
- 힙 영역 위에서 두 가지 문제를 해결해야 한다.
- malloc 함수를 구현: 누군가 메모리 영역을 요청하면 힙 영역에서 가능한 메모리 영역을 찾아 요청자에게 반환하는 과정을 구현
- free 함수를 구현: 메모리 영역의 사용이 완료되었을 때 힙 영역에 이 메모리 영역을 반환하는 방법을 구현하는 것
주차장에서 메모리 관리까지
- 요청하는 메모리 크기가 일정하지 않다는 조건하에서 다음 두 가지 목표를 어떻게 달성할 수 있을까?
- 요청된 크기를 만족하는 여유 메모리를 최대한 빨리 찾기.
- 정해진 메모리 한도 내에서 가능한 한 많은 메모리 할당 요청을 만족해야 한다.
- 문제
- 메모리 조각을 어떤 식으로든 조직화해야만 모든 메모리 조각의 할당 상태를 추적할 수 있다.
- 이제 사용 가능한 메모리 조각이 많을 수 있다. 이때 어떤 여유 메모리 조각을 사용자에게 반환해야 할까?
- 요청한 크기보다 큰 메모리 조각을 할당 후, 남은 메모리는 어떻게 처리해야 할까?
- 반환한 메모리는 어떻게 처리해야할까?
여유 메모리 조각 관리하기
- 어떤 영역이 사용 가능한 메모리이고 어떤 영역이 이미 할당된 메모리인지 구분하는 방법이 필요하다.
- 연결 리스트와 메모리 사용 정보믈 메모리 조각 그 자체에 함께 저장한다. 다음 두 가지 정보만 기록하면 된다.
- 해당 메모리에 조각이 비어 있는지 알려 주는 설정값(flag)
- 해당 메모리 조각의 크기를 기록한 숫자
- 최대한 간단하게 구현하기 위해 메모리 정렬(memory alignment)이 필요하지 않으며, 단일 메모리 할당에 허용되는 최대 크기ㅓㄴㅈ는 2GB라고 정의한다.
- 메모리 조각의 최대 크기가 2GB로 제한되어 있기 때문에 31비트를 사용하여 조각 크기를 기록하고, 나머지 1비트는 조각이 비어 있는지 또는 할당되어 있는지 인식하는데 사용한다.
- 32비트 머리 정보(header)에는 free/allocated를 뜻하는 f/a가 할당된다.
- 머리 정보(header): 조각 크기 + f/a
- 페이로드(payload): 할당 가능한 메모리 조각, malloc을 호출하면 반환되는 메모리 주소가 바로 여기에서 시작된다.
- 머리 정보 주소만 알고 있다면 해당 머리 정보 주소에 메모리 조각 크기를 더해 다음 노드의 시작 주소를 알 수 있다.
메모리 할당 상태 추적하기
- 연결 리스트와 마찬가지로 메모리 할당자에도 끝(tail node)을 알려주는 특수한 표시(sentinel)가 필요하며, 이를 위해 마지막 4바이트를 사용한다.
- 머리 정보를 도입한 설계는 전체 힙 영역을 쉽게 추적할 수 있다. 또 추적 과정에서 머리 정보의 마지막 비트를 확인하여 메모리 조각이 여유 상태인지 또는 할당되었는지 확인할 수 있어 메모리 조각의 할당 정보를 추적할 수 있다.
어떻게 여유 메모리 조각을 선택할 것인가: 할당 전략
- 적절한 크기의 여유 메모리 조각을 찾기
- 최초 적합 방식(first fit): 매번 처음부터 탐색하다가 가장 먼저 발견된 요구 사항을 만족하는 항목을 반환하는 것이다.
- 장점: 단순하다는 것
- 단점: 메모리 할당 과정에서 앞부분에 작은 메모리 조각이 많이 남을 가능성이 높다.
- 다음 적합 방식(next fit): 메모리를 요청할 때 처음부터 검색하는 대신 적합한 여유 메모리 조각이 마지막으로 발견된 위치에서 시작한다.
- 장점: 이론적으로 최초 적합 방식보다 더 빠르게 여유 메모리 조각을 탐색할 수 있다.
- 단점: 메모리 사용률은 최초 적합 방식에 미치지 못한다.
- 최적 적합 방식(best fit): 사용 가능한 메모리 조각을 모두 찾은 후 그중 요구 사항을 만족하면서 크기가 가장 작은 조각을 반환한다.
- 장점: 최초 적합 방식과 다음 적합 방식보다 메모리를 더 잘 활용한다.
- 단점: 최초 적합 방식이나 다음 적합 방식만큼 빠르지 않다.
메모리 할당하기
- 적절한 여유 메모리 조각을 찾으면 이를 할당해야 한다.
- 이 조각을 할당된 것으로 표시하고 머리 정보 뒤에 따라오는 메모리 조각의 주소를 요청자에게 반환한다. 이때 머리 정보를 담고 있는 메모리는 요청자에게 반환되면 안 된다. 일단 이 정보가 손상되면 메모리 할당자가 정상적으로 작동할 수 없다.
- 요청한 메모리보다 찾아낸 여유 메모리 조각이 클 때, 여유 메모리 조각을 전부 할당하면 메모리가 낭비되고 내부 단편화(fragmentation)가 발생하게 되어 해당 메모리 조각의 남은 부분을 사용할 방법이 없다.
- 이 문제를 해결하는 방법은 여유 메모리 조각을 두 개로 분할하여 앞부분은 할당한 후 반환하고, 뒷부분은 좀 더 작은 크기의 새로운 여유 메모리 조각으로 만드는 것이다.
메모리 해제하기
- 사용자가 메모리를 요청할 때 얻은 주소를 free 같은 해제 함수에 전달하기만 하면 된다.
- 매개변수로 전달된 주소에서 머리 크기인 4바이트를 빼는 것으로 해당 메모리 조각의 머리 정보를 얻을 수 있다.
- 머리 정보에서 할당 설정값을 여유 메모리로 바꾸면 해제가 완료된다.
- 메모리 해제를 위해 free 함수를 호출할 때 해제할 메모리 조각 크기를 전달할 필요 없이 주소만 전달하는 이유다.
- 메모리를 해제할 때 중요한 것이 하나 있다. 해제되는 메모리 조각과 인전한 메모리 조각이 여유 메모리 조각일 때, 병합하는 것이다.
- 메모리가 해제될 때 즉시 병합하는 것은 비교적 간단하다. 하지만 메모리가 해제될 때마다 메모리 조각 병합을 한다면 그에 따른 부담이 발생한다.
- 메모리 할당자가 불필요한 작업을 많이 수행하지만, 가장 간단해서 여전히 이 전략을 많이 선택하여 사용한다.
- 하지만 실제 메모리 할당자는 거의 대부부 여유 메모리 조각 병합을 연기하는 일종의 전략을 세우고 있다.
여유 메모리 조각을 효율적으로 병합하기
- 앞에 위치한 메모리 조각이 비어 있는 지 여부를 효율적으로 알 수 있는 방법
- 메모리 조각 끝에 꼬리 정보(footer)를 추가한다.
- 머리 정보(header): 조각 크기 + free/allocated
- 페이로드(payload): 할당 가능한 메모리 조각
- 꼬리 정보(footer): 조각 크기 + free/allocated
- 머리 정보와 꼬리 정보는 메모리 조각을 일종의 암시적 양방향 연결 리스트(doubly linked list)로 만든다.
- 메모리 조각 끝에 꼬리 정보(footer)를 추가한다.
Section 3.5 메모리를 할당할 때 저수준 계층에서 일어나는 일
천지인과 CPU 실행 상태
- x86 CPU는 ‘네 가지 특권 단계(privilege level)’를 제공한다.
- 보호 링(protection ring)
- Ring 0: 커널
- Ring 1: 시동 준비 프로그램
- Ring 2: 시동 준비 프로그램
- Ring 3: 응용 프로그램
- 숫자가 작을수록 CPU의 특권이 커진다.
- 특권은 일부 명령어를 싱핼할 수 있는지 나타내며, 일부 기계 명령어는 CPU가 가장 높은 특권 상태일 때만 실행 가능하다.
- 일반적으로 시스템은 CPU의 특권 단계 중 0과 3 두 단계만 사용한다. 이 중 특권 3단계는 ‘사용자 상태(user mode)’라고 하며, 특권 0단계는 ‘커널 상태(kernel mode)’라고 한다.
- 보호 링(protection ring)
커널 상태와 사용자 상태
- CPU가 운영 체제의 코드를 실행할 때 바로 커널 상태에 놓인다. 커널 상태에선느 CPU가 모든 기계 명령얼르 실행할 수 있고, 모든 주소 공간에 접근할 수 있으며, 제한 없이 하드웨어에 접근할 수 있다.
- 반면에 프로그래머가 작성한 ‘일반적인’ 코드를 CPU가 실행할 때는 사용자 상태에 해당한다.
- 사용자 상태 코드는 여러 곳에서 제한을 받는데, 특히 특정 주소 공간에는 절대 접근할 수 없다. 이런 제한이 없다면 운영 체제를 ‘죽이는(kill)’ 모순에 빠지며, 이것이 세그먼테이션 오류(segmentation fault)이다.
- CPU는 사용자 상태일 때는 특권 명령어를 실행할 수 없다는 제한도 있다.
포털: 시스템 호출
- CPU는 커널 상태에서는 응용 프로그램을 실행할 수 없는 반면, 사용자 상태에서는 운영 체제의 코드를 실행할 수 없다.
- 그렇다면 응용 프로그램이 파일 읽기나 쓰기, 네트워크 데이터의 송수진 등 운영 체제의 서비스를 요청해야 한다면 어떻게 해야 할까?
- 프로그래머는 시스템 호출(system call)을 통해 운영 체제에 서비스를 요청할 수 있다.
- 시스템 호출은 x86의 INT 명령어처럼 특정한 기계 명령어로 구현된다. 이 명령어를 실행할 때 CPU는 사용자 상태에서 커널 상태로 전환되어 운영 체제의 코드를 실행하는 방법으로 사용자 요청을 수행한다.
- 이런 관정에서 보면, 프로세스는 네트워크 통신에서 클라이언트(client)에 비할 수 있고, 운영 체제는 서버(server)에 비할 수 있다.
- 프로세스: 시스템 호출 요청 –> 운영체제: 시스템 호출 실행 –> 프로세스: 운영 체제가 반환 호출
표준 라이브러리: 시스템의 차이를 감춘다
- 시스템 호출은 모두 운영 체제와 매우 밀접한 관련이 있으며, 리눅스의 시스템 호출은 윈도의 시스템 호출과 완전히 다르다.
- 시스템 호출을 직접 사용하면 리눅스의 프로그램은 윈도에서 직접 실행할 수 없게 된다. 시스템 호출 방식이 다르기에 같은 소스 코드를 그대로 가져다 컴파일해서 실행할 수 없다는 의미이다.
- 따라서 사용자에게서 저수준 계층 간 차이를 감추는 표준이 필요하다.
- C 언어에서 이 일을 하는 것이 바로 표준 라이브러리(standard library)이다.
- 표준 라이브러리의 코드는 사용자 상태에서도 실행된다. 일반적으로 프로그래머는 표준 라이브러리를 호출하여 파일의 읽고 쓰기 작업과 네트워크 통신을 수행하며, 표준 라이브러는 실행 중인 운영체제에 따라 대응되는 시스템 호출을 선택한다.
- 계층적 관점에서 보면, 다음과 같이 햄버거 형태를 이루고 있다.
- 응용 프로그램
- 표준 라이브러리
- 운영 체제
- 하드웨어
- 고수준 계층에는 응용 프로그램이 자리하고 있는데, 응용 프로그램은 일반적으로 표준 라이브러리만 의사소통 대상으로 간주한다. 표준 라이브러리는 시스템 호출로 운영 체제와 소통하며, 운영 체제는 저수준 하드웨어를 관리한다.
- 이것이 C 언어에서 동일한 open 함수를 사용하여 리눅스뿐만 아니라 윈도우 파일을 열 수 있는 이유이다.
- malloc 같은 메모리 할당자는 사실 운영 체제의 일부분이 아니라 표준 라이브러리의 일부로 구현되어 있다.
- C 언어에서 기본적으로 사용되는 malloc은 여러 종류의 메모리 할당자 중 하나에 불과하며, 이외에도 tcmalloc, jemalloc 등 다양한 유형의 메모리 할당자가 있다. 가장 적합한 메모리 할당자를 선택하는 것이 매우 중요하다.
힙 영역의 메모리가 부족할 때
- 힙 영역과 스택 영역 사이에는 여유 공간이 있다. 스택 영역이 함수 호출 단계가 깊어질수록 아래쪽(메모리의 점유 공간 방향은 높은 주소가 위쪽, 낮은 주소가 아래쪽)으로 메모리 점유 공간이 늘어나는 것처럼, 힙 영역의 메모리가 부족하면 위쪽으로 더 많은 메모리를 점유하게 된다.
- 원래 malloc은 메모리가 부족해지면 운영 체제에 메모리를 요청해야 한다. 리눅스의 모든 프로세스에는 brk 변수가 있다. brk 변수는 브래이크(break)를 의미하며 힙 영역의 최상단을 가르킨다.
- brk 변수 값을 위로 이동해서 힙 영역을 확장하려면 시스템 호출이 필요하다.
운영 체제에 메모리 요청하기: brk
- 리눅스에서는 brk라는 전용 시스템 호출을 제공한다.
- 이런 시스템 호출이 있으므로 힙 영역이 부족하면 즉시 운영 체제에 힙 영역을 늘릴 것을 요청할 수 있고, 더 많은 여유 메모리를 확보할 수 있다는 것이다.
- 메모리 할당이 더 이상 사용자 상태의 힙 영역에만 국한된지 않기에 메모리 할당 단계가 다음과 같이 달라진다.
- 프로그램은 malloc(표준 라이브러리에 구현)을 호출하여 메모리 할당 요청
- malloc은 여유 메모리 조각을 검색하기 시작하고, 적절한 크기의 조각을 찾으면 이를 할당한다. 이 단계까지는 사용자 상태에서 처리된다.
- malloc이 여유 메모리 조각을 찾지 못하면 brk 시스템 호출 등을 통해 운영 체제에 힙 영역을 늘려주라고 요청한다. brk는 운영 체제의 일부분이므로 커널 상태에 놓여 있다. 힙 영역이 늘어나면 malloc이 다시 한 번 적절한 여유 메모리 조각을 찾아서 할당한다.
- 메모리 할당 한 번에도 운영 체제의 도움이 필요할 수 있다.
- 프로세스: malloc 호출
- 표준 라이브러리: malloc이 brk를 호출하여 운영 체제에 메모리 요청
- 운영 체제: brk 시스템 호출 실행
- 표준 라이브러리: brk 반환 후 malloc은 여유 메모리 조각을 찾음
- 프로세스: malloc 반환
빙산의 아래: 가상 메모리가 최종 보스다
- 지금까지 malloc에 메모리를 요청하고, malloc은 메모리가 부족할 때 운영 체제에 힙 영역의 확장을 요청하며, 이후 malloc이 다시 여유 메모리 조각을 찾아 사용자에게 반환한다고 배웠다.
- 그러나 가상 메모리를 지원하는 시스템에서는 이런 과정이 전혀 일어나지 않으며, 실제 물리 메모리라는 것이 존재하지 않는다.
- malloc의 호출이 반환되면 프로그래머가 받아 오는 메모리는 가상 메모리이다.
- 실제 물리 메모리는 사용되는 순간에 물리 메모리를 할당한다. 이때 가상 메모리가 아직 실제 물리 메모리와 연결되어 있지 않으면 내부적으로 페이지 누락 오류(page fault)가 발생할 수 있다.
- malloc은 메모리의 2차 할당에 불과하며, 할당받는 것도 그나마 가상 메모리에 불과하다. 그리고 이 과정은 모두 사용자 상태에서 처리된다.
- 프로그램이 할당된 가상 메모리를 사용할 때 이 메모리는 반드시 실제 물리 메모리와 사상 관계에 있어야 하며, 이 시점이 되어야 커널 상태에서 실제 물리 메모리가 할당된다.
메모리 할당의 전체 이야기
- malloc을 호출하여 메모리를 요청하면 다음 일이 일어난다.
- malloc이 여유 메모리 조각을 검색하기 시작하고 적절한 크기의 조각을 찾으면 이를 할당한다.
- malloc이 적절한 메모리를 찾지 못하면 brk 같은 시스템 호출을 통해 힙 영역을 확장하여 더 많은 여유 메모리를 얻는다.
- malloc이 brk를 호출하면 커널 상태로 전환되는데, 이때 운영 체제의 가상 메모리 시스템 힙 영역을 확장하는 작업을 시작한다. 주의할 점은 이렇게 확장된 메모리 영역은 가상 메모리에 불과하며, 운영 체제는 아직 실제 물리 메모리를 할당하지 않을 수 있다.
- brk 실행이 종료되면 malloc으로 제어권이 돌아가며 CPU도 커널 상태에서 사용자 상태로 전환된다. malloc은 이제 적절한 여유 메모리 조각을 찾아 반환한다.
- malloc을 통해 빈번하게 메모리를 할당하고 해제하는 것은 시스템 성능에 일정 수준 영향을 미친다.
Section 3.6 고성능 서버의 메모리 풀은 어떻게 구현될까?
- 프로그래머가 메모리 요청할 때 사용하는 malloc은 범용 제품으로서 어떤 상황에서도 사용할 수 있다. 다시 말해 특정 상황에 맞게 최적화되어 있지 않다는 의미다.
- 범용적인 malloc을 사용하는 대신 특정 상황을 위해 자체적으로 메모리 할당 전략을 구현할 수 있으며, 이것이 바로 메모리 풀 기술이다.
메모리 풀 대 범용 메모리 할당자
- malloc이라고 부르는 것은 사실 표준 라이브러리의 일부로, 표준 라이브러리 계층에 속하지만 메모리 풀은 응용 프로그램의 일부다.
- 메모리 풀 기술은 특정 상황에서만 적용 가능하고, 특정 상황에서만 메모리 할당 성능을 최적화하기에 범용성이 매우 떨어진다.
메모리 풀 기술의 원리
- 메모리 풀 기술은 한 번에 큰 메모리 조각을 요청하고 그 위에서 자체적으로 메모리 할당과 해제를 관리하는 방식으로 표준 라이브러리와 운영 체제를 우회한다.
- 특정 사용 패텬에 따라 추가 최적화도 가능하다. 예를 들어 서버에서 사용자 요청을 처리할 때마다 여러 종류의 객체를 생성해야 한다면 자체 메모리 풀에 미리 이런 객체를 생성해 두는 것이 가능하다.
초간단 메모리 풀 구현하기
- 서버 프로그래밍을 예로 든다.
- 사용자 요청을 처리할 때 단 한 종류의 객체, 즉 데이터 구조만 사용한다고 가정해보자.
- 미리 커다란 메모리 영역을 할당하는데, 그 수량은 실제 상황에 따라 직접 결정할 수 있다. 실제 사용할 때마다 하나씩 꺼내며 사용이 끝나면 반환한다.
- 이런 간단한 메모리 풀조차 실제 문제를 해결할 수 있다. 물론 특정 객체나 데이터 구조만 할당할 수 있다는 한계는 존재한다.
약간 더 복잡한 메모리 풀 구현하기
- 크기가 서로 다른 메모리 요청을 지원하는 서버 프로그래밍 상황을 가정한다.
- 여러 크기의 메모리를 할당하려면, 여유 메모리 조각을 관리해야 한다.
- 따라서 모든 메모리 조각을 연결 리스트로 연결하고 포인터를 사용하여 현재 여유 메모리 조각의 위치를 기록할 수 있다.
- 메모리가 부족하면 malloc에 새로운 메모리 조각을 요청해야 하는데, 이때 새로운 메모리 조각의 크기는 항상 이전 메모리 조각의 두 배여야 한다. 이 전략은 C++ 언어의 vector 컨테이너 확장 전략과 유사하며, 이는 malloc에 메모리를 너무 빈번하게 요청하지 않기 위함이다.
- 10바이트 메모리를 요청할 때 메모리 풀의 여유 메모리 조각의 크기가 충분하다면, 이 포인터가 가리키는 주소를 직접 반환하고 포인트를 10바이트 뒤로 이동시키면 된다.
- free처럼 메모리 조각을 해제하는 기능은 제공하지 않으며, 요청 처리가 완료되면 한 번에 전체 메모리 풀을 해제한다.
- 이렇게 메모리 해제로 부담을 최대한 줄이는 것이 바로 범용 메모리 할당자와 다른 점이다.
메모리 풀의 스레드 안전 문제
- 메모리 풀에 직접 잠금 보호를 적용하면 스레드 풀이 올바르게 작동하는 것을 보장한다. 하지만 대량의 스레드가 메모리 할당과 해제를 요청하면 이 방식은 잠금 경쟁이 격렬해질 수 있다. 시스템 성능이 저하될 수 있기 때문에 더 나은 방법이 필요하다.
- 각 스레드마다 스레드 전용 저장소(thread local storage)를 사용한다. 메모리 풀을 스레드 전용 저장소에 넣을 수 있으며, 이렇게 하면 각 스레드가 자신에게 속한 스레드 풀만 사용할 수 있다.
Section 3.7 대표적인 메모리 관련 버그
- 지역 변수의 포인터 반환하기
- 포인터 연산의 잘못된 이해
- 문제 있는 포인터 역참조하기
- 초기화되지 않은 메모리 읽기
- 이미 해제된 메모리 참조하기
- 배열 첨자는 0부터 시작한다
- 스택 넘침
- 메모리 누수
Section 3.8 왜 SSD는 메모리로 사용할 수 없을까?
- SSD(Solid State Drive)의 순차 읽기 속도(sequential reading speed)가 최대 7.5GB/s이다. 기본적으로 몇 초 내에 4K 영화 한 편을 읽을 수 있다.
- 5세대 DDR 메모리의 최대 대역폭은 60GB/s를 훌쩍 넘는다.
- 즉, SSD를 실제로 메모리로 사용한다면 컴퓨터 속도가 현재보다 약 10분의 1 수준으로 느리게 실행될 것이다.
메모리 읽기/쓰기와 디스크 읽기/쓰기의 차이
- 새 파일을 생성해 기록 후 탐색기에서 파일의 정보를 확인해보면, 파일 크기(size)는 816바이트에 불과하지만 공간(size on disk)은 4KB를 차지한다.
- 메모리의 주소 지정 단위는 바이트이다. 즉 각 바이트마다 메모리 주소가 부여되어 있고, CPU가 이 주소를 이용하여 해당 내용에 직접 접근할 수 있다는 것을 의미한다.
- 하지만 SSD는 조각 단위로 데이터를 관리하며, 이 조각 크기는 매우 다양하다.
- 여기에서 중요한 점은 CPU가 파일의 특정 바이트에 직접 접근할 수 있는 방법이 없다는 것이다. 다시 말해 바이트 단위 주소 지정이 지원되지 않는다는 의미이다.
- 메모리는 바이트 단위로, 디스크는 조각 단위로 주소가 지정된다.
가상 메모리의 제한
- 32비트 시스템의 최대 주소 지정 범위는 4GB에 불과하므로 1TB 크기를 가진 SSD를 메모리로 사용하더라도 여전히 프로세스는 4GB 이상의 메모리를 사용할 수 없다.
- 물론 주소 지정 범위가 충분히 큰 64비트 시스템에서는 이런 문제가 없다.
SSD 사용 수명 문제
- SSD 제조 원리에 따라 사용 수명 제한이 있다. 기록 가능한 바이트를 표시하는 TBW(TeraBytes Written)이다. 일반적으로 흔히 사용되는 SSD의 TBW는 대략 수백 TB 수준이다.
- CPU는 프로그램을 실행할 때 대량의 메모리 읽기와 쓰기 작업을 실행하므로 SSD를 메모리로 사용하면 사용 수명 때문에 시스템에 병목 현상이 발생할 수 있지만, 메모리에는 이런 문제가 없다.
Chapter 4. 트랜지스터에서 CPU로, 이보다 더 중요한 것은 없다
CPU라는 컴퓨터 엔진은 추상화 계층으로 둘러싸여 프로그래머와 점점 더 멀어지고 있다. 현대 프로그래머, 특히 응용 계층의 프로그래머는 프로그래밍을 하면서 CPU를 거의 인식하지 못할 뿐만 아니라 신경 쓸 필요도 없다. 바로 이것이 추상화의 위력이다. 현대 컴파일러 같은 도구 덕분에 프로그래머는 인간에 가까운 언어를 이용하여 초당 수십억 번에서 수백억 번 연산이 가능한 트랜지스터로 구성된 신기한 장치를 다를 수 있게 되었다.
Section 4.1 이 작은 장남감을 CPU라고 부른다
- 트랜지스터(transistor): 단자 한쪽에 전류를 흘리면 나머지 단자 두 개에 전류가 흐르게 할 수도 있고 흐르지 못하게 할 수도 있는데, 그 본질은 스위치와 동일하다.
- 프로그래머가 작성한 프로그램이 아무리 복잡해도 소프트웨어가 수행하는 기능은 최종적으로 트랜지스터의 개폐 작업으로 완성된다.
논리곱, 논리합, 논리부정
- 다음 세 가지 회로를 만들 수 있다.
- 논리곱 게이트(logical conjunction gate, AND gate): 스위치 두 개가 동시에 켜질 때만 전류가 흐른다.
- 논리합 게이트(logical disjunction gate, OR gate): 두 스위치 중 하나라도 켜져 있으면 전류가 흐른다.
- 논리부정 게이트(logical negation gate, NOT gate, inverter): 스위치를 닫으면 전류가 흐르고, 열면 전류가 흐르지 않는다.
도는 하나를 낳고, 하나는 둘을 낳고, 둘은 셋을 낳으며, 셋은 만물을 낳는다
- 논리곱 게이트, 논리합 게이트, 논리부정 게이트로 모든 논리 함수를 표현할 수 있다. 그리고 이것을 논리적 완전성(logical completeness)이라고 한다.
연산 능력은 어디서 나올까?
- CPU는 0과 1의 2진법만 알고 있다.
- 2진법으로 덧셈을 하면 다음과 같다.
- 0 + 0의 결과(result)는 0이며, 자리 올림수(carry)도 0이다.
- 0 + 1의 결과는 1이며, 자리 올림수는 0이다.
- 1 + 0의 결과는 1이며, 자리 올림수는 0이다.
- 1 + 1의 결과는 0이며, 자리 올림수는 1이다.
- 자리 올림수를 보면 두 입력 값이 모두 1일 때만 1이다. 논리곱 게이트이다.
- 결과를 보면 두 입력 값이 서로 다르면 결과가 1이고, 같으면 결과가 0이다. 이것을 배타적 논리합(exclusive OR, XOR)
- 논리곱 게이트 한 개와 배타적 논리합 게이트 한 개를 조합하면 2진법 덧셈을 구현할 수 있다. 이것이바로 간단한 가산기(adder)이다.
- 논리곱 게이트, 논리합 게이트, 논리부정 게이트를 조합한 회로를 이용하여 덧셈 작업을 구현할 수 있다. 그리고 CPU의 연산 능력은 여기에서 비롯된 것이다.
- CPU는 전문적으로 계산을 담당하는 모듈이 있는데, 바로 ALC라는 산술 논리 장치(Arithmetic Logic Unit)이다.
- 연산 능력만으로 부족하다. 회로는 정보를 기억할 수 있어야 하기 때문이다.
신기한 기억 능력
- 입력과 출력은 이를 저장할 곳이 있어야 하므로 정보를 저장할 수 있는 회로가 필요하다
- 부정 논리곱 게이트(non-conjunction gate, NAND gate) 두 개를 조합한 것이다. 먼저 논리곱 연산을 처리한 후 논리부정 연산을 처리한다.
- 정보를 기억하는 회로로 1비트를 저장할 수 있다.
레지스터와 메모리의 탄생
- 이 조합 회로를 레지스터(register)라고 부른다.
- 더 많은 정보를 저장하고 주소 지정(addressing) 기능을 제공하기 위해 더 복잡한 회로를 계속 구축해야 한다.
- 8비트를 1바이트로 규정하고 각각의 바이트가 자신의 번호를 받는다. 이제 부여된 번호를 이용하여 회로에 저장된 정보를 읽을 수 있다. 이렇게 메모리(memory)도 탄생했다.
- 전원이 연결되어 있는 한 이 회로는 정보를 저장할 수 있지만, 전원이 끊기면 저장된 정보는 모두 사라진다.
하드웨어 아니면 소프트웨어? 범용 장치
- 모든 연산 논리를 반드시 회로 같은 하드웨어로 구현할 필요는 없다. 하드웨어는 가장 기본적인 기능만 제공하고 모든 연산 논리는 이런 가장 기본적인 기능을 이용하여 소프트웨어로 표현하는 것이 좋은 방법이다. 이것이 소프트웨어라는 단어의 기원이다.
- 하드웨어는 변하지 않지만 소프트웨어는 변할 수 있기에 변하지 않는 하드웨어에 서로 다른 소프트웨어를 제공하면 하드웨어가 완전히 새로운 기능을 구현할 수 있다.
하드웨어의 기본 기술: 기계 명령
- 기계 명령어는 조합 회로를 이용하여 실행된다.
- CPU 표현 방식은 명령어 집합을 이용하여 구현된다.
소프트웨어와 하드웨어 간 인터페이스: 명령어 집합
- 명령어 집합(instruction set)은 CPU가 실행할 수 있는 명령어(opcode)와 각 명령어에 필요한 피연사자(operand)를 묶은 것이다.
- 서로 다른 유형의 CPU는 서로 다른 명령어 집합을 가지고 있다.
- 명령어 집합에서 명령어 한 개가 수행할 수 있는 작업은 사실 매우 간단하다.
- 메모리에서 숫자를 읽는다. 읽을 주소는 ***이다.
- 두 숫자를 더한다.
- 두 숫자의 크기를 비교한다.
- 숫자를 메모리에 저장한다. 저장할 주소는 ***이다.
- …
- 보기에는 자질구레한 이야기를 반복하는 것 같아 보이지만, 이것이 기계 명령어이다.
- 기계 명령어 하나가 할 수 있는 일은 사실 매우 간단하며 기계 명령어로 직접 프로그래밍하는 것은 매우 번거로울 수밖에 없어 고급 프로그래밍 언어가 탄생한 것이다.
회로에는 지휘자가 필요하다
- 회로는 많은 부분으로 구성되어 있는데, 일부는 데이터를 계산하는데 사용되고 일부는 정보를 저장하는데 사용된다.
- 클럭 신호(clock signal): 각 부분의 회로가 함께 작업할 수 있도록 조정하거나 동기화하는 역할
- 클럭 신호가 전압을 변경할 때마다 전체 회로의 각 레지스터, 즉 전체 회로 상태가 갱신된다.
- CPU 클럭 주파수(clock rate): 클럭 주파수가 높을수록 CPU가 1초에 더 많은 작업을 할 수 있다.
큰일을 해냈다, CPU가 탄생했다!
- 각종 계산이 가능한 산술 논리 장치, 정보를 저장할 수 있는 레지스터, 작업을 함께하도록 제어해 주는 클럭 신호를 갖추었다. 이를 한데 묶은 것을 중앙 처리 장치(central processing unit), 즉 CPU 또는 프로세서(processor)라고 한다.
Section 4.2 CPU는 유휴 상태일 때 무엇을 할까?
컴퓨터의 CPU 사용률은 얼마인가?
- 대부분 CPU의 사용률은 7~8% 정도로 매우 낮으며 대부분의 컴퓨터의 CPU 사용률은 높지 않다.
- 많은 프로세스는 기본적으로 아무런 작업도 하지 않고 있으며, 특정 이벤트가 발생하여 자신을 깨우기를 기다리고 있다.
프로세스 관리와 스케줄링
- ‘System Idle Process’ 항목이 90%가 넘는 CPU 사용률을 보이며, 때로는 99% 사용률을 보인다. 이는 이 프로세스가 거의 모든 CPU 시간을 소모하고 있음을 의미한다.
- 프로그램이 메모리에서 실행되면 프로세스 형태로 존재하고, 프로세스가 생성되면 운영 체제가 관리하고 스케줄링한다.
- 프로세스는 운영 체제의 대기열로 관리된다.
- 프로세스에 우선 순위를 할당하고, 우선순위에 따라 스케줄러(scheduler)가 스케줄링을 할 수 있도록 ‘준비 완료 대기열/블로킹 대기열’에 상응하는 대기열에 프로세스를 넣는다.
- 프로세스 스케줄링은 운영 체제가 구현해야 하는 핵심 기능 중 하나이다.
대기열 상태 확인: 더 나은 설계
- 준비 완료 대기열이 비어 있다면 이는 현재 운영 체제가 스케줄링해야 하는 프로세스가 없고, CPU가 유휴 상태에 있다는 것을 의미한다.
- 예외 처리가 없는 설계를 하기 위해 대기열을 가득 채워 스케줄러가 대기열에서 항상 실행할 수 있는 프로세스를 찾을 수 있도록 하면 된다.
- 연결 리스트에서 일반적으로 ‘감시자(sentinel)’ 노드를 사용하는 이유이다. 이 방법을 이용하여 별도의 NULL 판단 로직을 제거해서 코드 오류 가능성을 줄이고 구조를 깔끔하게 유지할 수 있다.
- 이와 같이 커널 설계자는 유휴 작업이라는 프로세스를 만들었는데, 이것이 바로 앞서 살펴본 윈도의 ‘System Idle Process’이다.
- 시스템에 스케줄링 가능한 프로세스가 없을 때 스케줄러는 이 유휴 프로세스를 꺼내서 실행한다. 이때 유휴 프로세스는 항상 준비 완료 상태에 있으며 우선순위가 가장 낮다.
모든 것은 CPU로 돌아온다
- 컴퓨터 시스템의 모든 것은 최종적으로 CPU로 구동되며, 끊임없이 일하는 ‘존재’이다.
- CPU 설계자는 일찍이 시스템에 유휴 상태가 존재할 가능성을 고려했기 때문에 정지를 의미하는 halt 명령어를 설계했다.
- 이 명령어는 CPU 내부의 일부 모듈을 절전 상태로 전환하여 전력 소비를 크게 줄인다. 일반적으로 이 명령어도 실행을 위해 순환에 배치한다. 가급적 절전 상태를 유지하는 것이 목적이다.
- halt 명령어는 특권 명령어라 커널 상태에서 CPU로만 실행될 수 있다.
- CPU가 halt 명령어를 실행한다는 것은 시스템 내 더 이상 준비가 완료된 프로세스가 없다는 것이다.
유휴 프로세스와 CPU의 저전력 상태
- 스케줄링 가능한 프로세스가 더 이상 존재하지 않으면 스케줄러가 유휴 프로세스를 실행하는데, 이것으로 순환 구조에서 계속 halt 명령어가 실행된다. 이 명령어로 CPU는 저전력 상태로 진입하기 시작한다.
무한 순환 탈출: 인터럽트
- 컴퓨터 운영 체제는 일정 시간마다 타이머 인터럽트(timer interrupt)를 생성하고, CPU는 인터럽트 신호를 감지하고, 운영 체제 내부의 인터럽트 처리 프로그램을 실행한다.
- 상응하는 인터럽트 처리 함수에서 프로세스가 실행될 준비가 되었는지 판단하고, 준비가 되었다면 중단되었던 프로세스를 계속 실행한다. 준비되어 있지 않다면 프로세스를 일시 중지시키고, 스케줄러는 준비 완료 상태인 다른 프로세스를 스케줄링한다.
- 예를 들어 유휴 프로세스가 타이머 인터럽트로 일시 중지되면 인터럽트 처리 함수는 시스템에 준비 완료된 프로세스가 있는지 확인하고, 없다면 유휴 프로세스를 계속 실행한다.
Section 4.3 CPU는 숫자를 어떻게 인식할까?
숫자 0과 양의 정수
- 아라비아 숫자 체계에서는 값과 숫자의 위치가 직접적인 관계가 있는데, 이를 위치 기수법(positional notation)이라고 한다. 하지만 로마 숫자 체계에서는 위치 기수법이 사용되지 않으므로 로마 숫자를 이용하여 큰 수를 표시하는 것은 매우 어렵다.
- 비트 k를 사용하면 정수 2^k개를 나타낼 수 있다.
- 그 범위는 0~2^k-1이므로, k가 여덟 개인 8비트라고 가정하면 표현 가능 범위는 0~255이다.
- 이는 부호 없는 정수(unsigned integer)에 해당한다.
부호 있는 정수(signed integer)
- 양의 정수를 반으로 나눠 절반은 양수를 나타내는 데 사용하고, 나머지 절반은 음수를 나타내는 데 사용하는 방법이다.
- 비트가 네 개 있을 때, 이를 이용해서 표현할 수 있는 부호가 없는 정수는 0~15가 된다. 반면에 부호 있는 정수를 표현하려면 절반은 1~7에 나누어 주고, 나머지 절반은 -1~7에 나누어 주어야 한다. 이 표시 방법에서는 최상위 비트(most significant bit)가 정수 부호를 결정하며 이 값이 0이면 양수, 그렇지 않으면 음수라고 정의한다.
양수에 음수 기호를 붙이면 바로 대응하는 음수: 부호-크기 표현
- 이 설계 방식은 매우 간단하다. 0010이 +2를 의미하므로 최상위 비트를 1로 바꾸기만 한 1010은 -2가 된다. 이 설계 방식은 간단하고 직접적이며 인간의 사고방식에 가장 가깝다. 이 표현 방식을 부호-크기 표현(sign-magnitude)이라고 한다.
- 부호-크기 표현은 -0이라는 숫자가 나타난다. 0000이 0을, 1000은 -0을 표시한다.
부호-크기 표현의 반전: 1의 보수
- 0010이 +2를 의미하니까, 이를 완전히 반전(비트 부정 연산, bitwise NOT)시킨 1101을 -2로 표시하는 방법을 일컬어 1의 보수(one’s complement)라고 한다.
- 1의 보수 표현 방식에도 -0은 여전히 있다. 0000은 0이며, 어깃의 1의 보수인 1111은 -0이다.
- 1의 보수 표현 방식은 부호-크기 표현 방식과 크게 다르지 않다.
- 이런 표시 방식에는 모두 공통된 문제가 있었으니, 바로 두 숫자를 더하는 것이다.
간단하지 않은 두 수 더하기
- 컴퓨터의 덧셈은 가산기 조합 회로로 구현된다. 하지만 부호-크기 표현이나 1의 보수를 이용하여 덧셈을 계산하려면 두 가지 방식 모두 가산기 위에 부호 있는 숫자의 정확한 덧셈을 보장하는 조합 회로를 추가하는 것이 불가피하다. 이는 회로 설계의 복잡도를 증가시킨다.
컴퓨터 친화적 표현 방식: 2의 보수
- 이 표현 방식에는 -0이 없다.
- 이 표현 방법은 가산기가 계산을 수행할 때 숫자 부호에 전혀 신경 쓸 필요가 없다.
- 이런 숫자 표현 방식이 현대 컴퓨터 시스템에서 사용되는 2의 보수(two’s complement)이다.
- 2의 보수를 사용하면 4비트일 경우 -8~7 범위의 숫자를 표시할 수 있다.
- 1의 보수로 표현한 음수에 1을 더하면 2의 보수에 대응하는 음수가 된다.
CPU는 정말 숫자를 알고 있을까?
- 현대 컴퓨터가 2의 보수 표현 방식을 사용하는 근본적인 이유는 이 표현이 비록 사람에게는 직관적이지 않지만 회로 설계를 단순화할 수 있기 때문이다.
- 가산기는 양수와 음수에 대해 전혀 신경 쓰지 않을 뿐만 아니라, ‘0010’이라는 이 연속된 숫자가 가지고 있는 의미조차 이해하지 못한다.
- 숫자가 1의 보수인지 또는 2의 보수를 사용하고 있는지는 사람이 이해하기 위해 필요할 뿐이며, 더 정확하게는 컴파일러가 이해하고 있어야 하는 것이다.
- 사실 프로그래머도 이것을 알 필요가 없지만, 숫자 형식이 가질 수 있는 범위만큼 알고 있어야 한다. 그렇지 않으면 넘침이 발생할 위험이 있다.
- 이것에서 CPU 자체는 인간 두뇌에 존재하는 개념들을 이해할 수 없다는 것을 이해해야 한다.
- 프로그래머는 두뇌의 바다를 헤엄치고 있는 사고 문제를 프로그램 방식으로 표현하고, 컴파일러는 인간이 이해할 수 있는 프로그램을 CPU를 제어할 때 사용하는 0과 1로 구성된 기계 명령어로 변환한다.
- 출력 역시 0과 1의 연속이며, 남은 것을 이를 해석하는 것뿐입니다. 0과 1로 구성된 01001100이라는 값을 받으면 이를 숫자로 인식할 수도 있고 문자열로 인식할 수도 있습니다. 또는 RGB 기반의 색상으로 인식하는 것도 가능하다. 모든 것은 어떻게 해석하는가에 달렸으며, 이것이 소프트웨어가 하는 일이다.
Section 4.4 CPU가 if 문을 만났을 때
배열 요소가 이미 정렬된 상태라면 2.8초 만에 실행이 완료되지만, 배열 요소가 임의로 배치되어 있다면 실행 시간이 무료 7.5초에 달한다. 답을 찾기 위해 리눅스의 perf 도구를 사용하여 프로그램 실행 상태에 대한 초기 단계를 분석할 수 있다. 이 도구로 프로그램이 실행 중일 때 CPU와 관련된 모든 중요한 정보를 확인할 수 있다. 이중 분기 예측 실패율을 나타내는 branch-misses 항목이 차이가 크다. 정렬된 배열을 이용한 프로그램에서는 예측 실패율이 0.02%에 불과하지만, 정렬되지 않은 배열을 이용한 프로그램에서는 최고 14.12%에 달한다.
파이프라인 기술의 탄생
- 1769년 영국인 조사이아 웨지우드가 도자기 공장을 설립했다. 이 공장의 도자기 생산은 부진했지만, 도공 한 명이 처음부터 끝까지 모든 것을 만드는 전통적인 방식과 달리 전체 공정 단계를 수십 개로 나누고 각 단계마다 전문가를 배치했는데 이것이 산업 조립 라인의 최초 형태이다.
- 자동차 한 대를 조립하는 데 프레임 조립, 엔진 설치, 배터리 설치, 품질 검사 네 단계가 필요하고 각 과정에 20분이 소요된다고 하자. 이 모든 과정을 하나의 팀이 전부 담당할 경우 조립을 완료하는 데 총 80분이 필요하다.
- 하지만 각 단계를 전담하는 팀에 넘기면 자동차가 생상되는 전체 과정은 여전히 80분이 필요하지만, 전체 공정 입장에서는 20분마다 자동차 한 대를 생산할 수 있다.
- 즉, 조립 라인은 전체 자동차 조립 시간을 줄이는 것이 아니라 공장의 처리 능력을 늘리는 것이다.
CPU: 메가팩토리와 파이프라인
- CPU 자체를 하나의 메가팩토리(megafactory)로 볼 수 있는데, CPU라는 메가팩토리는 기계 명령어를 실행한다.
- CPU가 하나의 기계 명령어를 실행하는 것을 자동차 한 대를 생상하는 것과 같다고 한다면, 현대 CPU는 1초에 자동차 수십억 대를 생상할 수 있을 정도이다.
- 하나의 기계 명령어를 처리하는 과정은 네 단계로 구분할 수 있다.
- 명령어 인출(instruction fetch), IF 단계
- 명령어 해독(instruction decode), ID 단계
- 실행(execute), EX 단계
- 다시 쓰기(writeback), WB 단계
- 각 단계는 별도의 하드웨어로 처리된다.
- 현재 CPU는 기계 명령어를 초당 수십억 개 처리할 수 있는 능력을 갖추고 있으며, 파이프라인(pipeline) 기술은 필수 불가결하다.
if가 파이프라인을 만나면
- 프로그래머가 작성한 if 문은 일반적으로 컴파일러가 조건부 점프 명령어로 변환하며, 이 명령어는 분기 역할을 한다.
- 조건부 점프 명령어를 실행하기 전까지는 점프해야 할지 알 수 없으며, 이는 파이프라인에 영향을 미친다.
분기 예측: 가능한 한 CPU가 올바르게 추측하도록
- CPU는 뒤이어 어디로 분기할 가능성이 있는지 추측한다. 추측이 맞다면 파이프라인은 계속 앞으로 흘러나갈 것이다. 추측이 틀렸다면 파이프라인에서 이미 실행 중이던 분기 명령어 전부를 무효화한다. CPU 추측이 틀리면 바로 성능 손실이 발생한다.
- 최신 CPU의 이런 ‘추측’ 과정을 분기 예측이라고 한다. 프로그램 실행 이력을 기반으로 예측을 실행하는 등 여러 가지 데이터를 기반으로 한다.
Arr[i]가 256보다 큰가요?라는 조건문이 있다.- 배열이 정렬되어 있으면 if 조건의 결과는 매우 규칙적이다.
- 배열이 정렬되어 있지 않으면 if 조건의 결과는 뒤죽박죽이다.
- 배열이 정렬되어 있으면 CPU의 추측은 거의 전부 들어맞는다. 하지만 배열이 정렬되어 있지 않으면 기본적으로 무작위 이벤트이며, 어떤 예측 전략도 무작위 이벤트에 대응하기란 어렵다.
- 이것이 바로 정렬되지 않은 배열을 사용하면 분기 예측 실패율이 매우 높아지고 프로그램 성능이 떨어지는 이유이다.
- 높은 성능을 요구하는 코드를 작성하고 이 안에 if 문을 사용한다면 CPU가 높은 확률로 추측할 수 있도록 코드를 작성해야 한다.
- 이것이 프로그래밍 언어에 likely/unlikely 매크로가 있는 이유다. 코드를 제일 잘 이해하는 것은 프로그래머이므로, likely/unlikely 매크로를 이용하여 컴파일러에 가능성이 더 높은 분기를 알려 줄 수 있다. 이렇게 하면 컴파일러는 더 목적성을 가지고 최적화를 할 수 있다.
- 최신 CPU의 분기 예측은 매우 정확하므로 정렬되지 않은 배열을 사용하더라도 분기 예측 실패율이 50%에 달하지 않는다.
Section 4.5 CPU 코어 수와 스레드 수 사이의 관계는 무엇일까?
레시피와 코드, 볶음 요리와 스레드
- CPU는 기계 명령어에 따라 프로세스와 스레드를 실행한다.
- 운영 체제 입장에서 볼 때, CPU가 사용자 상태에서 실행하는 명령어는 모두 스레드 또는 특정 스레드에 속해 있다.
- 이것은 볶음 요리와 동일하다. 레시피에 따라 돼지고기를 볶으면 돼지 두루치기 스레드가 되는 것이고, 소시지와 야채를 볶으면 소시지 야채 볶음 스레드가 되는 것이다.
- 요리사 수는 CPU 코어 수에 비유할 수 있으며, 일정 시간 동안 볶을 수 있는 요리수는 스레드 수에 비유할 수 있다.
- CPU 코어 수와 스레드 수 사이에 어떤 필연 관계도 없다. CPU는 하드웨어인데 반해 스레드는 소프트웨어 개념, 더 정확하게는 실행 흐름이자 작업이다. 따라서 단일 코어 시스템에서도 얼마든지 많은 스레드를 생성할 수 있다.
- CPU는 근본적으로 자신이 실행하는 명령어가 어떤 스레드에 속하는지 이해하지 못하며, 사실 CPU 입장에서도 이를 이해할 필요가 없다. 이를 이해해야 하는 것은 운영체제이다.
- CPU가 해야 하는 일은 PC 레지스터(다음 실행할 기계 명령어를 가르키는 역할) 주소에 따라 메모리에서 기계 명령어를 꺼내 실행하는 것 뿐이다.
작업 분할과 블로킹 입출력
- 작업 A와 작업 B 두 작업이 있고 각 작업이 완료되는 데 필요한 시간이 각각 5분이라고 가정해보자. 작업 A와 B를 연속으로 실행하든 스레드 두 개에 담아 병렬로 실행하든 단일 코어 환경에서는 두 작업을 완료하는데 10분이 걸린다.
- 단일 코어 시스템에서 CPU는 일정 시간 동안 단 하나만의 스레드만 실행할 수 있어 스레드 여러 개가 번갈아 실행되기는 하지만 진정한 병렬 처리라고는 할 수 없다.
- 사실 스레드라는 개념은 프로그래머에게 매우 편리한 추상화 방법을 제공한다. 작업 하나를 여러 개로 분할한 후 각각의 하위 작업을 별도의 스레드에 배치하면, 운영 체제에서 이를 스케줄링하고 실행할 수 있으므로 동시에 여러 작업을 실행할 수 있다.
- 예를 들어 그래픽 사용자 인터페이스를 갖추고 있으며 사용자 인터페이스 요소 뒤에서 대량의 계산을 수행해야 한다고 하자. 계산 작업을 별도의 스레드에 넣어 계산을 수행하는 동안 사용자 인터페이스가 멈추는 것을 방지할 수 있다.
- 이외에도 처리해야 하는 작업이 블로킹 입출력과 관려되었을 때 해당 블로킹 호출이 실행되면 운영 체제가 전체 스레드를 일시 중지하므로 해당 호출 뒤에 코드도 실행되지 않는다. 이때 블로킹 입출력 코드를 별도의 스레드에서 실행하면 나머지 코드는 영향 없이 계속 실행될 수 있다. 물론 이것이 높은 동시성을 요구하지 않는 경우에 해당한다.
- 따라서 스레드가 특정 작업을 기다리지 않고 진행하는 것이라면, 이런 상황에서는 필요에 따라 스레드 여러 개를 생성하고 작업을 분할하여 스레드에서 실행해도 된다. 이때 근본적으로 시스템이 단일 코어인지 다중 코어인지는 신경 쓸 필요가 없다.
다중 코어와 다중 스레드
- 더 이상 단일 코어 성능을 끌어올리기가 어려워서 이를 해결하기 위해 다중 코어를 생산하기 시작했다.
- 다중 프로세스도 다중 코어를 최대한 활용할 수 있지만 다중 프로세스 프로그래밍은 매우 번거롭다. 복잡한 프로세스 간 통신 방식이 필요하며, 프로세스 간 전환에 드는 비용과 같은 문제가 있다.
- 스레드 개념이 이런 문제에 대한 좋은 해결책이 되면서 다중 코어 시대의 주인공이 되었다.
- 일반적으로 생성되는 스레드 수는 코어 수와 일정한 선형 관계를 유지해야 한다. 특히 스레드는 많다고 좋은 것이 아님을 잊지 말자.
- 스레드 수가 한계에 달하면 운영 체제 성능이 떨어지기 시작하는데, 이는 한 스레드에서 다른 스레드로 전환할 때 부담이 증가하기 때문이다.
- 스레드 수에 적당하다는 단어를 쓴 것은 단순히 수치화하기가 어렵고 실제로 프로그램을 사용하여 상황에 따라 지속적으로 테스트해야만 값을 얻을 수 있기 때문이다.
Section 4.6 CPU 진화론(상): 복잡 명령어 집합의 탄생
프로그래머의 눈에 보이는 CPU
- 모든 프로그램은 간단한 ‘helloworld’ 프로그램이든 포토샵과 같은 복잡한 대규모 응용 프로그램이든 간에 결국 컴파일러로 하나하나 간단한 기계 명령어로 변환한다. 그렇기에 본질적으로 CPU 입장에서는 프로그램에 따른 차이가 없다. 하나는 많은 명령어를 포함하고, 다른 하나는 적은 수의 명령어를 포함하고 있을 뿐이다.
- 이런 명령어는 실행 파일에 저장되며, 프로그램이 실행되면 메모리에 적재된다. CPU는 단순하게 메모리에서 명령어를 읽어 실행하기만 하면 된다.
CPU의 능력 범위: 명령어 집합
- CPU도 유형에 따라 고유한 능력 범위(circle of competence)를 가지고 있다.
- CPU 능력 범위에는 특별한 이름이 있는데, 바로 명령어 집합(instruction set architecture)이다.
- 서로 다른 형태의 CPU는 다른 유형의 명령어 집합을 가지고 있다.
- 명령어 집합의 유형은 프로그래머가 코드를 작성할 때뿐만 아니라 CPU의 하드웨어 설계에도 영향을 미친다.
- 처음으로 탄생한 명령어 집합인 복잡 명령어 집합 컴퓨터(Complex Instruction Set Computer, CISC)를 살펴보자. 오늘날 데스트톱 PC와 서버에 공통으로 사용되는 x86 구조(architecture)는 복잡 명령어 집합에 기초를 두고 있으며, 이런 x86 프로세서를 생산하는 제조업체는 인텔과 AMD이다.
추상화: 적을수록 좋다
- 1970년까지는 컴파일러가 아직 성숙되지 못했기 때문에 컴파일러를 신뢰하는 사람이 많지 않았다. 때문에 많은 프로그램이 어셈블리어로 작성되었다.
- 이 시기 대부분의 프로그램은 직접 어셈블리어로 작성되었기 때문에 일반적으로 명령어 집합이 더욱더 풍부해야 하며 명령어 자체 기능도 더 강력해야 한다고 여겼다.
- 이렇게 기계 명령어와 고급 언어 개념간 차이를 줄여야만 더 적은 코드로 더 많은 작업을 할 수 있기 때문이다.
코드도 저장 공간을 차지한다
- 오늘날의 컴퓨터는 기본적으로 폰 노이만 구조를 따른다.
- 이 구조의 핵심 사상은 ‘저장 개념에서 프로개름과 프로그램이 사용하는 데이터에 어떤 차이도 없어야 하며, 모두 컴퓨터의 저장 장치 안에 저장될 수 있어야 한다’는 것이다.
- 폰 노이만 구조에서 실행 파일은 기계 명령어와 데이터를 모두 포함하고 있다. 프로그래머가 작성한 코드는 디스크 저장 공간을 차지하며 실행 시에는 메모리에 적재되므로 메모리 저장 공간을 차지한다는 것을 알 수 있다.
- 1974년에 출시된 인텔 1103 메모리 칩은 크기가 고작 1KB에 불과하다.
- 컴퓨터 업계에 동적 램(DRAM) 시대의 서막을 알렸다.
- 동적 램이 우리에게 익숙한 메모리이다.
- 이렇게 작은 메모리에 더 많은 프로그램을 적재하려면 기계 명령어를 반드시 매우 세밀하게 설계해서 프로그램이 차지하는 저장 공간을 줄여야 한다. 이에 따라 다음 요구 사항을 만족해야 한다.
- 하나의 기계 명령어로 더 많은 작업을 완료할 수 있다.
- 기계 명령어 길이가 가변적이다.
- 기계 명령어의 밀도를 높여 공간을 절약하려고 고도로 인코딩(encoding)된다.
필연적인 복잡 명령어 집합의 탄생
- 그러나 얼마 후 새로운 문제가 발견되었다. 이 시기 CPU 명령어 집합은 모두 직접 연결(hardwired) 방식이었다. 이 방법은 명령어를 실행하는 데는 매우 효율적이지만, 유연성이 몹시 떨어지기 때문에 명령어 집합의 변경에 대응하기가 어렵다.
- 문제 본질은 하드웨어를 변경하는 것은 매우 번거롭지만, 소프트웨어는 이와 다르게 쉽게 변경할 수 있다는 것이다.
- 대부분의 명령어에 포함된 연산을 더 간단한 명령어로 구성된 작은 프로그램으로 정의하고 이를 CPU에 저장하면, 모든 기계 명령어에 대응하는 전용 하드웨어 회로를 설계할 필요가 없다.
- 여기에서 사용되는 더 간단한 명령어가 바로 마이크로코드(microcode)이다.
- 단일 복잡 명령어 –> 마이크로코드 ROM –> 마이크로코드
마이크로코드 설계의 문제점
- 시간이 지나면서 또 다른 문제가 생겼다.
- 마이크로코드 설계가 트랜지스터를 매우 많이 소모한다는 것이다.
- 마이크로코드가 야기한 복잡한 문제는 해결하기가 매우 어렵기 때문에 더 나은 설계를 고민하기 시작했다.
Section 4.7 CPU 진화론(중): 축소 명령어 집합의 탄생
- 1980년대에는 ‘최대’ 용량이 64KB인 메모리가 나타나기 시작했다. 마침내 메모리 용량 대비 가격이 급격히 떨어지기 시작했다.
- 또 이 시기에는 컴파일 기술도 장족의 발전을 이루어 컴파일러는 점점 더 쓸 만한 물건이 되어 갔고, 프로그래머도 점점 고급 언어로 프로그램을 작성하기 시작했다.
복잡함을 단순함으로
- CPU는 약 80% 시간 동안 명령어 집합의 기계 명렁 중 20%를 실행한다.
- 마이크로코드 설계 아이디어는 복잡한 기계 명령어를 CPU 내부에서 비교적 간단한 기계 명령어로 변환하는 것이므로, 컴파일러는 이 프로세스를 알지 못한다. 따라서 마이크로코드에 버그가 있으면 컴파일러는 이를 피하기 위해 할 수 있는 일이 아무것도 없다.
- 이외에도 일부 복잡한 기계 명령어가 같은 일을 하는 간단한 명령어 여러 개보다 느리게 실행된다는 사실을 발견했다.
축소 명령어 집합의 철학
- 복잡 명령어 집합에 대한 반성을 바탕으로 축소 명령어 집합(reduced instruction set)의 철학이 탄생했으며, 이는 다음 세 가지 측면에서 주로 반영되었다.
- 명령어 자체의 복잡성: 복잡한 명령어를 제거하고 대신 간단한 명령어 여러 개로 대체하는 것이다. 마이크로코드가 없으면 컴파일러에서 생성된 기계 명령어의 CPU 제어 능력이 크게 향상된다.
- 컴파일러: 컴파일러가 CPU에 대한 더 강력한 제어권을 갖는다는 것이다. 축소 명령어 집합을 사용하는 CPU는 더 많은 세부 사항을 컴파일러에 제공하는데, 축소 명령어 집합은 ‘흥미로은 작업을 컴파일러에게 넘기기(Relegate Interesting Stuff to Complier, RISC)’라는 이름으로 부르기도 한다.
- LOAD/STORE 구조
- 복잡 명령어 집합에서는 기계 명령어 하나만으로 메모리에 데이터를 가져오고(IF), 작업을 수행하고(EX), 해당 데이터를 메모리에 다시 쓰는(WB) 작업을 모두 할 수 있다. 중요한 점은 이 작업이 단지 하나의 기계 명령어로 수행된다는 것이다.
- 축소 명령어 집합에서는 이것이 절대로 불가능한 금기 사항이다. 축소 명령어 집합의 명령어는 레지스터 내 데이터만 처리할 수 있으며, 메모리 내 데이터는 직접 처리할 수 없다.
- 축소 명령어 집합에서는 LOAD/STORE라는 전용 기계 명령어가 메모리를 읽고 쓰기를 책임진다. 다른 명령어들은 CPU 내부의 레지스터만 처리할 수 있으며, 메모리를 읽거나 쓸 수 없다.
복잡 명령어 집합과 축소 명령어 집합의 차이
- 두 숫자를 곱한 값을 계산한 후 결과를 다시 메모리 주소에 기록한다고 가정해 보자.
- 복잡 명령어 집합
- 복잡 명령어 집합 CPU에는 MULT라는 기계 명령어가 있을 수 있다. 아래의 몇 가지 단계는 하나의 명령어로 완료할 수 있다.
- 메모리 주소 A의 데이터를 읽어 레지스터에 저장
- 메모리 주소 B의 데이터를 읽어 레지스터에 저장
- ALU(연산장치)가 레지스터 값을 이용하여 곱셈 연산을 수행
- 곱셈 결과를 다시 메모리에 쓰기
- 복잡 명령어 집합 CPU에는 MULT라는 기계 명령어가 있을 수 있다. 아래의 몇 가지 단계는 하나의 명령어로 완료할 수 있다.
- 축소 명령어 집합
- 위의 4가지 작업에 각각 대응하는 명령어를 사용해야 한다.
- LOAD: 메모리에서 레지스터로 데이터를 적재
- PROD: 두 레지스터에 저장된 숫자의 곱셈 연산 수행
- STORE: 레지스터의 데이터를 다시 메모리에 쓰기
- 위의 4가지 작업에 각각 대응하는 명령어를 사용해야 한다.
- 복잡 명령어 집합
- 축소 명령어 집합을 사용하는 프로그램은 복잡 명령어 집합보다 더 많은 저장 공간이 필요하다. 하지만 축소 명령어 집합 설계의 의도는 프로그래머가 직접 어셈블리어로 코드를 작성하는 것이 아니라, 이 작업을 컴파일러에 맡기고 컴파일러가 구체적인 기계 명령어를 자동으로 생성하게 하는 것이다.
명령어 파이프라인
- 축소 명령어 집합에서 생성된 명령어들은 매우 간단하므로 CPU 내에서 코드를 해석하는 데 복잡한 하드웨어 구조가 필요하지 않아 더 많은 트랜지스터를 절약할 수 있다. 그리고 이렇게 절약한 트랜지스터는 CPU의 다른 기능에 활용할 수 있다.
- 또한, 각 명령어가 매우 간단하여 실행 시간이 거의 동일하다는 것이다.
- 여기에 파이프라인 기술을 이용해 기계 명령어 실행 효율을 높일 수 있다.
- 파이프라인 기술은 비록 기계 명령어 하나가 실행되는 시간을 단축해 주지는 않지만 처리량을 늘릴 수 있다.
- 모든 명령어의 실행 시간을 대체적으로 동일하게 하여 가능한 한 파이프라인이 더 높은 효율로 기계 명령어들을 처리할 수 있도록 노력하고 있다.
- 축소 명령어 집합 구조에서 컴파일된 프로그램에는 더 많은 명령어가 필요하다. 하지만 축소 명령어 집합의 간소화된 설계는 마이크로코드가 없기 때문에 더 적은 트랜지스터가 필요하며, 더 작은 CPU를 만들 수 있다. 또 더 높은 클럭 주파수를 가지게 되어 축소 명령어 집합 구조의 CPU는 동일한 작업을 할 때 복잡 명령어 집합 구조보다 훨씬 우수하다.
천하에 명성을 떨치다
- 1980년대 후반에는 축소 명령어 집합으로 설계된 CPU가 성능 면에서 기존 모든 전통적인 설계를 가볍게 진압하기에 이른다.
- 1987년 축소 명령어 집합 기반의 MIPS R2000 프로세서의 성능은 복잡 명령어 집합 구조를 사용하는 x86 플랫폼 인텔 i386DX의 두세 배에 달했다.
- 결국 다른 모든 CPU 제조업체는 축소 명령어 집합을 따르고, 축소 명령어 집합의 설계 사상을 적극적으로 채택했다.
- x86은 복잡 명령어 집합 기반
Section 4.8 CPU 진화론(하): 절체절명의 위기에서 반격
- 함수를 사용하는 큰 장점은 다음 문장으로 집약된다. “함수의 인터페이스가 변경되지 않는 한 함수를 사용하는 코드는 변경될 필요가 없다. 심지어 함수 내부 구현은 여러분이 원하는 대로 변경할 수 있다.” 즉, 함수 인터페이스는 외부에 내부 구현을 숨긴다.
- 그렇다면 CPU에 있어 ‘인터페이스’란 명령어 집합이다. 인터페이스에 해당하는 명령어 집합은 변경할 수 없지만 CPU 내부 구현, 즉 명령어 실행 방식은 변경이 가능하다.
이길 수 없다면 함께하라: RISC와 동일한 CISC
- 마이크로 명령어(micro-operation): 복잡 명령어 집합의 명령어를 CPU 내부에서 축소 명령어 집합의 간단한 명령어로 변환한 것
- 축소 명령어 집합의 명령어와 마찬가지로 마이크로 명렬러도 매우 간단하며 실행 시간도 거의 같기 때문에 축소 명령어 집합과 마찬가지로 파이프라인 기술을 충분히 활용할 수 있다.
- 이 방식은 복잡 명령어 집합의 호환성을 유지하면서 동시에 축소 명령어 집합의 장점을 얻을 수 있기 때문에 일석이조이다.
하이퍼스레딩이라는 필살기
- 복잡 명령어 집합 진영은 또 다른 기술을 개발했는데, 바로 하이퍼스레딩(hyper-threading)이다.
- 하이퍼스레딩은 하드웨어 스레드(hardware thread)라고도 한다.
- CPU가 한 번에 한 가지 일만 할 수 있다고 간단하게 간주할 수 있다.
- 시스템에 N개의 CPU 코어가 있다면 운영 체제는 N개의 준비 완료 상태인 스레드를 N개의 CPU 코어에 할당해서 동시에 실행할 수 있다.
- 하지만 하이퍼스레딩을 사용하면 실제로는 컴퓨터 시스템에 물리 CPU 코어가 하나만 있지만 운영 체제는 논리적으로 CPU 코어가 여러 개 있는 것으로 인식한다.
- 하이퍼스레딩 기술이 탑재된 CPU는 한 번에 스레드 두 개에 속하는 명령어 흐름을 처리할 수 있으며, 이를 통해 CPU 코어 한 개가 CPU 코어 여러 개인 것처엄 보이게 할 수 있다.
- 소프트웨어 스레드, 즉 프로그래머가 인지할 수 있는 스레드 생성, 스케줄링, 관리의 운영주체는 운영체제
- 반면에 하이퍼스레딩은 CPU 하드웨어의 기능으로 운영 체제와는 상관없다.
장점은 취하고 약점은 보완하다: CISC와 RISC의 통합
- 하이퍼스레딩 기술은 복잡 명령어 집합 진영에서 제안되었지만 이 기술은 축소 명령어 집합에도 도입이 가능하다.
- 이렇게 복잡 명령어 집합과 축소 명령어 집합은 끊임없이 서로의 장정은 취하고 약점은 보완하고 있다.
- 비록 두 구조가 점점 닮아 가고 있음에도 복잡 명령어 집합과 축소 명령어 집합에는 다음과 같은 분명한 차이가 있다.
- 축소 명령어 집합에서 컴파일러는 여전히 중요한 역할을 하며, 축소 명령어 집합은 명령어 길이가 일정하기 때문에 컴파일러 최적화에 여전히 더 많은 장점이 있다.
- 메모리에 접근할 때 축소 명령어 집합은 여전히 LOAD/STORE 구조인데 반해, 복잡 명령어 집합에는 이런 설계가 없다.
- 이제 복잡 명령어 집합과 축소 명령어 집합 구현의 기술적 차이점은 상업적으로 보이는 것만큼 크지 않다.
기술이 전부는 아닌다: CISC와 RISC 간 상업적 전쟁
- 1980~1990년대 축소 명령어 집합 사상의 출현은 프로세서 영역을 크게 발전시켰다.
- 당시 x86 프로세서는 축소 명령어 집합 프로세서에 비해 확실히 성능적으로 열세였지만, x86에는 소프트웨어 생태계라는 매우 훌륭한 기반이 존재했다.
- 특히 인텔의 CPU와 윈도의 소프트웨어를 기반으로 형성된 윈텔(WinTel) 연합은 이 소프트웨어 생태계를 기반으로 끊임없이 번영했다.
- 동시에 x86은 축소 명령어 집합에서 여러 가지 우수한 사상들을 흡수하여 내부적으로 축소 명령어 집합과 유사한 방식으로 명령어를 실행했고 그 과정도 더 훌륭했다.
- 이런 노력으로 윈텔 연합이 컴퓨터 시장을 점렴하게 됐다.
- 애플의 매킨토시 컴퓨터 사업은 2006년에 축소 명령어 집합 기반의 파워PC 프로세서 사용을 포기하고 인텔의 x86 프로세서를 도입한다.
- ARM으로 대표되는 축소 명령어 집합 진영은 임베디드와 저전력 영역으로 후퇴했다.
- 인텔은 끊임없는 노력 끝에 상업적으로 큰 성공을 거두었다.
- 그러나 2007년에 아이폰이 출시되면서 모바일 인터넷 시대에 진입하기 시작했다.
- 오늘날 스마트폰은 거의 모두 축소 명령어 집합을 채택한 ARM의 프로세서를 탑재하고 있으며 인텔과 마이크로소프트는 모바일 시장을 잃고 말았다.
- 애플은 과거 인텔의 성공을 재현하기 시작했다. 자체 개발한 A 시리즈 모바일 프로세서의 성능은 점점 높아져 데스크톱 프로세서의 성능에 필적하는 수준이 되었다. 그 결과 M1 칩이 탄생했다. 이 칩의 프로세서는 축소 명령어 집합의 ARM을 기반으로 하고 있다.
- CPU는 컴퓨터에서 가장 핵심적인 하드웨어로 하는 작업은 매우 간단해서 메모리에서 명령어를 가져와 실행하는 것이 전부이다. 그러나 소프트웨어 관점에서 보면, 코드는 하나하나 실행되지 않고 함수 호출, 시스템 호출, 스레드 전환, 인터럽트 처리 등으로 끊어진다.
Section 4.9 CPU, 스택과 함수 호출, 시스템 호출, 스레드 전환, 인터럽트 처리 통달하기
함수 호출로 프로그래머는 코드 재사용성을 개선할 수 있고, 시스템 호출로 프로그래머는 운영 체제에 요청을 보낼 수 있다. 프로세스와 스레드 전환으로 댜중 작업(multitasking)이 가능할 뿐만 아니라 인터럽트 처리로 운영 체제가 외부 장치를 관리하게 할 수 있다.
레지스터
- CPU에 레지스터가 필요한 이유는 속도 때문이다.
- 사실 레지스터와 메모리는 본질적으로 차이가 없으며, 둘 다 정보를 저장하는 데 사용한다. 단지 레지스터의 읽기와 쓰기 속도가 훨씬 빠르고 제조 비용도 훨씬 비싸기 때문에 용량에 한계가 있을 뿐이다. 따라서 어쩔 수 없이 프로세스의 실행 시 정보를 모두 메모리에 저장하고 CPU가 사용할 때만 임시로 레지스터에 데이터를 보관하는 것이다.
스택 포인터
- 모든 함수는 스택 프레임을 가진다.
- 스택의 가장 중요한 정보는 스택 상단(stack top)으로, 이 스택 상단 정보는 스택 하단(stack bottom)을 가리키는 스택 포인터(stack pointer)에 저장된다.
- 스택 프레임(stack frame): 함수가 실행될 때 함수에 정의된 로컬 변수와 매개변수 등을 저장하는 독립적인 메모리 공간
명령어 주소 레지스터
- 프로그램 카운터(program counter, PC) 또는 명령어 포인터(instruction pointer, IP)라고 부른다. 이 책에서는 PC 레지스터라고 부른다.
- 프로그램이 실행되면 첫 번째로 실행할 기계 명령어의 주소가 PC 레지스터에 저장되며, 이 주소를 따라 메모리에서 명령어를 가져와 실행한다.
- CPU의 PC 레지스터를 제어하는 것은 CPU의 실행 흐름을 장악하는 것이며, 기계 명령어가 직접 실행 상태에 따라 CPU가 다음에 어떤 명령어를 실행해야 하는지 결정할 수 있게 된다.
상태 레지스터(status register)
- x86 구조에서는 FLAGS 레지스터라고 하며, ARM 구조에서는 응용 프로그램 상태 레지스터(application program status register)라고 한다.
- 예를 들어 산술 연산이 포함된 명령어는 수행 중에 자리 올림수(carry)가 발생하거나 넘침(overflow)이 발생할 수 있다. 이때 이런 정보는 상태 레지스터에 저장된다.
- CPU가 현재 어떤 상태(커널 상태 또는 사용자 상태)에서 동작 중인지 표시하는 특정한 비트가 있다.
상황 정보
- 프로그램의 실행 시 상황 정보를 가져오고 저장할 수 있다면 언제든지 프로그램의 실행을 일시 중지할 수 있으며, 반대로 이 정보를 이용하여 언제든지 프로그램의 실행을 재개할 수도 있다.
- 근본적인 원인은 CPU가 엄격한 오름차순(ascending order)으로 기계 명령어를 실행하지 않기 때문이다.
- 함수 호출: CPU는 함수 A에서 함수 B로 점프할 수 있다.
- 시스템 호출: CPU는 커널 코드를 실행하기 위해 사용자 상태에서 커널 상태로 전환할 수 있다.
- 스레드 전환: CPU는 프로그램 A의 기계 명령어 실행 상태에서 프로그램 B의 기계 명령어 실행 상태로 전환할 수 있다.
- 인터럽트 처리: CPU는 인터럽트를 처리하기 위해 실행하던 프로그램을 중지시킬 수 있다.
- 위 네 가지 기능은 모두 상황 정보의 저장과 복원에 의존한다.
중첩과 스택
- 중단과 재개는 중첩된 구조를 가진다.
- 스택은 이런 중첩 구조를 처리하기 위해 탄생했다.
- 함수 호출, 시스템 호출, 스레드 전환, 인터럽트 처리는 모두 중첩 구조이기 때문에 스택을 이용하여 처리할 수 있다.
함수 호출과 실행 시간 스택
- 함수를 호출할 때 어려운 점은 CPU가 호출된 함수의 첫 번째 기계 명령어로 점프한 이후 함수 실행이 완료되면, 다시 원래 위치로 점프해야 한다는 것이다.
- 이는 함수 상태의 보존과 복원을 포함하는데, 보존해야 하는 상태 정보에는 반환 주소뿐만 아니라 사용한 레지스터 정보 등도 포함된다.
- 모든 함수 실행시 모두 독점적인 자신만의 저장 공간을 가지고 있으며, 이 저장 공간에 함수 실행 시 상태 정보를 저장할 수 있다. 그리고 이 저장 공간을 스택 프레임이라고 한다.
시스템 호출과 커널 상태 스택
- 디스크에서 파일을 읽고 쓰거나 새로운 스레드를 생성할 때, 파일을 읽고 쓰는 작업은 운영 체제가 한다.
- 운영 체제 역시 내부적으로 이 요청을 처리하는 함수를 호출해야 한다. 그리고 함수를 호출할 때는 실행 시간 스택이 필요하다.
- 커널 상태 스택(kernel mode stack): 운영 체제가 시스템 호출을 완료하는 데 필요한 실행 시간 스택
- CPU가 해당 명령어를 실행할 때 사용자 상태에서 커널 상태로 전환되며, 커널 상태에서 사용자 상태 스레드에 대응하는 커널 상태 스택을 찾은 후 여기에서 대응하는 커널 코드를 실행하여 시스템 호출 요청을 처리한다.
- 이때 사용자 상태 스레드의 레지스터 정보와 같은 실행 상황 정보는 커널 상태 스택에 저장되는 것에 유의해야 한다.
인터럽트와 인터럽트 함수 스택
- 인터럽트는 본질적으로 현재 CPU의 실행 흐름을 끊고 특정 인터럽트 처리 함수로 점프하며, 인터럽트 처리 함수의 실행이 완료되면 원래 위치로 다시 점프한다.
- 인터럽트 처리 함수의 실행 시간 스택은 어디에 있을까?
- 인터럽트 처리 함수에 자체적인 실행 시간 스택이 없는 경우, 인터럽트 처리 함수는 커널 상태 스택을 이용하여 인터럽트 처리를 실행한다.
- 인터럽트 처리 함수에 인터럽트 처리 함수(interrupt service routine) 스택, 즉 ISR 스택이라는 자체적인 실행 시간 스택이 있는 경우, 인터럽트를 처리하는 것은 CPU라서 모든 CPU가 자신만의 인터럽트 처리 함수 스택을 가진다.
- 사실상 인터럽트 처리 함수와 시스템 호출은 비교적 유사하지만, 시스템 콜은 사용자 상태 프로그램이 직접 실행하는 데 반해 인터럽트 처리는 외부 장치로 실행된다는 차이점이 있다.
스레드 전환과 커널 상태 스택
- 시스템에 A, B 두 스레드가 있을 때 스레드 A는 현재 실행 중이라고 가정하자.
- 시스템 내부의 타이머가 인터럽트 신호를 발생시키면 CPU는 인터럽트 신호를 수신한 후 현재 스레드의 실행을 일시 중지한다.
- 이어서 사용자 상태에서 커널 상태로 전환되며 커널 안의 타이머 인터럽트 처리 프로그램(timer interrupt handler)을 실행한다.
- 스레드 A의 시간 조각(time slice)이 모두 사용되었다면, CPU는 스레드 B와 같은 다른 스레드에 할당되야 한다.
- 이 작업을 스레드 전환이라고 하며, 다음과 같은 두 가지 작업을 포함한다.
- 주소 공간 전환
- CPU를 스레드 A에서 B로 전환하는 것, 이 작업의 주된 내용은 스레드 A의 CPU 상황 정보를 저장하고 스레드 B의 CPU 상황 정보를 복원하는 것을 포함한다.
- 모든 리눅스 스레드에는 각각에 대응하는 프로세스 서술자(process descriptor)인 task_struct 구조체가 있으며, 그 안에 thread_struct 구조체가 CPU의 상황 정보를 저장하는 역할을 한다.
- 실행 중인 스레드 A의 CPU 상황 정보를 스레드 A의 서술자에 저장하고, 스레드 B의 서술자에 저장된 상황 정보를 CPU로 복원한다.
Chapter 5. 작은 것으로 큰 성과 이루기, 캐시
폰 노이만 구조(Von Neumann architecture)에서는 기계 명령어와 명령어에서 사용하는 데이터가 메모리에 저장되어 있어야 하며, CPU가 기계 명령어를 실행할 때 먼저 명령어를 메모리에서 읽어야 한다. 또 명령어를 실행하는 과정에서 데이터를 메모리에서 읽어야 할 수도 있다. 그뿐만 아니라 명령어가 계산 결과 저장을 포함할 때는 이를 다시 메모리에 저장해야 한다. 프로그램이 실행되는 동안 CPU는 메모리와 빈번하게 상호 작용을 해야 한다.
Section 5.1 캐시, 어디에나 존재하는 것
폰 노이만 구조는 CPU가 실행하는 기계 명령어와 명령어가 처리하는 데이터가 모두 메모리에 저장되어 있어야 한다는 사실을 알려준다. 하지만 레지스터 용량은 극히 제한되어 있어 CPU는 반드시 빈번하게 메모리에 접근하여 명령어와 데이터를 가져와야 한다.
CPU과 메모리 속도 차이
- 사실 시스템 성능은 속도가 상대적으로 느린 쪽에 맞추어 제한되므로 CPU와 메모리의 속도가 같아야 가장 좋은 성능을 발휘할 수 있다.
- 일반적인 시스템에서 메모리의 속도는 CPU의 100분의 1에 불과하다.
도서관, 책상, 캐시
- 최신 CPU는 메모리 사이에 캐시 계층이 추가되어 있다. 캐시는 가격이 비싸고 용량이 제한적이지만 접근 속도가 거의 CPU 속도에 필적한다.
- 캐시 안에는 최근에 메모리에서 얻은 데이터가 저장되며, CPU는 메모리에서 명령어와 데이터를 꺼내야 할 때도 무조건 먼저 캐시에서 해당 내용을 찾는다. 캐시가 적중하면 메모리에 접근할 필요가 없어 CPU가 명령어를 실행하는 속도를 크게 끌어올리는 목적을 쉽게 달성할 수 있다.
- 일반적으로 x86 같은 최신 CPU와 메모리 사이에는 실제로 세 단계의 캐시가 추가되어 있으며, L1 캐시, L2 캐시, L3 캐시로 구분된다. 캐시 단계에 따라 접근 속도는 낮아지지만 용량은 증가한다.
- L1 캐시, L2 캐시, L3 캐시, CPU 코어는 레지스터 칩 내에 묶여 패키징(packaging)되어 있다.
공짜 점심은 없다: 캐시 갱신
- 캐시를 추가하면 시스템 성능이 극적으로 향상될 수 있지만, 이것에는 그만큼 대가도 따른다.
- 캐시의 데이터는 갱신되었지만 메모리의 데이터는 아직 예전 것이 남아 있게 되는데, 이것이 바로 불일치(inconsistent) 문제이다.
- 가장 간단한 해결 방법은 캐시를 갱신할 때 메모리도 함께 갱신하는 것이다. 이 방식을 연속 기입(write-through)이라고 한다. CPU는 메모리가 갱신될 때까지 대기하고 있어야 하는데, 이는 분명히 동기식 설계 방법에 해당한다.
- CPU가 메모리에 기록할 때는 캐시를 직접 갱신하지만, 이때 메모리가 갱신이 완료되기를 기다릴 필요 없이 CPU는 계속해서 다음 명령어를 실행할 수 있다. 그러다 캐시 용량이 부족하면 반드시 자주 사용되지 않는 데이터를 제거해야 하는데, 이때 캐시에서 제거된 데이터가 수정된 적이 있다면 메모리에 갱신해야 한다. 이렇게 캐시의 갱신과 메모리의 갱신이 분리되므로 이 방식은 비동기에 해당하며, 이를 후기입(write-back)이라고 한다. 연속 기입보다 훨씬 복잡하지만 성능은 분명히 더 낫다.
세상에 공짜 저녁은 없다: 다중 코어 캐시의 일관성
- 단일 CPU 성능은 쉽게 향상되지 않지만, 그 숫자는 늘릴 수 있다. 이렇게 CPU는 다중 코어 시대에 진입했으며 프로그래머는 ‘고생길’이 열렸다.
- 예를 들어 시스템에 Core1(C1)과 Core2(C2)라는 CPU 코어가 두 개 있다면, 이 두 코어에서 서로 다른 스레드 두 개가 실행된다. 이 두 스레드가 모두 메모리 내 X 변수에 접근해야 한다고 가정해 보자.
- 메모리의 X 변수에 대해 C1과 C2의 캐시에 각각 복사본을 가지게 된다.
- C1에서 X를 수정 후 캐시를 갱신할 때, C2 캐시의 X 값은 동기적으로 수정되지 않는다.
- X 변수는 두 CPU 코어의 캐시에서 불일치 문제가 발생한다.
- 이제 CPU는 변수를 업데이트할 때 단순히 자체 캐시와 메모리만 신경 쓰는 것이 아니라 해당 변수가 다른 CPU 코어의 캐시에도 있는지 확인하고, 있다면 해당 캐시도 갱신해야 한다.
- 최신 CPU에는 고전적은 MESI 규칙같은 다중 코어 캐시의 일관성을 유지하는 규칙이 있다.
- MESI 규칙(MESI protocol): 캐시의 데이터 수정(modified), 배타(exclusive), 공유(shared), 무료(invalid) 네 가지 상태를 부여하여 다중 코어 캐시의 일관성을 관리하는 규칙이다.
메모리를 디스크의 캐시로 활용하기
- 디스크는 탐색(seek)을 위해 10ms 가량의 시간이 소요된다. 메모리와 비교하면 메모리 접근 속도는 디스크 탐색 속도보다 10만 배 가량 빠르다.
- 파일을 읽을 때 먼저 데이터를 디스크에서 메모리로 옮겨야 CPU가 메모리에서 파일의 데이터를 읽을 수 있다.
- 디스크의 접근 속도는 매우 느리기 때문에 읽어 온 메모리 내 데이터를 최대한 잘 활용해야 한다. 따라서 이 메모리에 있는 데이터를 디스크의 캐시로 사용하는 것이다.
- 운영 체제는 여유 메모리 공간을 디스크의 캐시로 활용하여 디스크에서 데이터를 읽어 오는 일을 최소화한다. 이것은 리눅스 운영 체제에서 페이지 캐시의 기본 원리에 해당한다.
- 캐시가 추가되면 반드시 캐시 갱신 문제가 발생한다.
- 서버에서는 최근 메모리가 디스크를 대체하는 것이 대세이다. 메모리가 점점 더 저렴해지고 있기 때문이다. 일부 상황에서는 데이터베이스를 전부 메모리에 직접 설치하여 디스크 입출력이 필요하지 않을 때도 있다. 프레스토(Presto), 플링크(Flink), 스파크(Spark) 같은 메모리 기반 시스템이 디스크 기반의 경쟁자들을 빠르게 대체하고 있다.
- 그러나 이는 메모리가 디스크를 완전히 대체할 수 있다는 말은 아니다. 메모리는 데이터를 영구적으로 저장할 수 있는 기능이 없기 때문이다. 하지만 메모리 용량이 증가함에 따라 메모리 용량 때문에 디스크에 의존해야 했던 많은 서비스가 다시 메모리로 옮겨 가고 있는 형국이다.
가상 메모리와 디스크
- 시스템에 프로세스가 N개 있을 때, 이 프로세스 N개가 실제 물리 메모리를 모두 사용하고 있을 때, 새로운 프로세스가 생성되어 이 N+1번째 프로세스도 메모리를 요청한다고 가정해보자.
- 파일을 읽고 쓸 때 메모리를 디스크의 캐시로 쓸수 있는데 이때 디스크는 메모리의 ‘창고’ 역할을 할 수 있다.
- 일부 프로세스에서 자주 사용하지 않는 메모리 데이터를 디스크에 기록하고 이 데이터가 차지하던 물리 메모리 공간을 해제한다. 그러면 N+1번째 프로세스가 다시 메모리를 요청할 수 있다.
- 이 모든 과정은 프로그래머가 인식할 수 없으며, 운영 체제가 우리를 대신하여 일하고 있다.
- 프로세스 주소 공간의 데이터는 디스크로 대체될 수 있으므로 우리 프로그램이 디스크 입출력을 포함하고 있지 않더라도, 특히 메모리 사용률이 매우 높을 경우에는 CPU가 우리 프로그램을 실행할 때도 디스크에 접근해야 할 수 있다.
CPU는 어떻게 메모리를 읽을까?
- 다음 가설은 운영 체제가 가상 메모리를 사용한다고 가정한 것이다.
- CPU가 볼 수 있는 것은 모두 가상 메모리 주소이다. CPU가 메모리를 사용할 때 실행하는 읽기와 쓰기 명령어가 사용하는 것도 역시 가상 메모리 주소이다.
- 이 주소는 실제 물리 메모리 주소로 변환되어야 한다.
- 변환이 완료되면 캐시를 검색하기 시작한다.
- L1, L2, L3 캐시 중 어떤 계층이든 찾을 수 있다면 바로 직접 반환하며, 찾을 수 없을 때만 어쩔 수 없이 메모리에 접근하기 시작한다.
- 여기에서 주의할 점은 가상 메모리의 존재로 프로세스 데이터는 디스크에 임시로 보관되어 있을 수 있다는 것이다. 이때는 해당 데이터를 메모리에서도 찾을 수 없을 가능성이 있으며, 디스크의 프로세스 데이터를 메모리에 다시 적재한 후 메모리를 읽어야 한다.
분산 저장 지원
- 빅 데이터 시대가 도래했고, 단일 장치의 디스크만으로는 더 이상 방대한 사용자 데이터를 완전히 저장할 수 없다.
- 대용량 데이터의 저장 문제를 해결하는 것은 간단하다. 장치 한 대로 부족하다면 여러 대를 사용하면 된다. 이것이 바로 분산 파일 시스템(distributed file system)이다.
- 사용자 장치는 분산 파일 시스템을 직접 장착(mount)할 수 있고, 로컬 디스크(local disk)는 원격의 분산 파일 시스템에서 전송된 파일을 저장한다. 따라서 이를 사용할 때는 네트워크를 통하지 않고 로컬 디스크에 직접 접근하므로 로컬 디스크를 원격의 분산 파일 시스템의 캐시로 간주할 수 있다.
- 응답 속도를 더 높이려고 원격 분산 파일 시스템의 데이터를 데이터 흐름(data stream) 형태로 직접 로컬 시스템의 메모리로 끌어올 수도 있습니다. 이런 사용 패턴은 현재 매우 보편적인 형태로, 메시지 미들웨어인 아파치 카프카(apache kafka) 시스템의 경우 대용량 메시지는 원격 분산 파일 시스템에 저장되어 있지만 실시간으로 해당 데이터의 소비자에게 전달된다. 이 경우 메모리를 원격 분산 파일 시스템의 캐시로 간주할 수 있다.
Section 5.2 어떻게 캐시 친화적인 프로그램을 작성할까?
최신 컴퓨터 시스템에서는 프로그램이 메모리에 접근할 때 캐시의 적중률이 매우 중요하다.
프로그램 지역성의 원칙(locality of reference or principle of locality)
- 프로그램 지역성의 원칙의 본질은 프로그램이 ‘매우 규칙적으로’ 메모리에 접근한다는 것이다.
- 프로그램이 메모리 조각에 접근하고 나서 이 조각을 여러 번 참조하는 경우를 시간적 지역성(temporal locality)이라고 한다.
- 시간적 지역성은 캐시 친화성이 매우 높은데, 이는 데이터가 캐시에 있는 한 메모리에 접근하지 않아도 반복적으로 캐시의 적중이 가능하다는 단순한 이유 때문이다.
- 프로그램이 메모리 조각을 참조할 때 인접한 메모리도 참조할 수 있는데, 이를 공간적 지역성(spatial locality)이라고 한다. 공간적 지역성 역시 캐시 친화적이다. 일반적으로 요청한 메모리의 인접 데이터도 함께 캐시에 저장되므로 프로그램이 인접 데이터에 접근할 때 캐시가 적중하게 된다.
메모리 풀 사용
- 메모리를 동적으로 할당받을 때 일반적으로 malloc을 사용하는데, 문제점이 있다. 프로그램이 메모리에서 조각을 N개 할당받아야 하는 경우 메모리 조각 N개가 힙 영역의 이곳저곳에 흩어져 있을 가능성이 높기 때문에 공간적 지역성이 그다지 좋지 않다.
- 메모리 풀을 초기화할 때 일반적으로 연속적인 메모리 공간을 할당받으며, 우리가 사용하는 데이터 역시 이 연속적인 메모리 공간 내에서 요청되므로 데이터가 매우 집중적으로 모여 있는 형태로 접근이 가능하다. 따라서 이 경우 공간적 지역성이 우수하며 캐시의 적중률도 훨씬 더 높아진다.
struct 구조체 재배치
-
다음과 같이 연결 리스트의 구조체를 정의한다.
#define SIZE 100000 struct List { List* next; // 다음 노드를 가리키는 포인터 int arr[SIZE]; // 배열 int value; // 값 }- 만약 연결 리스트에서 빈번하게 사용되는 항목은 next 포인트와 value 값이며, 배열 arr는 전혀 사용되지 않는다면,
- next 포인터와 value 값이 배열 arr에 의해 멀리 떨어져 있기 때문에 공간적 지역성이 나빠질 수 있다.
- 따라서 좋은 방법은 next 포인터와 value 값을 함꼐 배치하는 것이다.
#define SIZE 100000 struct List { List* next; int value; int arr[SIZE]; }
핫 데이터와 콜드 데이터의 분리
- 위의 구조체를 더 최적화할 수 있는데, 마찬가지로 next 포인터와 value 값을 빈번하게 접근하지만 배열 arr는 거의 접근하지 않는다고 가정해 보자.
- 프로그래머는 캐시 용량이 제한되어 있다는 점을 반드시 인식하고 있어야 한다. 연결 리스트 자체가 차지하는 저장 공간이 크면 클수록 캐시에 저장할 수 있는 노드는 줄어든다.
#define SIZE 100000
struct List {
List* next;
int value;
struct Arr* arr; // 구조체를 가리키는 포인터로 수정
}
struct Arr {
int arr[SIZE];
}
- List 구조체 크기는 크게 줄어들고 캐시는 더 많은 노드를 저장할 수 있다.
- 여기에서 구조체의 배열 arr는 콜드 데이터(cold data)이며, next 포인터와 value 값은 더 빈번하게 접근하는 핫 데이터(hot data)이다.
- 콜드 데이터와 핫 데이터를 서로 분리하면 더 나은 지역성을 얻을 수 있다. 물론 이런 방법을 사용하려면 구조체의 각 항목마다 접근 빈도를 알고 있어야 한다.
캐시 친화적인 데이터 구조
- 지역성 원칙 관점에서는 배열이 연결 리스트보다 낫다. 배열은 하나의 연속된 메모리 공간에 할당되지만, 연결 리스트는 일반적으로 이곳저곳에 흩어져 있을 수 있기 때문이다.
- 여기에서 다루는 데이터 구조의 장단점 논의는 캐시 친화적인가 그렇지 않은가에 국한된다. 실제로 사용할 때는 구체적인 상황에 맞추어 선택해야 한다.
- 예를 들어 배열의 공간적 지역성은 연결 리스트보다 낫지만, 상황에 따라 노드가 빈번하게 추가되고 삭제될 때는 연결 리스트가 배열에 비해 우수한 것이 명백하다.
- 최적화를 할 때는 반드시 일종의 분석 도구를 사용하여 캐시 적중률이 시스템 성능의 병목(bottleneck)이 되는지 판단해야 한다. 병목이 되지 않는다면 굳이 최적화를 할 필요가 없다.
다차원 배열 순회
- 2차원 배열을 합산하는 코드가 있다고 가정해 보자.
- 배열을 행(row)과 열(column) 순서로 순회하면서 값을 모두 더하는데, C언어는 행 우선 방식으로 배열을 저장한다.
- 캐시가 최대 네 개의 데이터를 저장할 수 있다고 가정하면,
- 캐시에 아직 데이터가 없기 때문이 캐시는 비어 있다.
- 배열 0번째를 포함한 요소 네 개가 캐시에 저장된다.
- 1부터 3에 접근할 때는 모두 캐시가 적중하기 때문에 메모리에 접근할 필요가 없다.
- 하지만 4번째 접근할 때는 캐시가 적중할 수 없는데, 이는 캐시 용량이 제한되어 있기 때문이다.
- 4번째 요소에 접근할 때 캐시가 적중에 실패하면, 다시 4를 포함한 후 요소 네 개가 캐시에 저장되어 이전 데이터와 교체된다.
- 이후 접근 패턴은 동일하다.
- 이때 캐시 적중률은 75%이므로 꽤 괜찮아 보인다.
- 배열에 접근할 때 행 우선 방식이 아니라 열 우선 방식으로 접근해 보자.
- 첫 번째 요소인 0에 접근하면 아직 캐시가 적중할 수 없다.
- 마찬가지로 0부터 3까지 캐시에 저장한다.
- 하지만 다음에 접근할 요소는 8이며, 캐시가 적중할 수 없다. 캐시는 어쩔 수 없이 0에서 3의 데이터를 버리고 8부터 11까지 요소를 다시 저장한다.
- 이후 접근 패턴은 동일하다.
- 이때 키시 적중률은 0이다.
Section 5.3 다중 스레드 성능 방해자
캐시와 메모리 상호 작용의 기본 단위: 캐시 라인
- 프로그램이 어떤 데이터에 접근하면 다음에는 인접한 데이터에 접근할 가능성이 높으므로 접근해야 할 데이터만 캐시에 저장하는 것은 현명하지 않다. 따라서 더 나은 방법은 해당 데이터가 있는 곳의 ‘묶음’ 데이터를 캐시에 저장하는 것이다. 이 ‘묶음’ 데이터는 캐시 라인(cache line)이라는 이름을 갖고 있다.
- 이 ‘묶음’ 데이터의 크기는 일반적으로 64바이트이며, 캐시가 적중하지 못하면 이 ‘묶음’ 데이터가 캐시에 저장된다.
첫 번째 성능 방해자: 캐시 튕김 문제
- 첫 번째 프로그램은 두 개의 스레드를 시작하는데, 각각의 스레드는 전역 변수 a 값을 1씩 5억 번 증가시킨다.
- 두 번째 프로그램은 단일 스레드로 전역 변수 a 값을 1씩 10억 번 증가시킨다.
- 첫 번째 프로그램이 더 빠를 뿐만 아니라 실행 시간이 두 번째 프로그램의 절반에 불과하다고 생각할 수 있다.
- 하지만 실제 결과는 두 번째 프로그램의 실행 시간이 두 배 더 빠르다.
- perf stat 명령어 도구를 사용하여 두 프로그램을 분석해 보자.
- ‘insn per cycle’ 항목은 하나의 클럭 주기에 CPU가 실행하는 프로그램에서 기계 명령어를 몇 개 실행하는지 알려준다.
- 다중 스레드 프로그램의 ‘insn per cycle’은 0.15
- 단일 스레드 프로그램의 ‘insn per cycle’은 0.6으로 다중 스레드 프로그램의 네 배에 달한다.
- 다중 스레드 프로그램의 성능이 왜 좋지 않을까? 전역 변수 a가 C1 캐시와 C2 캐시에 모두 저장된다.
- 첫 번째 스레드가 a 변수에 연산을 실행하기 시작한다면 반드시 C2 캐시의 a 변수를 무효화(invalidation)해야 한다.
- C2는 캐시가 무효화되어 있기 때문에 어쩔 수 없이 메모리에서 직접 a 변수 값을 읽어야 한다.
- C2도 a 변수에 연산을 하므로 캐시의 일관성을 보장하기 위해 이번에는 C1 캐시의 a 변수를 무효화해야 한다.
- 이와 같이 C1 캐시와 C2 캐시는 끊임없이 서로 상대 캐시를 무효화하면서 튕겨낸다.
- 이것이 바로 캐시 튕김(cache line bouncing) 또는 캐시 핑퐁(cache ping-pong)이다.
- 이 예제는 여러 스레드 사이에 데이터 공유를 피할 수 있다면 가능한 한 피해야 한다는 것을 알려 준다.
두 번째 성능 방해자: 거짓 공유 문제
- 데이터 구조체 data를 통해 전역 변수 정의
struct data {
int a;
int b;
};
struct data global_data;
- 첫 번째 프로그램
void add_a() {
for (int i = 0; i < 500000000; i++) {
++global_data.a;
}
}
void add_b() {
for (int i = 0; i < 500000000; i++) {
++global_data.b;
}
}
void run() {
thread t1 = thread(add_a);
thread t2 = thread(add_b);
t1.join();
t2.join();
}
- 두 번째 프로그램
void run() {
for (int i = 0; i < 500000000; i++) {
++global_data.a;
}
for (int i = 0; i < 500000000; i++) {
++global_data.b;
}
}
- 두 스레드는 변수를 공유하지 않으므로 앞서 언급한 튕김 문제가 없을 것이라고 유추할 수 있다. 하지만 실제 결과는 어떨까? 첫 번째 다중 스레드 프로그램의 실행 시간은 3초였고, 두 번째 단일 스레드 프로그램의 실행 시간은 2초에 불과했다.
- 사실 두 스레드는 어떤 변수도 공유하지 않지만, 이 두 변수는 동일한 캐시 라인에 있을 가능성이 매우 높다. 캐시와 메모리는 캐시 라인 단위로 상호 작용한다는 것을 잊으면 안 된다. 이것은 거짓 공유(false sharing)라고 하는 문제이며, 이 역시 캐시 튕김 문제를 발생시킨다.
- 원인을 알면 개선도 매우 간단하다. 두 변수 사이에 사용되지 않는 데이터를 채우는 것이다.
struct data {
int a;
int arr[16]; // 캐시 라인 크기
int b;
};
Section 5.4 양치기 소년과 메모리 장벽
- 두 전역 변수 X와 Y가 있으며, 초기값은 모두 0이다. 또 스레드가 두 개 있어 동시에 다음 코드를 실행한다고 가정해 보자.
- 스레드 1
- X = 1;
- a = Y;
- 스레드 2
- Y = 1;
- b = X;
- 스레드 1
- a와 b의 마지막 값은 얼마일까? 다음과 같은 몇 가지 상황이 있다.
- 스레드 1이 먼저 실행되며, 이 때 a = 0, b = 1 이다.
- 스레드 2가 먼저 실행되며, 이 때 a = 1, b = 0 이다.
- 스레드 1과 스레드 2가 동시에 코드의 첫 줄을 실행하며, 이 때 a = 1, b = 1 이다.
- x86 플랫폼에서는 a와 b가 모두 0일 수도 있다.
명령어의 비순차적 실행: 컴파일러와 OoOE
- 원래 CPU는 프로그래머가 코드를 작성한 순서대로 기계 명령어를 실행하지 않는다.
- 그 이유는 모든 것이 성능 향상과 직결된다.
- 명령어의 비순차적 실행은 다음과 같이 두 단계를 거친다.
- 기계 명령어를 생성하는 단계: 컴파일 중에 명령어를 재정렬한다.
- 컴파일러는 프로그래머가 작성한 코드를 CPU가 실행할 수 있는 기계 명령어로 변환하는 역할을 한다. 이 과정에서 컴파일러는 ‘수작을 부릴’ 기회를 가진다.
- CPU가 명령어를 실행하는 단계: 실행 중에 명령어가 비순차적으로 실행된다.
- 순차적 명령어 처리는 매우 직관적이지만 필요한 피연산자(operand)가 아직 준비되지 않은 경우 CPU가 대기해야 하기 때문에 비효율적이다.
- 비순차적 명령어 처리(Out of Order Execution, OoOE)
- 기계 명령어(opcode)를 가져온다.
- 명령어를 대기열(reservation station)에 넣고 명령어에 필요한 피연산자를 읽는다.
- 명령어는 대기열에서 피연산자가 준비가 완료될 때까지 대기한다. 이때 이미 준비가 완료된 명령어가 먼저 실행 단계에 들어갈 수 있다.
- 기계 명령어를 실행하면 실행 결과를 대기열(재배치 버퍼, reorder buffer)에 넣는다.
- 이전 명령어의 실행 결과가 기록될 때까지 기다렸다가 현재 명령어의 실행 결과를 기록한다. 이는 명령어의 원래 실행 순서에 따라 유효한 결과를 얻기 위한 것이다.
- 기계 명령어를 생성하는 단계: 컴파일 중에 명령어를 재정렬한다.
- CPU와 메모리 사이의 속도 차이가 엄청나기 때문에 CPU가 기계 명령어를 엄격한 순서대로 실행하면 명령어가 의존하는 피연산자를 기다리는 동안 파이프라인 내부에 ‘빈 공간’인 슬롯(slot)이 생긴다. 이때 이미 준비 완료된 다른 명령어로 이 ‘빈 공간’을 메꿀 수 있다면, 명령어의 실행 속도를 끌어올릴 수 있다.
- 하지만 이는 전후 관계의 두 명령어가 서로 어떤 의존 관계도 없을 때에 한한다.
- 모든 CPU가 비순차적 명령어 실행 기능을 가지고 있지는 않다.
캐시도 고려해야 한다
- L1 캐시와 L2 캐시는 각각의 CPU 코어마다 별도로 존재하며, L3 캐시와 메모리는 모든 코어가 공유한다.
- 캐시가 있는 모든 시스템은 반드시 동일한 문제에 맞닥뜨리게 되는데, 그것은 바로 어떻게 캐시를 갱신하고 캐시의 일관성을 유지시키느냐 하는 것이다.
- 이 과정을 최적화하기 위해 일부 시스템은 저장 버퍼(store buffer) 등 대기열을 추가한다. 즉, CPU는 캐시가 갱신되기를 기다리지 않고 다음 명령어를 계속 실행할 수 있다.
- CPU가 관련 없는 명령어를 미리 실행하는 형태의 ‘부정 출발’처럼 보이는 동작은 명백하게 더 나은 성능을 얻을 수 있기 때문이다.
- 흥미로운 점은 어떤 유형의 명령어가 비순차적으로 실행되더라도 단일 스레드 내에서는 비순차적 실행을 볼 수 없으며, 다른 스레드 역시 해당 공유 데이터에 접근해야만 이런 비순차적 실행을 볼 수 있다. 다시 말해 단일 스레드 환경에서 프로그래밍할 경우, 근본적으로 이 문제를 신경 쓸 필요가 없다.
- 잠금 없는 프로그래밍(lock-free programming)을 하고 있다면 이 문제를 신경 써야만 한다. 잠금 없는 프로그래밍은 잠금을 통한 보호를 사용하지 않는 상태에서 다중 스레드의 공유 리소스를 처리하는 것이다.
- 일반적으로 다중 스레드에서 공유 리소스를 사용하는 작업은 잠금을 통한 보호가 필요하다고 이야기한다. 하지만 실제로는 잠금이 반드시 필요한 것은 아니며, 잠금이 없이도 공유 리소스에 접근할 수 있다. 그 원리는 비교와 교환(compare-and-swap), 즉 CAS 알고리즘과 같은 원자성 작업을 사용하는 것이다. 이런 명령어는 실행되거나 되지 않는 두 가지 상태만 존재하며, 중간 상태는 존재하지 않는다.
- 그렇다면 명령어의 비순차적 실행 문제는 어떻게 해결해야 할까? 그 답은 메모리 장벽(memory barrier)이며, 이는 사실 구체적인 기계 명령어이다.
- 명령어는 비순차적으로 실행될 수 있지만, 메모리 장벽 기계 명령어를 통해 해당 스레드의 CPU 코어에 다음 명령을 내릴 수 있다. ‘여기에서는 어떤 수작도 부릴 생각하지 말고 성실하게 순서에 따라 실행해서 다른 코어가 이 코어를 보았을 때 비순차적 명령어 실행을 하는 것으로 보이면 안된다.’
- 메모리를 이야기할 때는 읽기와 쓰기, 즉 Load와 Store 단 두 가지 유형의 작업만 존재한다. 따라서 이를 조합하면 LoadLoad, StoreStore, LoadStore, StoreLoad 네 가지 메모리 장벽 유형이 존재한다. 이때 모든 이름은 비순차적 실행을 금지한다는 의미를 가진다.
네 가지 메모리 장벽 유형
- LoadLoad
- CPU가 Load 명령어를 실행할 때 다음에 오는 Load 명령어가 ‘부정 출발’ 형태로 먼저 실행되는 것을 방지한다.
- 상대적으로 간단한 메모리 읽기 명령어조차도 일부 CPU에서는 더 높은 성능을 위해 ‘부정 출발’ 형태로 실행된다는 것이다.
- StoreStore
- CPU가 Store 명령어를 실행할 때 다음에 오는 Store 명령어가 ‘부정 출발’ 형태로 먼저 실행되는 것을 방지한다.
- 시스템에 캐시 등이 추가되면 쓰기와 같은 작업은 비동기적으로 처리될 수 있다. 기본 설정 상황에서는 변수 값이 실제로 언제 메모리에 갱신되는지 어떤 가정도 할 수 없지만, StoreStore 메모리 장벽을 추가하면 다른 코어에서 보기에 변수의 갱신 순서와 코드 순서가 일치하게 된다.
- LoadStore
- 쓰기 작업은 상대적으로 무거운데, 어떻게 Load 명령어보다 먼저 실행될 수 있을까? Load 명령어가 캐시에 적중하지 못하면 일부 CPU에서는 다음에 오는 Store 명령어가 먼저 실행될 수 있다.
- StoreLoad
- 쓰기 명령어를 실행할 때 CPU가 ‘부정 출발’ 형식으로 읽기 명령어를 먼저 실행하는 것을 방지한다. 이 메모리 장벽은 네 가지 중에서 가장 무겁다.
- 본질적으로 StoreLoad 메모리 장벽은 동기 작업이다.
획득-해제 의미론
- 다중 스레드 프로그래밍을 사용할 때 프로그래머는 주로 다음과 같은 두 가지 문제에 직면합니다.
- 공유 데이터에 대한 상호 배타적인 접근
- 스레드 간 동기화 문제
- 획득-해제 의미론(acquire-release semantics)은 두 번째 문제를 해결하는데 사용되지만, 공식적은 획득-해제 의미론 정의는 존재하지 않는다.
- 획득(acquire) 의미론은 메모리 읽기 작업에 대한 것이다. Load 뒤에 있는 모든 메모리 작업은 이 Load 작업 이전에는 실행 불가능하다.
- 해제(release) 의미론은 메모리 쓰기 작업에 대한 것이다. Store 앞에 있는 모든 메모리 작업은 이 Store 작업 이후에는 실행 불가능하다.
- 획득-해제 의미론을 진정으로 이해했다면 사실상 LoadLoad와 LoadStore 조합은 획득 의미론이며, StoreStore와 LoadStore 조합은 해제 의미론임을 알 수 있다.
- 획득-해제 의미론을 얻기 위해 StoreLoad처럼 매우 무거운 메모리 장벽이 필요하지 않으며, 나머지 세 종류의 메모리 장벽만 사용하면 된다는 것이다.
C++에서 제공하는 인터페이스
- 특정 유형의 CPU만 대상으로 코드를 작성하면 다른 플랫폼에 이식할 방법이 없다.
- 따라서 이식성 높은 잠금 없는 프로그래밍을 하고 싶다면 언어 수준에서 제공하는 획득-해제 의미론을 사용해야만 한다.
다른 CPU, 다른 천성
- 아키텍처별 지원하는 명령어 재정렬이 모두 다르다.
- Alpha, ARMv7, POWER 등 CPU에서는 거의 모든 유형의 명령어 재정렬이 있는데, 이런 플랫폼을 약한 메모리 모델(weak memory model)이라고 한다.
- x86 플랫폼은 StoreLoad 재졍렬 하나만 있다. x86에 자체적인 획득-해제 의미론이 있다는 의미이다. 이런 플랫폼을 강한 메모리 모델(strong memory model)이라고 한다.
누가 명령어 재정렬에 관심을 가져야 하는가: 잠금 없는 프로그래밍
- 잠금 없는 프로그래밍을 해야 할 때만 명령어 재정렬에 신경 쓰면 된다. 이 문제는 공유 변수가 잠금 보호 없이 여러 스레드에서 사용될 때 발생하며 다른 경우에는 여기에 관심을 가질 필요가 없다.
- 잠금 없는 프로그래밍은 운영 체제가 어떻게 순서 스케줄링을 하든 스레드 하나는 무조건 앞으로 나아갈 수 있는 스레드를 확보할 수 있다. 운영 체제가 이런 특징을 가지고 있으면 이를 잠금 없음(lock-free)이라고 한다.
- 잠금을 사용하여 프로그래밍 할 때 잠금이 명령어 재정렬 문제를 자동으로 처리한다는 것이다.
- 잠금 없는 프로그래밍이 잠금을 사용하는 프로그래밍보다 더 효율적이라고 생각할 수도 있지만, 사실 그렇지 않다.
잠금 프로그래밍과 잠금 없는 프로그래밍
- 시스템에서 일반적으로 사용되는 잠금(lock)
- 다중 스레드 프로그래밍에서 일반적으로 사용되는 상호 배제(mutual exclution, 줄여서 뮤텍스)는 공유 리소스를 보호하는 데 사용된다. 동시에 최대 스레드 하나만 상호 배제를 보유할 수 있으며, 해당 잠금이 사용되면 해당 잠금을 요청하는 다른 스레드는 운영 체제에 의해 대기 상태로 진입한다. 이는 잠금을 사용한 스레드가 잠금을 해제할 때까지 계속된다.
- 또 다른 형태의 잠금이 있는데, 스핀 잠금(spinlock)이다. 잠금이 사용된 후 잠금을 요청하는 스레드는 계속 잠금이 해제되었는지 여부를 반복적으로 확인한다. 이때 잠금을 요청하는 다른 스레드는 운영 체제에 의해 대기 상태로 진입하지 않는다.
- 잠금 없는 프로그래밍은 공유 리소스가 사용되는 것을 감지(일반적으로 원자성 작업으로 감지)하면 일단 다른 필요한 작업으로 넘어가는데, 이것이 잠금 프로그래밍과 잠금 없는 프로그래밍의 가장 큰 차이다.
- 잠금 없는 프로그래밍은 시스템 스레드가 항상 대기없이 어떤 일을 하도록 하는 것에 가치를 두고 있다. 이것은 실시간 요구 사항이 높은 시스템에는 매우 중요하지만, 잠금 없는 프로그래밍은 매우 많고 복잡한 리소스 경쟁 문제를 처리해야 하며 잠금 프로그래밍에 비해 코드 구현이 훨씬 복잡하다.
- 따라서 프로그래머는 대부분의 경우 간단한 잠금 프로그래밍을 일단 선택하지만, 잠금으로 보호해야 하는 임계 영역이 너무 커서는 안 되므로 주의해야 한다. 또 경재이 치열할 때는 상호 배제(mutex)로 상황 정보 전환 부담 역시 증가할 수 있다.
명령어 재정렬에 대한 논쟁
- 하드웨어 엔지니어 입장에서 명령어 재정렬은 확실히 CPU 성능 향상에 도움이 된다. 하지만 명령어 재졍렬 문제는 매우 어려우며, 리누스 토발즈는 많은 종류의 버그를 일으키는 주요 원인이라고 지적하기도 했다.
- 이 절에서 다룬 내용이 약간 복잡하게 느껴졌을 수도 있다. 따라서 잠금 없는 프로그래밍을 할 필요가 없다면 이 절에서 다룬 내용 따위는 잊어버려도 좋다. CPU는 프로그래머가 코드를 작성한 순서대로 기계 명령어를 실행한다고 간단하게 정리하고 넘어가면 그만이다.
- 하지만 무언가 남기고 싶다면 다음 문장을 기억하라.
- 성능을 위해 CPU는 반드시 프로그래머가 코드를 작성한 순서대로 엄격하게 기계 명령어를 실행할 필요가 없다.
- 프로그램이 단일 스레드인 경우 비순차적 실행을 볼 수 없으므로, 명령어 재정렬에 신경 쓸 필요가 없다.
- 메모리 장벽의 목적은 특정 코어가 명령어를 실행하는 순서와 다른 코어에서 보이는 순서가 코드 순서와 일치하도록 만드는 것이다.
- 멀티 스레드 잠금 없는 프로그래밍을 사용할 필요가 없다면 명령어 재정렬을 걱정할 필요가 없다.
Section 5.5 요약
이론적으로 캐시는 불필요한 것이다. 그러나 CPU와 메모리 사이의 속도 차이가 엄청나게 크고, 캐시 계층의 추가가 컴퓨터의 전반적인 성능을 향상시키는 데 중요한 역할을 한다는 것을 알았다. 오늘날 CPU 칩 내부의 상당 부분이 캐시에 할당되어 있으며, 동시에 다중 코어, 다중 스레드에 캐시까지 추가되면서 소트프웨어 설계에 새로운 도전 과제가 부여됐다.
대부분은 캐시 존재를 신경 쓸 필요가 없지만, 프로그램 성능이 극도로 요구되는 상황에서는 캐시 친화적인 프로그램 작성도 무시할 수 없다. 여기에서 중요한 점은 (1) 캐시 용량은 제한되어 있으므로 프로그램에 필요한 데이터에 더 ‘집중’하는 것이 좋다. (2) 여러 스레드 사이에 캐시 일관성을 유지할 필요가 있다면 다중 스레드 프로그래밍을 할 때 캐시 튕김 문제를 경계해야 한다.
스레드 사이에 데이터를 공유하지 않을 수 있다면 가능한 한 데이터를 공유하지 않는다. 데이터를 공유하지 않는다는 전제하에 여러 스레드가 빈번하게 접근하는 데이터가 같은 캐시 라인에 들어가지 않는지 주의해야 한다. 이것으로 거짓 공유 문제가 발생할 수 있다.
다시 강조하지만, 분석 도구를 이용하여 캐시 적중률이 시스템 성능의 병목이 된다고 판단될 때만 이에 집중하여 최적화를 수행해야 한다.
Chapter 6. 입출력이 없는 컴퓨터가 있을까?
Section 6.1 CPU는 어떻게 임출력 작업을 처리할까?
- CPU 내부에 레지스터가 있는 것과 마찬가지로, 장치에도 자체적인 레지스터인 장치 레지스터(device register)가 있다.
- CPU의 레지스터는 메모리에서 읽은 데이터를 임시로 저장하거나 CPU에서 계산한 중간 결과를 저장하는 데 사용된다. 반면에 장치 레지스터는 주로 장치에 관련된 일부 정보를 저장하며, 다음 두 가지 레지스터가 있다.
- 데이터를 저장하는 레지스터: 예를 들어 사용자가 키보드의 키를 누르면 그 정보는 이런 레지스터에 저장된다.
- 제어 정보와 상태 정보를 저장하는 레지스터: 이런 레지스터를 읽고 쓰는 작업을 이용하여 장치를 제어하거나 장치 상태를 볼 수 있다.
- 프로그래머 관점에서 장치는 저수준 계층의 레지스터를 한데 묶은 것에 불과하며, 장치에서 생성된 데이터를 얻거나 장치를 제어하는 작업은 모두 이런 레지스터를 읽고 쓰는 것으로 한다.
전문적으로 처리하기: 입출력 기계 명령어
- 특정한 기계 명령어를 입출력 명령어(input and output instruction)라고 하는데, x86의 IN과 OUT 기계 명령어가 이에 해당한다.
- 장치마다 고유한 주소가 부여되며, 입출력 명령어에 장치 주소를 저장한다. 이것으로 CPU가 입출력 명령어를 실행하면 하드웨어 회로가 어떤 장치 레지스터를 읽고 써야 하는지 알 수 있다.
메모리 사상 입출력
- 메모리 사상 입출력(memory mapping input and output): 주소 공간의 일부분을 장치에 할당하여, 메모리를 읽고 쓰는 것처럼 장치를 제어하는 방법
- 컴퓨터 저수준 계층에는 본질적으로 두 가지 입출력 구현 방법이 있다.
- 특정 입출력 기계 명령어를 사용하는 것
- 메모리의 읽기와 쓰기 명령어를 함께 사용하지만 주소 공간의 일부분을 장치에 할당하는 것
CPU가 키보드를 읽고 쓰는 것의 본질
- 메모리 사상 입출력 방식을 채용하고 키보드의 레지스터가 주소 공간의 Oxfe00에 사상되어 있다고 가정하면, CPU가 키보드를 읽는 기계 명령어는 다음과 같이 작성할 수 있다.
Load R1 0xFE00- 주소 Oxfe00 값을 CPU 레지스터에 적재하는 명령
- CPU 동작 규칙과 외부 장치는 매우 다르며, 대다수 장치는 사람이 조작하는 것이기 때문에 사람이 언제 마우스를 움직이고 키보드를 누를지 알 수 없다.
- 따라서 CPU는 특정한 방법을 사용하여 장치의 작업 상태를 얻어야 한다. 이것이 바로 장치 상태 레지스터의 역할이다.
폴링: 계속 검사하기
- 장치 상태 레지스터를 지속적으로 읽는 작업으로 키보드를 누르면 바로 해당 키보드의 문자를 읽을 수 있으며, 누르지 않을 때는 계속 검사를 반복한다는 흐름을 떠올려 볼 수 있다.
- 이런 입출력 구현 방법을 폴링(polling)이라고 한다.
- 폴링 입출력 구현은 사용자가 키를 누르지 않으면 CPU는 항상 불필요하게 순환하며 대기하게 된다.
- 본질적으로 폴링은 일종의 동기식 설계 방식이다.
배달 음식 주문과 중단 처리
- 컴퓨터 시스템의 매우 기초적인 인터럽트 처리 구조
- CPU가 특정 프로세스의 기계 명령어를 실행하고 있을 때 새로운 이벤트가 발생하는 경우
- 예를 들어 네트워크 카드에 새로운 데이터가 들어오면 외부 장치가 인터럽트 신호를 보내고
- CPU는 실행 중인 현재 작업의 우선순위가 인터럽트 요청보다 높은지 판단한다.
- 인터럽트가 더 높다면 현재 작업 실행을 일시 중지하고 인터럽터를 처리하며,
- 인터럽트 처리를 끝낸 후에 다시 현재 작업으로 돌아온다.
- 프로그램은 계속 끊임없이 실행되는 것이 아니라 언제든지 장치에 의해 실행이 중단될 수 있다. 하지만 이 과정은 프로그래머에거 드러나지 않으며, 인터럽트 처리와 반환 작동 방식은 운영 체제와 협조하여 프로그래머에게 프로그램 중단 없이 실행되고 있는 것처럼 느끼게 만든다.
인터럽트 구동식 입출력
- 인터럽트 방법에서도 CPU는 실제로 약간의 시간을 낭비하는데, 이 부분의 시간은 주로 프로그램의 실행 상태를 저장하고 복원하는 데 사용된다.
- 입출력을 비동기로 처리하는 이 방법이 바로 인터럽트 구동식 입출력(interrupt driven input and output)이며, 이 방법은 1954년에 DYSEAC 시스템에서 처음 사용되었다.
- 동기 기반의 폴링에서 비동기 인터럽트 처리로 바뀌었지만, 아직 해결되지 않은 두 가지 문제가 남아있다.
- CPU는 인터럽트 신호가 오는 것을 어떻게 감지할까?
- 중단된 프로그램의 실행 상태를 저장하고 복원하는 방법은 무엇일까?
CPU는 어떻게 인터럽트 신호를 감지할까?
- CPU가 기계 명령어를 실행하는 과정은 명령어 인출(instruction fetch), 명령어 해독(instruction decode), 실행(execute), 다시 쓰기(writeback) 같은 몇 가지 전형적인 단계로 나눌 수 있다. 이제 여기에 CPU가 하드웨어의 인터럽트 신호를 감지하는 단계가 추가되어야 한다.
- 인터럽트 신호가 감지되는 것은 어떤 하나의 장치에서 CPU 처리가 필요한 이벤트가 나타났음을 의미하는데 이 이벤트를 처리할지 여부를 반드시 결정해야 한다. 이때 우선순위 문제가 뒤따라온다.
인터럽트 처리와 함수 호출의 차이
- 인터럽트 처리는 사용자 상태의 일반 함수 호출과 비교했을 때 점프와 반환을 포함하고 있다는 점에서 매우 유사하다.
- 인터럽트 처리 함수로 점프할 때 저장해야 하는 정보는 훨씬 더 많다.
- 이런 차이가 발생하는 이유는 사용자 상태든 커널 상태든 간에 함수 호출은 단일 스레드 내부에서만 발생하기 때문이고, 동일한 실행 흐름 내에 존재하기 때문이다. 반면에 인터럽트 처리 점프는 서로 다른 두 실행 흐름을 포함하므로 함수 호출에 비해 인터럽트 점프는 저장해야 할 정보가 훨씬 많다.
중단된 프로그램의 실행 상태 저장과 복원
- 프로그램 A가 실행 중일 때 인터럽트가 발생하면 프로그램 A 실행은 중단되고, CPU는 인터럽트 처리 프로그램(interrupt handler) B로 점프한다. CPU가 인터럽트 처리 프로그램 B를 실행할 때 다시 인터럽트가 발생하면 인터럽트 처리 프로그램 B의 실행은 중단되고, CPU는 인터럽트 처리 프로그램 C로 점프한다.
- 인터럽트 처리 프로그램 C의 실행이 완료되면 프로그램 B, 프로그램 A 순서대로 반환된다.
- 상태가 먼저 저장될수록 상태 복원은 더 나중에 된다. 이는 스택을 사용하여 구현할 수 잇으므로 프로그램 실행 상태를 저장하는 전용 스택을 만들 수 있다. 물론 이 스택은 반드시 커널에 있어야 한다. 다시 말해 일반적인 프로그램은 이 스택을 보거나 수정할 수 없다. 따라서 CPU가 커널 상태에 진입했을 때만 이 스택을 사용할 수 있다.
Section 6.2 디스크가 입출력을 처리할 때 CPU가 하는 일은 무엇일까?
최신 컴퓨터 시스템의 경우, 사실 디스크가 입출력을 처리할 때 CPU 개입이 필요하지 않다.
장치 제어기(device controller)
- 디스크와 같은 입출력 장치는 대체로 두 부분으로 나눌 수 있다.
- 기계 부분
- 헤드(head), 실린더(cylinder) 등
- 읽어야 하는 데이터가 헤드가 위치한 트랙(track)에 없을 가능성이 있다. 이때 헤드가 특정 트랙으로 이동해야 하는데 이 과정을 탐색(seek)이라고 하며, 이 작업은 디스크 입출력 중에서 매우 시간을 많이 소모하는 작업에 해당한다.
- 전자 부분
- 전자 부품으로 구성되어 있으며, 이를 장치 제어기(device controller)라고 한다.
- 자체적인 프로세서와 펌웨어(firmware)를 갖추고 있다. 따라서 CPU가 직접 도와주지 않는 상황에서도 복잡한 작업을 할 수 있으며, 이와 동시에 자신만의 버퍼나 레지스터를 갖추고 있어 장치에서 읽은 데이터나 저장할 데이터를 저장할 수 있다.
- 기계 부분
- 장치 제어기와 장치 드라이버(device driver)를 혼동하지 말자. 장치 드라이버는 운영 체제에 속한 코드인데 반해, 장치 제어기는 장치 드라이버에서 명령을 받아 외부 장치를 제어하는 하드웨어에 해당한다.
- 장치 제어기는 운영 체제에 해당하는 장치 드라이버와 외부 장치를 연결하는 다리에 해당하며, 장치 제어기가 점점 더 복잡해지는 목적 중 하나가 바로 CPU를 해방시키는 것이다.
CPU가 직접 데이터를 복사해야 할까?
- 데이터는 항상 장치와 메모리 사이에 전송되어야 하므로, 누군가는 이 작업을 수행해야만 한다.
- CPU 개입 없이 직접 장치와 메모리 사이에 데이터를 전송할 수 있는 작동 방식을 설계했으며, 이 작동 방식은 직접 메모리 접근(direct memory access, DMA)이라고 한다.
- 지금까지 알아본 입출력 장치와 메모리 사이에 데이터를 전송하는 방식
- 폴링
- 인터럽트
- 직접 메모리 접근
직접 메모리 접근
- 직접 메모리 접근의 간단한 동작 과정: CPU가 직접 데이터를 복사할 필요는 없다. 그러나 CPU는 반드시 어떻게 데이터를 복사할지 알려 주는 명령어를 DMA에 전달해야 한다.
- DMA는 자신의 작업 목표를 명확히 하고 버스 중재(bus arbitration), 다시 말해 버스의 사용 권한을 요청한 후 이어서 장치를 작동시킨다.
전 과정 정리
- CPU로 실행되는 스레드 1이 시스템 호출로 입출력 요청을 시작하면, 운영 체제는 스레드 1의 실행을 일시 중지하고 CPU를 스레드 2에 할당한다. 그리고 스레드 2가 실행되기 시작한다.
- 이때 디스크가 동작하여 데이터 준비가 완료되면 DMA 작동 방식이 직접 장치와 메모리 사이에서 데이터를 전송한다.
- 이 데이터 전송이 완료되면 인터럽트 작동 방식을 이용하여 CPU에 알리고,
- CPU는 스레드 2의 실행을 일시 중지하고 인터럽트를 처리한다.
- 이때 운영 체제는 스레드 1이 요청한 입출력 작업이 처리된 것을 확인했기 때문에 CPU를 다시 스레드 1에 할당하기로 결정하며, 결국 스레드 1이 마지막으로 중단되었던 위치부터 계속 실행된다.
- 여기에서 핵심은 디스크가 입출력 요청을 처리할 때 CPU가 그 자리에서 기다리지 않고 운영 체제의 스케줄링에 따라 스레드 2를 실행한다는 것이다.
프로그래머에게 시사하는 것
- 동기와 비동기 관점에서 볼 때, 디스크의 입출력 요청 처리는 CPU가 기계 명령어를 실행하는 것에 비추어 보면 사실상 비동기이기에 디스크가 입출력 요청을 처리하는 동안 CPU는 자신의 업무를 처리하느라 바쁘다.
- 이와 같이 소프트웨어든 하드웨어든 간에 높은 효율성을 이끌어 내는 비결 중 하나는 지금까지 여러 번 확인한 것처럼 비동기이다. 다른 말로는 ‘무의존성’ 또는 ‘분리(decoupling)’가 이에 해당한다.
Section 6.3 파일을 읽을 때 프로그램에는 어떤 일이 발생할까?
메모리 관점에서 입출력
- 메모리 관점에서 입출려은 단순한 메모리 복사(copy)일 뿐, 그 이상도 이하도 아니다.
- 메모리와 외부 장치 사이에서 데이터를 주고받는 것이 입출력(input/output)이라 하며, 흔히 약어로 I/O라고 표현한다.
read 함수는 어떻게 파일을 읽는 것일까?
- 단일 코어 CPU 시스템에 프로세스 A와 프로세스 B 두 개가 있을 때, 프로세스 A가 현재 실행 중이라고 가정해 보자.
- 프로세스 A에는 파일을 읽는 코드가 있다. 어떤 프로그래밍 언어를 사용하든 일반적으로 먼저 데이터를 저장하는 버퍼를 정의한 후 다음과 같이 read 계열의 함수를 호출한다.
char buffer[LEN];
read(buffer);
- 해당 함수는 저수준 계층에서 시스템 호출을 이용하여 운영 체제에 파일 읽기 요청을 보낸다. 이 요청은 커널에서 디스크가 이해할 수 있는 명령어로 변환되어 디스크로 전송된다.
- 외부 장치가 입출력 작업을 실행하는 것은 매우 느리기 때문에 입출력 작업이 끝나기 전까지 프로세스는 블로킹(blocking) 된다.
- 운영 체제는 현재 프로세스 A의 실행을 일시 중지하고 입출력 블로킹 대기열에 넣는다. 이때 운영 체제는 이미 디스크에 입출력 요청을 보낸 상태이다.
- 디스크는 DMA 작동 방식을 사용하여 데이터를 특정 메모리 영역으로 복사하는 작업을 시작한다. 이 메모리 영역이 바로 read 함수를 호출할 때 지정했던 buffer이다.
- 디스크는 바쁜 채로 놔두고
- 운영 체제에는 준비 완료 대기열도 존재하는데, 준비 완료 대기열은 대기열 안의 프로세스가 다시 실행되는 조건이 준비되었음을 의미한다. 프로세스 B가 준비 완료 대기열에 들어간다.
- 운영 체제는 프로세스 B를 준비 완료 대기열에서 꺼내 CPU를 이 프로세스에 할당하며, 프로세스 B가 실행되기 시작한다.
- 운영 체제의 스케줄링에 따라 CPU와 디스크가 모두 충분히 활용된다.
- 이후 디스크가 데이터를 모두 프로세스 A의 메모리에 복사하는 작업이 완료되면, 디스크는 CPU에 인터럽트 신호를 보낸다.
- CPU는 인터럽트 신호를 받은 후 처리가 중단되었던 함수로 점프하며, 프로세스 A가 계속 실행될 수 있는 자격을 다시 얻었음을 알 수 있게 된다.
- 이때 운영 체제는 프로세스 A를 입출력 블로킹 대기열에서 꺼내 다시 준비 완료 대기열에 넣는다.
- 운영 체제는 CPU를 프로세스 A에 할당할지 아니면 B에 할당할지 결정해야 한다. 여기에서는 프로세스 B에 할당된 CPU 시간이 아직 남아 있기 때문에 운영 체제가 프로세스 B를 계속 실행하는 하는 것으로 결정했다고 가정한다.
- 이후 프로세스 B는 계속 실행되고 프로세스 A는 계속 대기한다.
- 프로세스 B가 일정 시간 실행된 후 시스템의 타이머가 타이머 인터럽트 신호를 보내면 CPU는 인터럽트 처리 함수로 점프한다. 이때 운영 체제는 프로세스 B의 실행 시간이 충분히 길었다고 생각하고, 준비 완료 대기열에 넣음과 동시에 프로세스 A를 준비 완료 대기열에서 꺼내 CPU에 할당한다. 이렇게 프로세스 A가 게속 실행된다.
- 이때 운영 체제가 프로세스 B를 준비 완료 대기열에 넣는 것은 할당된 시간을 모두 사용했기 때문이지, 블로킹 입출력을 요청했기 때문이 아니다.
- 이제 프로세스 A가 계속 실행되며, 버퍼는 이미 프로그래머에게 필요한 데이터로 채워져 있다. 이렇게 프로세스 A는 마치 중단된 적이 없는 것처럼 게속 실행되며, 심지어 프로세스는 자신이 일시중지되었다는 사질조차 알지 못한다.
Section 6.4 높은 동시성의 비결: 입출력 다중화
- 사실상 모든 입출력 장치는 파일이라는 개념으로 추상화된다.
- 모든 입출력 작업은 파일 읽기와 쓰기로 구현할 수 있다. 프로그래머는 이 추상화를 이용하여 일련의 인터페이스로 모든 외부 장치를 사용할 수 있다.
- open 함수를 사용하여 파일을 열고, read 함수와 write 함수를 사용하여 파일을 읽고 쓰며, seek 함수를 사용하여 파일을 읽고 쓰는 위치(file pointer)를 변경할 수 있고, close를 사용하여 파일을 닫을 수 있다.
파일 서술자
- 유닉스/리눅스 세계에서 파일을 사용하려면, 번호를 하나 빌려 올 필요가 있다. 이 번호는 파일 서술자(file descriptor)라는 이름을 가지고 있으며, 이 번호의 역할은 대기 번호와 동일하다. 파일 서술자는 그냥 숫자에 불과하다.
- 파일을 열 때 커널은 파일 서술자르 반환하며, 파일 작업을 실행할 때 해당 파일 서술자를 커널에 전달해 주어야 한다. 커널은 이 숫자를 얻은 후 해당 숫자에 대응하는 파일에 관련된 모든 정보를 찾아 파일 작업을 완료할 수 있다.
- 파일 서술자를 사용하면 프로세스는 파일에 대해 아무것도 몰라도 된다. 예를 들어 파일이 디스크에 저장되어 있는지, 디스크의 어느 위치에 저장되어 있는지, 지금 읽고 있는 위치는 어디인지 등 정보를 운영 체제가 대신 처리하므로 프로세스는 이것을 신경 쓸 필요가 없다. 따라서 프로그래머는 파일 서술자만 프로그래밍하면 된다.
char buffer[LEN];
int fd = open(file_name); // 파일 서술자 얻기
read(fd, buffer);
다중 입출력을 어떻게 효율적으로 처리하는 것일까?
- 높은 동시성이라는 주제에 도달했다. 높은 동시성이란 서버가 동시에 많은 사용자 요청을 처리할 수 있음을 의미한다. 최근의 네트워크 통신은 대부분 소켓 프로그래밍을 사용하므로 이 역시 파일 서술자와 떼어 놓고 이야기할 수 없다.
- 웹 서버에서 3방향 주고받기(3 way handshake)에 성공하면 accept 함수를 호출하여 연결을 얻을 수 있고, 추가로 파일 서술자도 얻을 수 있다. 파일 서술자를 얻고 나면 이것으로 사용자와 통신을 진행 할 수 있다.
- 서버가 단 하나의 사용자와 통신할 때는 없으며 동시에 사용자 수천수만 명과 통신하는 것이 일반적이다.
- 하나씩 처리하는 경우
- 첫 번째 사용자가 어떤 데이터도 보내지 않으면 해당 코드를 사용하는 스레드 전체가 일시 중지된다. 두 번째 사용자가 요청 데이터를 보냈더라도 처리할 방법이 없다.
- 이 방법은 사용자 요청 수만 개를 처리해야 하는 서버에 있어서는 안 되는 일이다.
- 다중 스레드 사용하는 경우
- 스레드 수가 너무 많아질 수 있고 스레드의 스케줄링과 전환에 너무 많은 부담이 가해지므로 높은 동시성을 발휘해야 하는 상황에 최적의 방법이 아니다.
- 하나씩 처리하는 경우
- 파일 서술자 하나에 대응하는 입출력 장치가 읽을 수 있는 상태인지 쓸 수 있는 상태인지 미리 알 수 없다. 외부 장치를 읽을 수 없거나 쓸 수 없는 상태에서 입출력 요청을 보내면 스레드가 블로킹되어 일시 중지될 뿐이다.
상대방이 아닌 내가 전화하게 만들기
- read 함수를 사용하여 해당 파일 서술자에 대응하는 파일을 읽을 수 있는지 여부를 주동적으로 커널에 묻는 방법은 항상 ‘첫 번째 파일 서술자를 읽고 쓸 수 있습니까?, ‘두 번째 파일 서술자를 읽고 쓸 수 있습니까?’처럼 매번 질문하는 것이다.
- 따라서 이보다 더 나은 방법은 관심 대상인 파일 서술자를 커널에 알려주고, ‘여기 파일 서술자가 10,000개 있으니 대신 감시하다가 읽고 쓸 수 있는 파일 서술자가 있을 때 알려 주면 처리하렜습니다.’라고 이야기하는 것이다.
- 이것으로 응용 프로그램은 주동적이고 바쁜 상태에서 수동적이고 여유 있는 상태로 변한다.
- 프로그래머가 동시에 많은 수의 파일 서술자를 다룰 수 있는 방법인 입출력 다중화(input/output multiplexing) 기술이다.
입출력 다중화
- 입출력 다중화는 다음과 같은 과정을 의미한다.
- 파일 서술자를 획득한다. 이때 서술자 종류는 네트워크 관련이든 파일 관련이든 어떤 파일 서술자든 간에 상관없다.
- 특정 함수를 호출하여 커널에 다음과 같이 알린다. ‘이 함수를 먼저 반환하는 대신, 이 파일 서술자를 감시하다가 읽거나 쓸 수 있는 파일 서술자가 나타날 때 반환해 주세요.
- 해당 함수가 반환되면 읽고 쓸 수 있는 조건이 준비된 파일 서술자를 획득할 수 있으며, 이를 통해 상응하는 처리를 할 수 있다.
- 이 기술로 여러 입출력을 한꺼번에 처리할 수 있다. 리눅스 세계에서 입출력 다중화 기술을 사용하는 방법에는 select, poll, epoll 세 가지가 있다.
삼총사: select, poll, epoll
- 본질적으로 select, poll, epoll은 모두 동기 입출력 다중화 기술이다. 이런 함수가 호출될 때 감시해야 하는 파일 서술자에서 읽기 가능 또는 쓰기 가능 같은 관심 대상 이벤트가 나타나지 않으면 호출된 스레드가 블로킹되어 일시 중지되고, 파일 서술자가 해당 이벤트를 생성할 때까지 함수는 반환되지 않는다.
- select: 입출력 다중화 기술에서 감시할 수 있는 파일 서술자 묶음에 제한이 있으며, 일반적으로 1024개를 넘을 수 없다. 파일 서술자 중 하나라도 읽기 가능 또는 쓰기 가능 이벤트가 나타나면 해당 프로세스 또는 스레드가 깨어난다. 문제는 깨어났을 때 프로그래머는 어떤 파일 서술자가 읽고 쓸 수 있는지 알 수 없어, 알려면 처음부터 끝까지 다시 확인해야 한다. 이것이 select가 대량의 파일 서술자를 감시할 때 효율이 매우 떨어지는 근본적인 원인이다.
- poll: select과 유사하며, 감시 가능한 파일 서술자 수가 1024개라는 제한을 넘지 못한다는 문제를 해결하는 것뿐이다.
- epoll: 커널에 필요한 데이터 구조를 생성해 문제를 해결한다. 이 데이터 구조에서 중요한 것은 완료된 파일 서술자 목록이다. 모든 파일 서술자를 처음부터 끝까지 다시 확인할 필요 없이 완료된 파일 서술자를 직접 획득할 수 있는데, 이는 매우 효율적이다.
- 실제로 리눅스에서 epoll은 기본적으로 높은 동시성의 대명사이다. 수많은 네트워크 관련 프레임워크와 라이브러리의 저수준 계층에서 epoll 그림자를 확인할 수 있다.
Section 6.5 mmap: 메모리 읽기와 쓰기 방식으로 파일 처리하기
- 프로그래머에게 메모리를 읽고 쓰는 것은 매우 자연스러운 일이지만, 파일을 읽고 쓰는 것은 그리 편한 일이 아니다.
// 메모리를 읽고 쓰기
int a[100];
a[10] = 2;
// 파일 읽기
char buf[1024];
int fd = open("/file/path/abc.txt");
read(fd, buf, 1024);
- 파일을 사용하는 것이 메모리를 사용하는 것보다 훨씬 더 복잡하다. 근본적인 이유는 디스크에서 특정 주소를 지정(addressing)하는 방법과 메모리에서 특정 주소를 지정하는 방법이 다른덷, CPU와 외부 장치 간 속도에 차이가 있기 때문이다.
- 메모리는 바이트 단위로 직접 주소를 지정할 수 있지만, 디스크에 저장된 파일은 조각(block) 밀도에 따라 주소가 지정된다. 이때 조각 크기는 수 바이트에서 수십 킬로바이트까지 다를 수 있다.
- CPU와 디스크의 속도 차이가 너무 커서 디스크의 파일은 반드시 먼저 메모리에 저장한 후 메모리에서 바이트 단위로 파일 내용을 처리한다.
파일과 가상 메모리
- 가상 메모리의 목적은 모든 프로세스가 각자 독점적으로 메모리를 소유하고 있다고 생각하게 하는 것이다. 가상 메모리를 지원한느 시스템에서 기계 명령어는 가상 주소를 전달하지만, 가상 주소는 메모리에 도달하기 전에 실제 물리 메모리 주소로 변환된다.
- 파일은 개념적으로 연속된 디스크 공간에 저장되어 있다고 생각할 수 있으므로 이 공간을 프로세스 주소 공간에 직접 사상할 수 있다.
- 예를 들어 길이가 200바이트인 파일을 프로세스 주소 공간에 사상한 결과로 파일이 600~799 주소 범위에 위치하고 있다고 가정하면, 이 주소 공간에서 바이트 단위로 파일을 처리할 수 있다. 600~799 범위에 있는 주소 공간의 메모리를 직접 읽거나 쓰면 실제로는 디스크 파일을 사용하는 것이 되며, 마치 메모리를 직접 읽고 쓰는 것처럼 디스크의 파일을 사용할 수 있다.
마술사 운영 체제
- 이 모든 것은 운영 체제 덕분에 가능하다.
- mmap을 사용하더라도 여전히 실제로 디스크를 읽고 써야 하기는 하지만, 이 과정은 운영 체제가 진행한다. 또 가상 메모리를 경유하기 때문에 고수준 계층에 있는 사용자는 이 사실을 신경 쓰지 않아도 된다. 사용자 상태 프로그램은 일반 메모리를 읽고 쓰는 것처럼 디스크의 파일을 직접 읽고 쓸 수 있는 것처럼 ‘느껴진다’.
mmap 대 전통적인 read/write 함수
- read 함수를 사용하여 파일을 읽을 때는 데이터를 커널 상태에서 사용자 상태로 복사해야 한다. 반대로 write 함수를 사용할 때도 마찬가지도.
- mmap에는 이런 문제가 없는데, 디스크의 파일을 읽고 쓸 때는 시스템 호출과 데이터 복사가 주는 부담이 없기 때문이다.
- 그러나 mmap도 단점이 있다.
- 커널은 프로세스 주소 공간과 파일의 사상 관계를 유지하기 위해 특정 데이터 구조를 사용해야 하며, 성능에 부담을 가져온다.
- 페이지 누락 문제
- 커널마다 구현 방식이 다르기 때문에 mmap이 성능 면에서 항상 read/write 함수보다 더 낫다고 할 수는 없다.
큰 파일 처리
- mmap의 장점은 큰 파일을 다룰 때 발휘되는데, 여기에서 큰 파일이란 물리 메모리 용량을 초과할 정도의 파일을 의미한다.
- 전통적인 read/write 함수를 사용하면 파일을 조금씩 나누어 메모리에 적재해야 하며, 파일의 일부분에 대한 처리가 끝나면 다시 다음 부분에 대한 처리를 하는 방식을 사용해야 한다.
- 하지만 mmap을 사용하면 제한된 물리 메모리임에도 매우 큰 파일을 처리할 수 있다. 시스템이 어떻게 메모리를 이동시키는지 프로그래머는 신경 쓸 필요가 전혀 없으며, 가상 메모리가 대신해서 이를 처리한다.
- 이 방법이 전통적인 read/write 함수를 사용하는 방법보다 성능 면에서 우수하다고는 할 수 없다. 성능에 관심이 있다면 실제 응용 상황을 기반으로 테스트할 필요가 있다.
- mmap을 사용할 때 큰 파일을 처리할 때 주의할 점은 다음과 같다.
- 32비트 시스템은 프로세스의 주소 공간이 4GB에 불과하며, 그나마도 그중 일부는 운영 체제를 위해 예약되어 있다는 것이다.
- 64비트 시스템은 주소 공간 부족 문제를 걱정할 필요가 없다.
동적 링크 라이브러리와 공유 메모리
- 많은 프로세스가 하나의 파일을 참조하고 있으며, 더군다나 이 프로세스가 모두 읽기 전용(read-only) 방식으로 이 파일을 참조하는 경우가 있다고 가정해 보자. 이런 파일은 바로 동적 링크 라이브러리다.
- 많은 프로세스가 동일한 동적 링크 라이브러리에 의존하므로, mmap으로 해당 라이브러리를 사용하는 모든 프로세스의 주소 공간에 직접 사상할 수 있다. 이때 각각의 프로세스는 모두 해당 라이브러리가 자신의 주소 공간에 적재되었다고 생각하지만, 실제 물리 메모리에서 이 라이브러리가 차지하는 공간은 한 개 크기일 뿐이다.
Section 6.6 컴퓨터 시스템의 각 부분에서 얼만큼 지연이 일어날까?
- 캐시와 메모리 관련 항목을 살펴보자. L2 캐시 접근 시간은 L1 캐시 접근 시간에 비해 14배나 길고, 메모리 접근 시간은 L2 캐시 접근 시간보다 20배, L1 캐시 접근 시간보다 200배 더 길다. 이 통계는 CPU 속도에 비해 메모리 접근이 매우 느리다는 사실을 알려 주며, 이것이 바로 CPU와 메모리 사이에 캐시 계층이 추가된 이유다.
- 분기 예측 실패에 대한 대가를 살펴보자. 분기 예측 실패에 따른 대가는 몇 ns 수준임을 알 수 있다.
- 동일한 1MB 데이터를 순차적으로 읽을 때(sequential read) 걸리는 시간은 메모리의 경우 250,000ns, SSD는 1,000,000ns, 디스크는 20,000,000ns이다. 즉, 디스크가 처리하는 시간은 SSD보다 20배, 메모리보다 80배 오래 걸리고, SSD는 메모리보다 네 배 더 오래 걸리는 것을 알 수 있다. 디스크를 순차적으로 읽는 속도는 생각만큼 그렇게 느리지 않다.
- 하지만 디스크 탐색 시간은 수 ms 단위로 매우 오래 걸린다. 디스크를 임의로 읽을 때(random read) 디스크 탐색이 발생할 가능성이 높으므로, 많은 고성능 데이터베이스는 ‘추가(append)’ 방식을 채택하고 있다. 다시 말해 순차 기록 방식으로 디스크에 데이터를 기록한다.